Downloaded 29 times



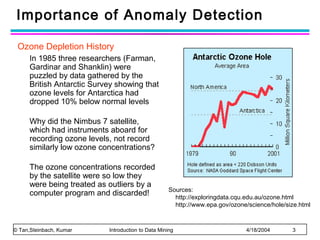

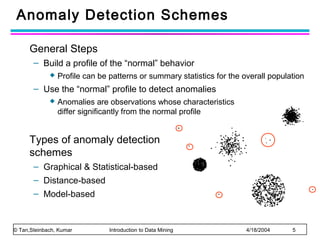
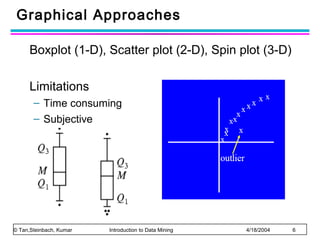
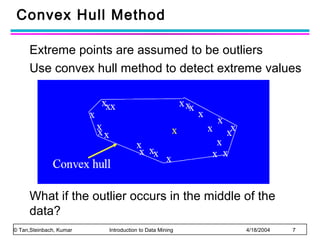








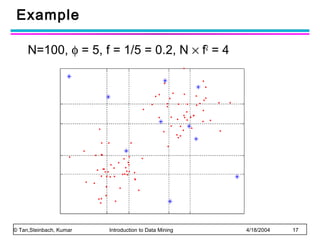

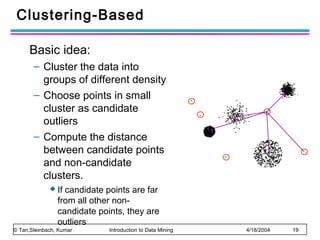
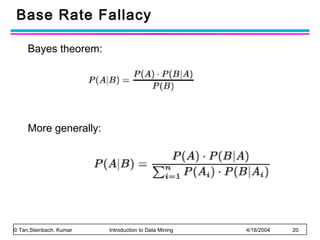




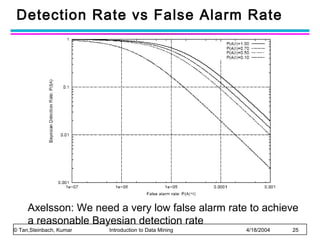

The document discusses anomaly detection and outlier detection techniques in data mining. It defines anomalies and outliers as data points that are considerably different from most of the data. It describes different types of anomaly detection problems and some applications. It then covers challenges in anomaly detection and provides an overview of different anomaly detection schemes, including graphical/statistical approaches, distance-based approaches, and model-based approaches. Key distance-based approaches discussed are nearest-neighbor, density-based, and clustering-based methods. The document also discusses the base rate fallacy problem in anomaly detection.






























































































