Downloaded 160 times









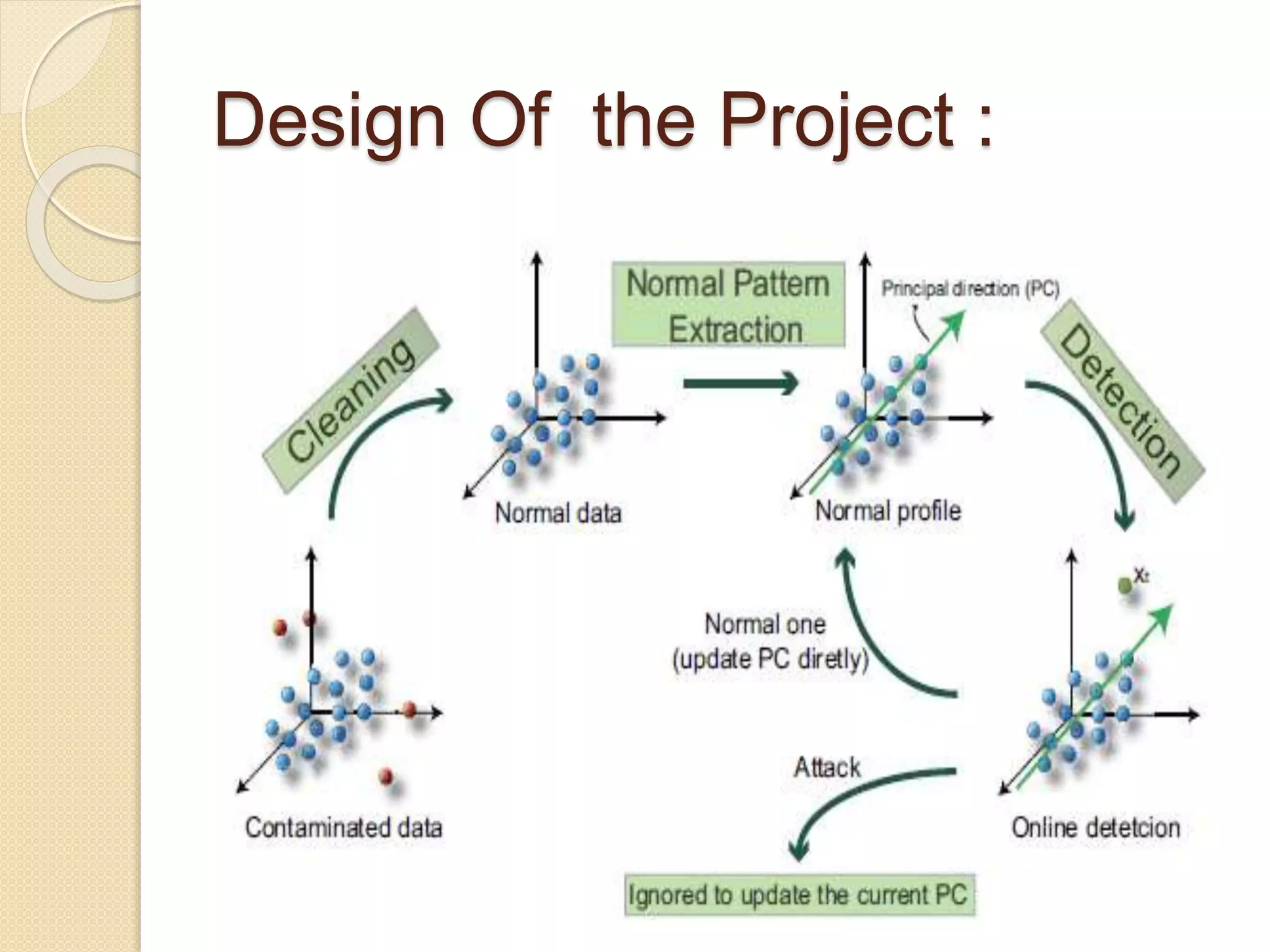




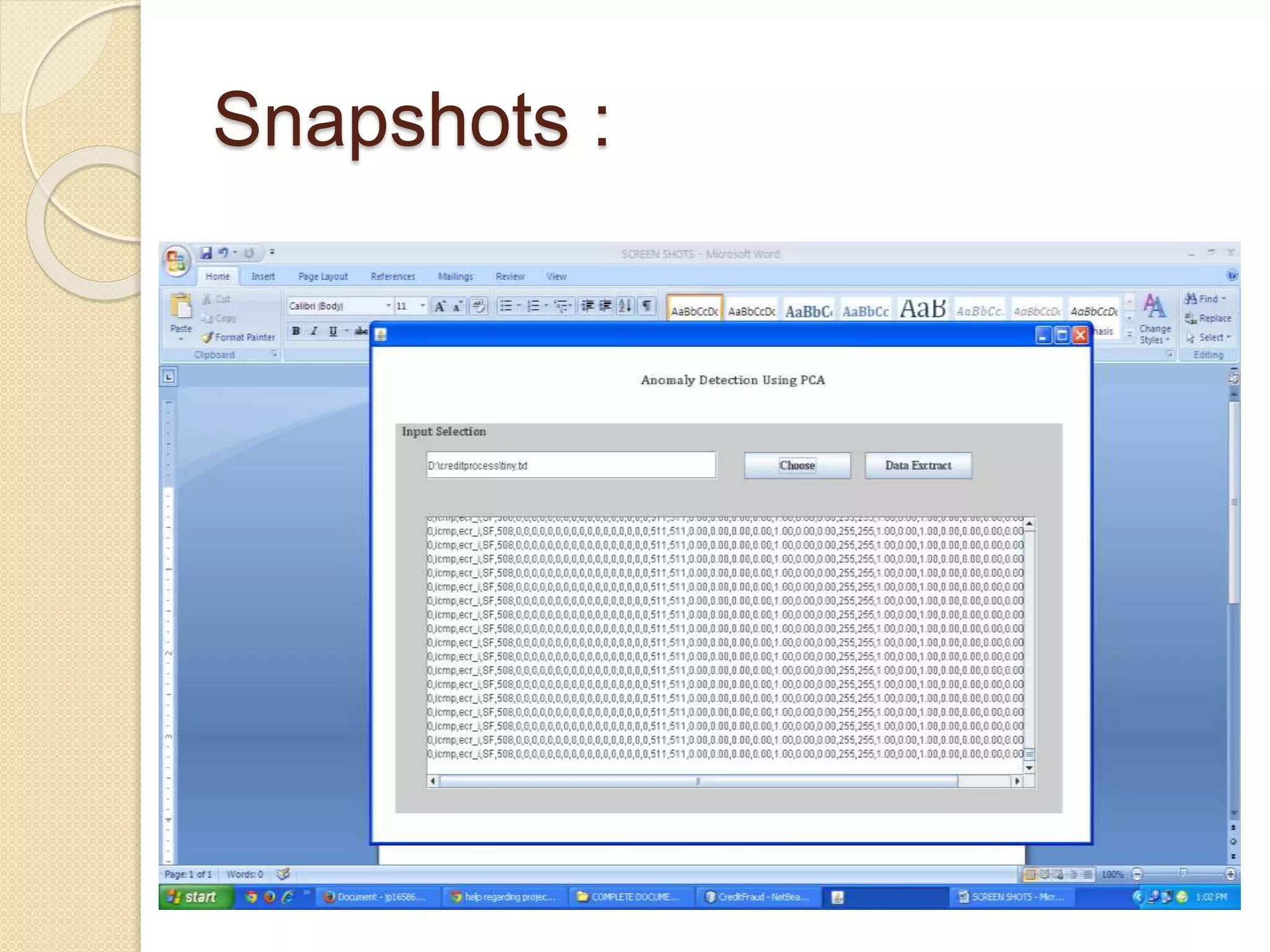
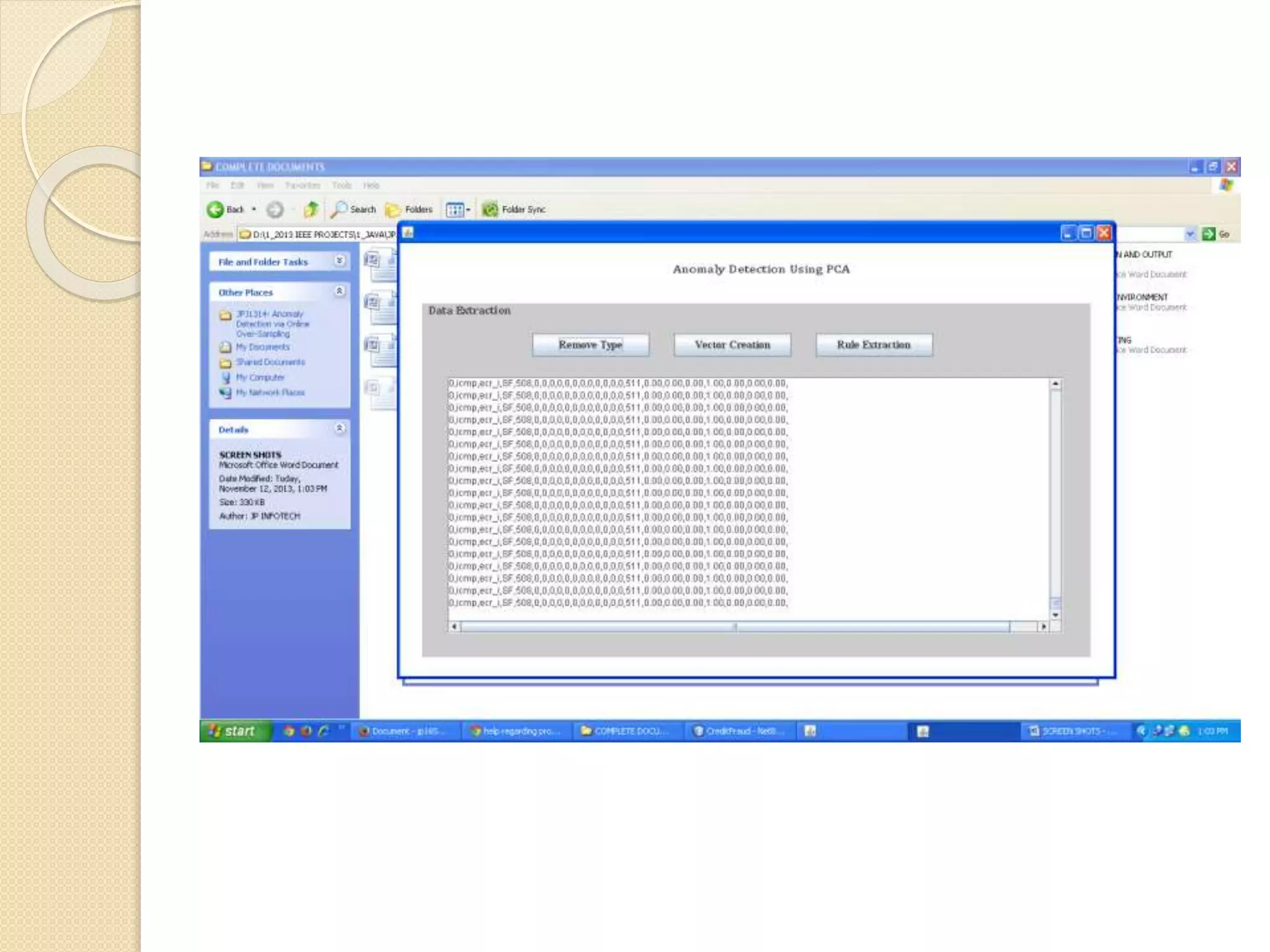
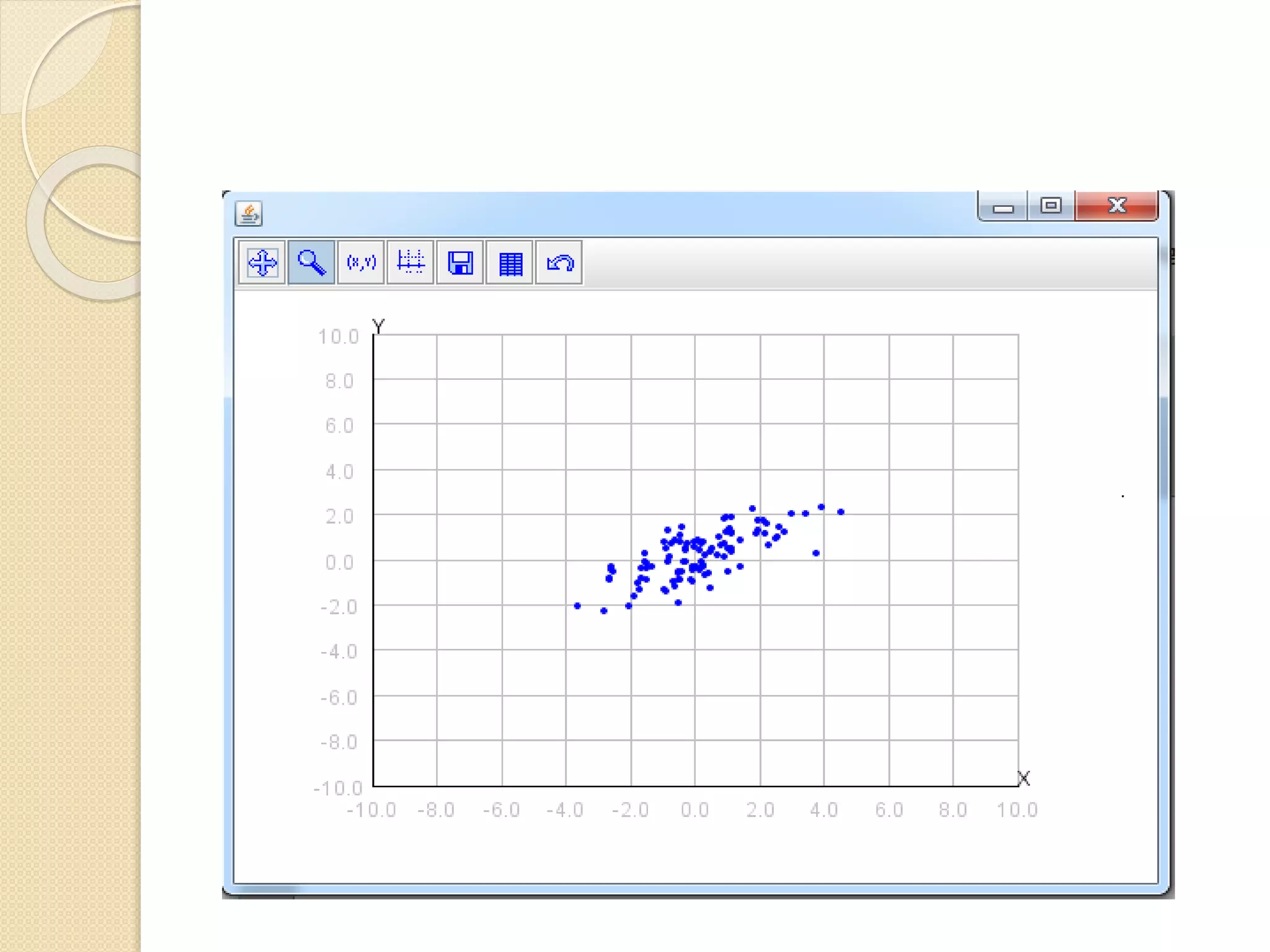





This document describes an online over-sampling principal component analysis (osPCA) algorithm for detecting outliers in large datasets. Unlike prior PCA approaches, osPCA does not store the entire data matrix or covariance matrix, making it suitable for online or large-scale problems. It works by duplicating potential outlier instances instead of removing them to amplify their effect on the principal components. This allows osPCA to identify outliers by observing variations in the principal directions with and without each data point. The approach can also detect new outliers in an online setting by quickly updating the principal directions for new data.