Downloaded 35 times


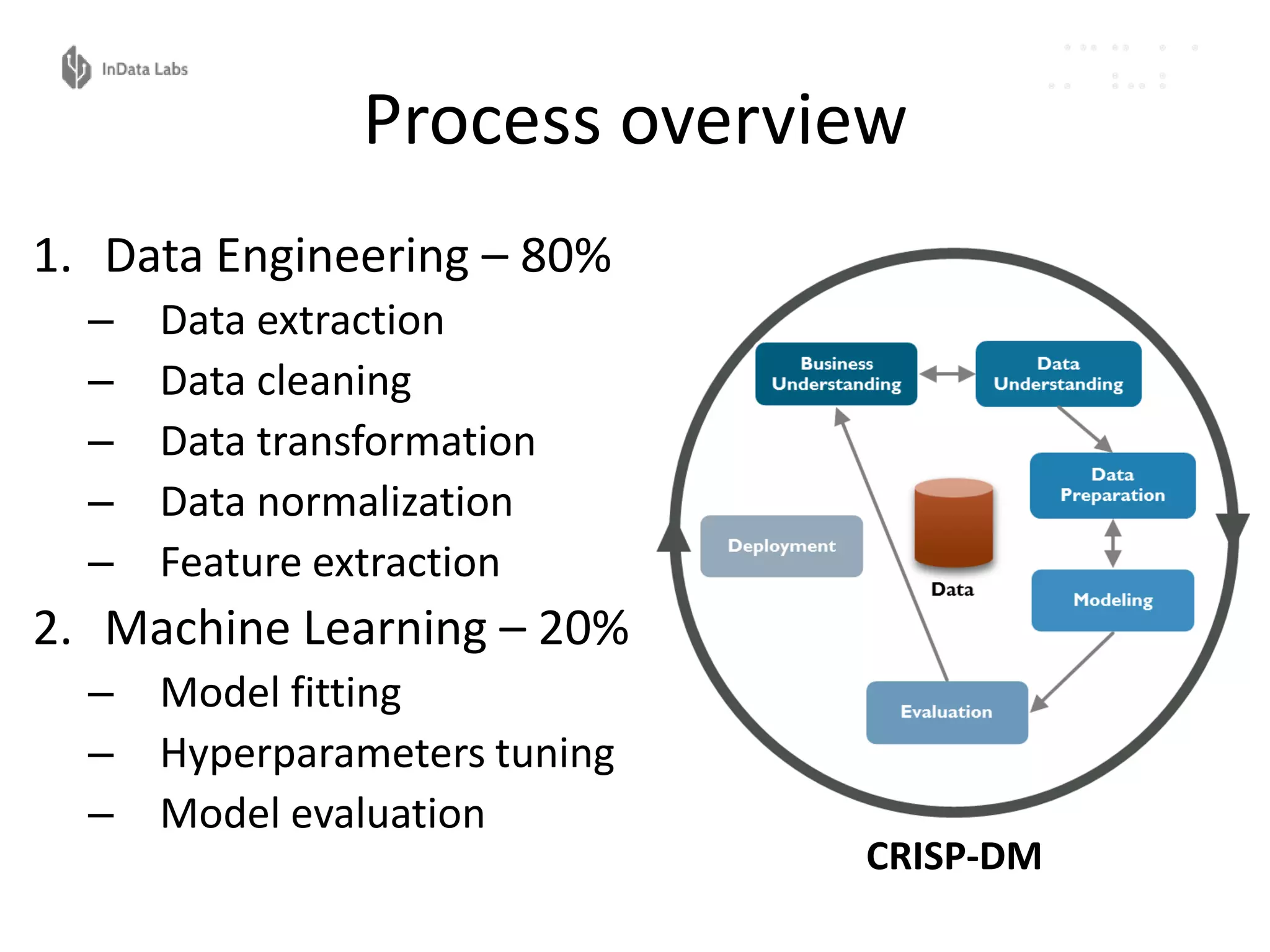


