Downloaded 94 times












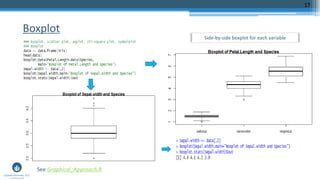
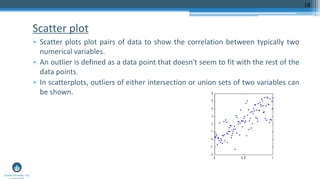
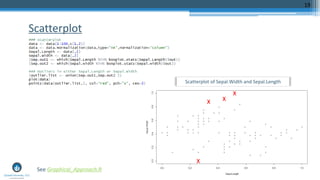



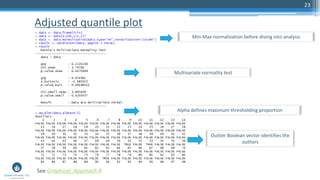
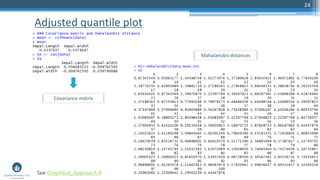
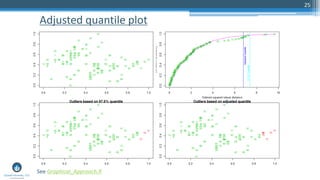


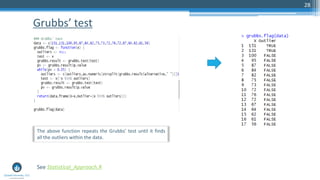
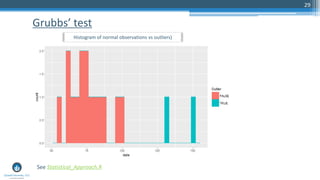

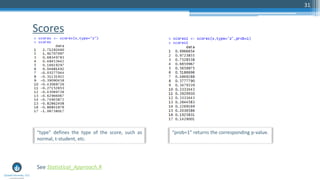
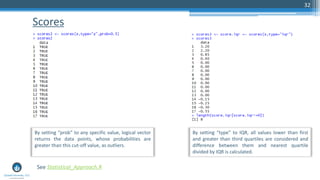



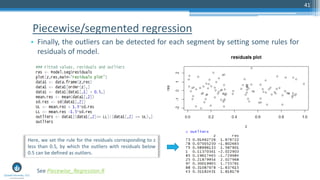


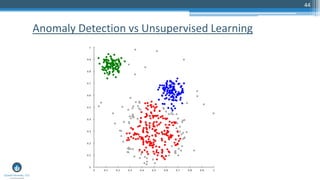
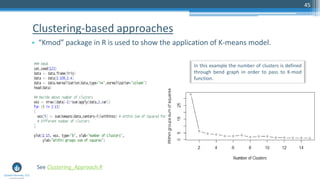
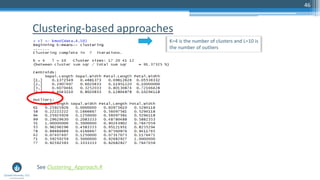





The document outlines a meetup focusing on anomaly detection techniques presented by Sri Krishnamurthy, founder of Quantuniversity LLC, detailing various methods including graphical, statistical, and machine learning approaches. It emphasizes the importance of identifying outliers in large datasets across fields such as finance and energy, along with key upcoming events and training programs from Quantuniversity. Additional resources and examples illustrate methodologies like boxplots, statistical testing, and clustering for detecting anomalies.









































































































