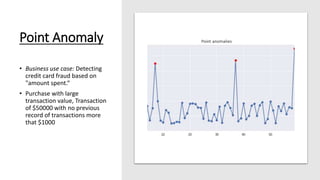
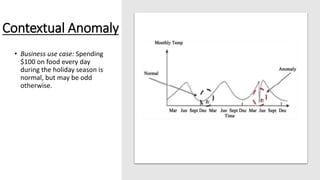
The document discusses outlier analysis and anomaly detection, defining outliers as observations that deviate significantly from others and introducing various types of anomalies, including point, contextual, and collective anomalies. It elaborates on methodologies for anomaly detection using graphical, statistical, and machine learning approaches, along with practical business use cases such as fraud detection and intrusion detection. Additionally, it highlights the importance of detecting anomalies for various applications and the challenges of identifying fraudulent transactions amidst rare events.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