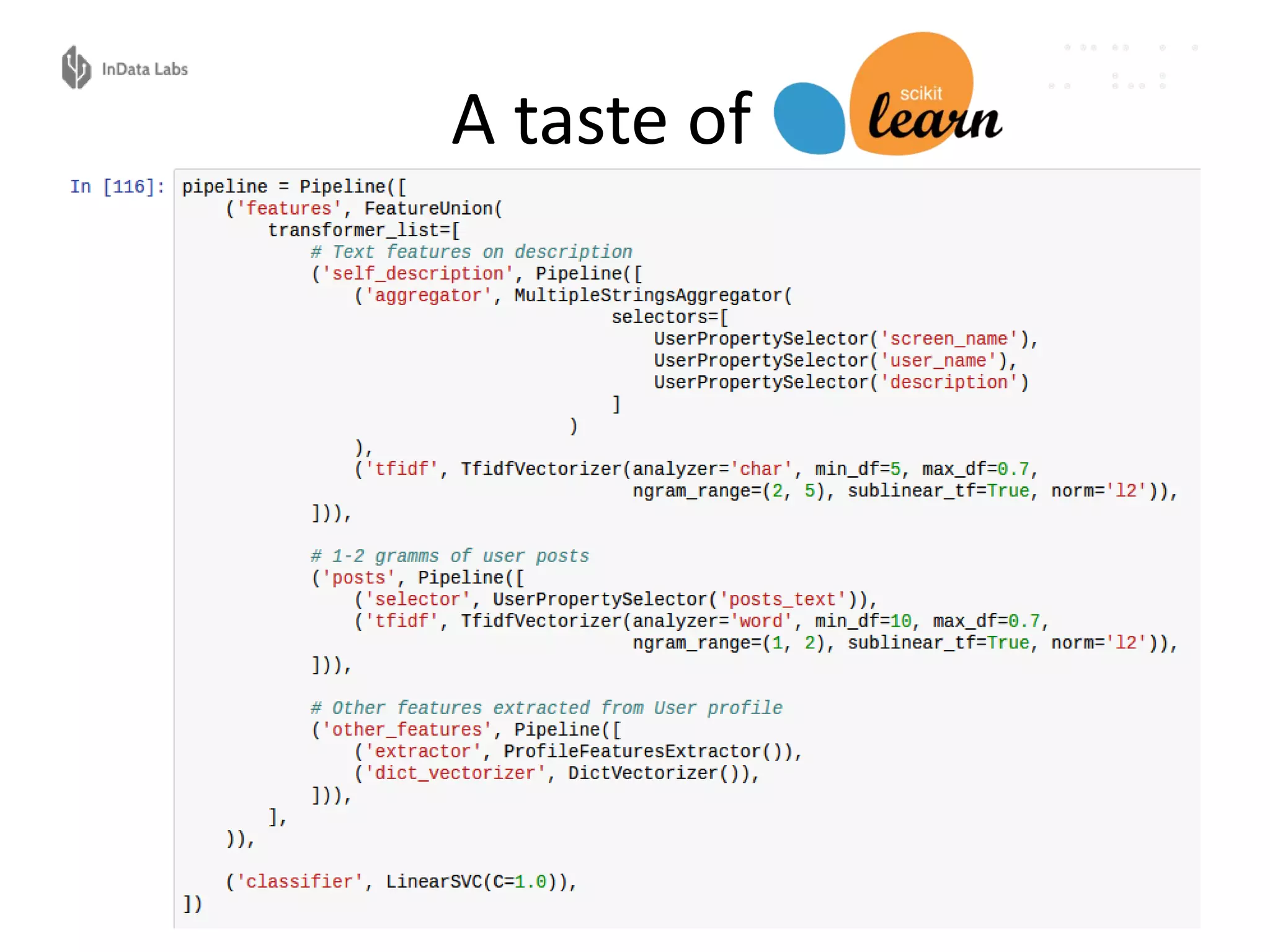










