Download as PDF, PPTX


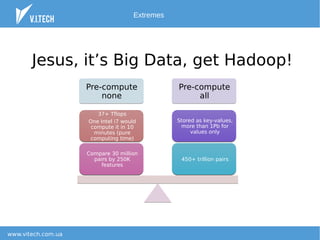



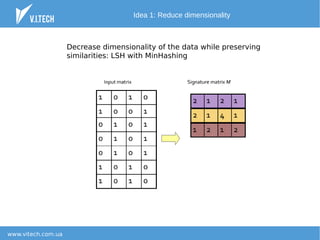












The document outlines a strategy for finding the most similar patients from a large database of 30 million patients with 250k features each. It suggests utilizing dimensionality reduction techniques, such as minhashing, and clustering methods to optimize similarity searches, achieving quick results on standard hardware. Future applications of this method include care gap detection, risk management, and diagnosis recommendations.



































































