Downloaded 179 times















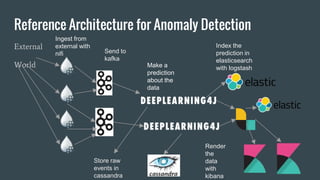



This document discusses anomaly detection in deep learning. It begins by defining what an anomaly is, such as abnormal patterns in data for fraud detection. It then discusses techniques for anomaly detection using unsupervised autoencoders and supervised recurrent neural networks. Finally, it provides an example reference architecture for an anomaly detection pipeline that ingests data from external sources using NiFi, sends it to Kafka, makes predictions using deep learning models, indexes predictions in Elasticsearch using Logstash, and renders the data in Kibana.











































































