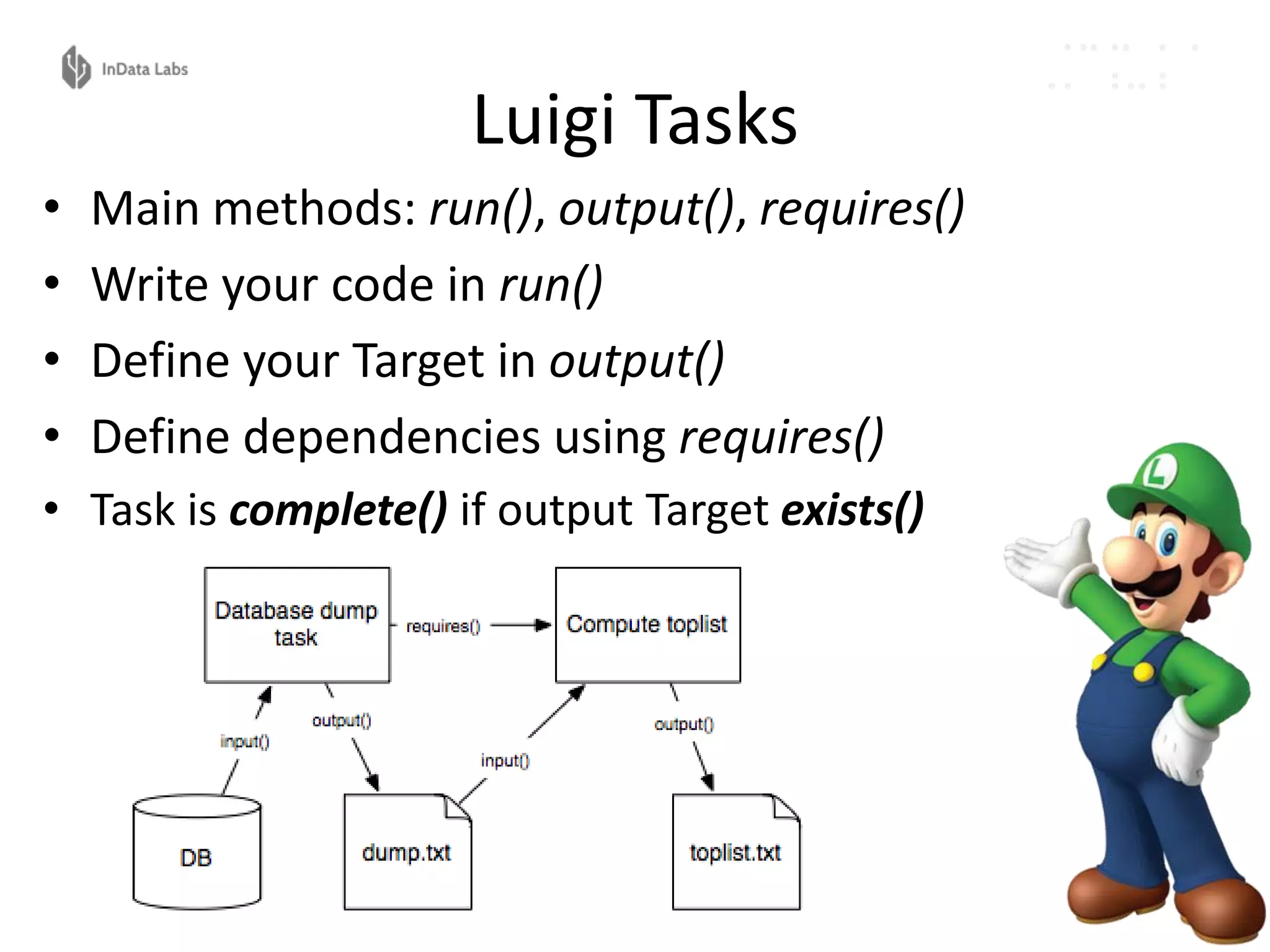










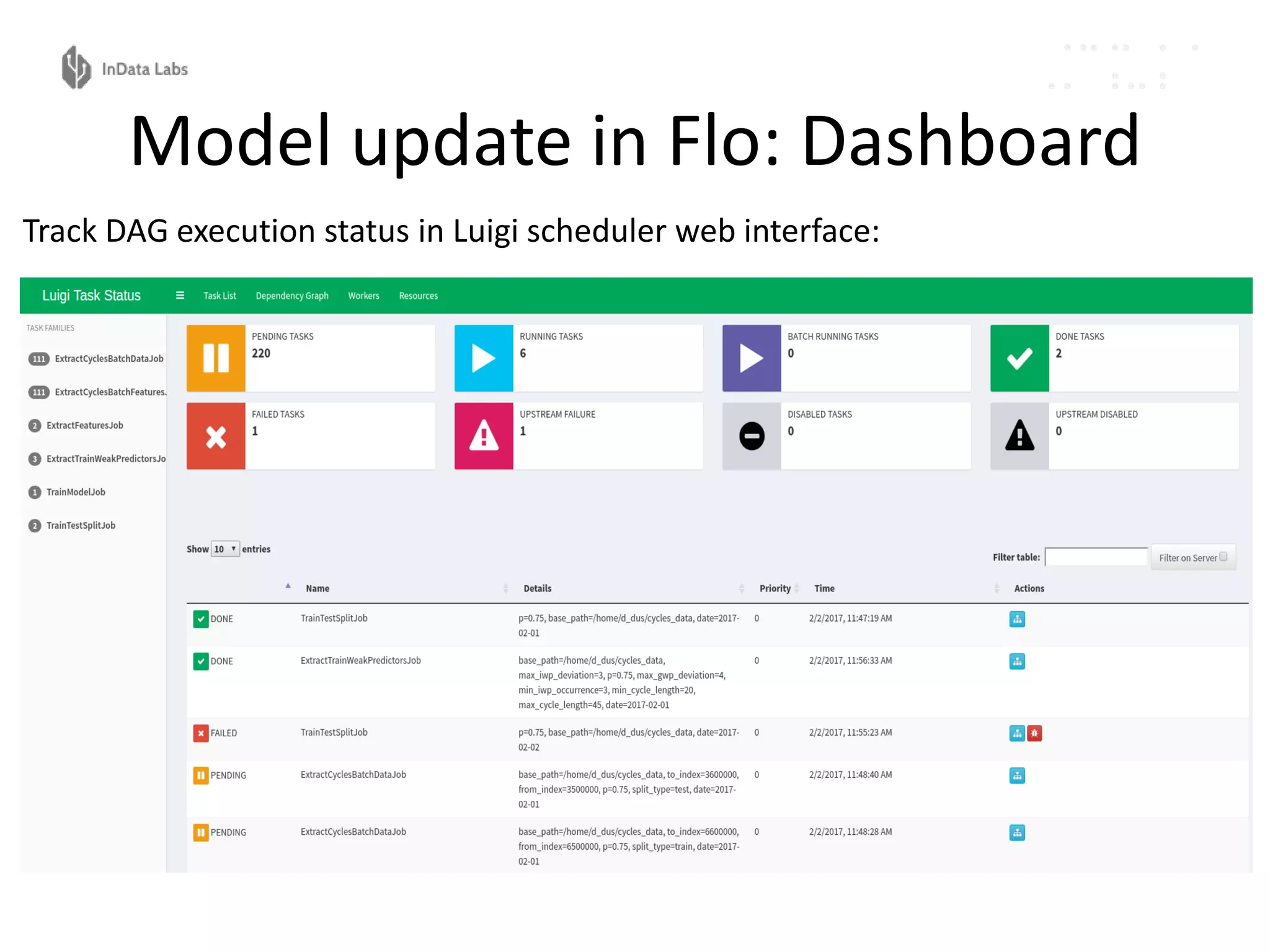
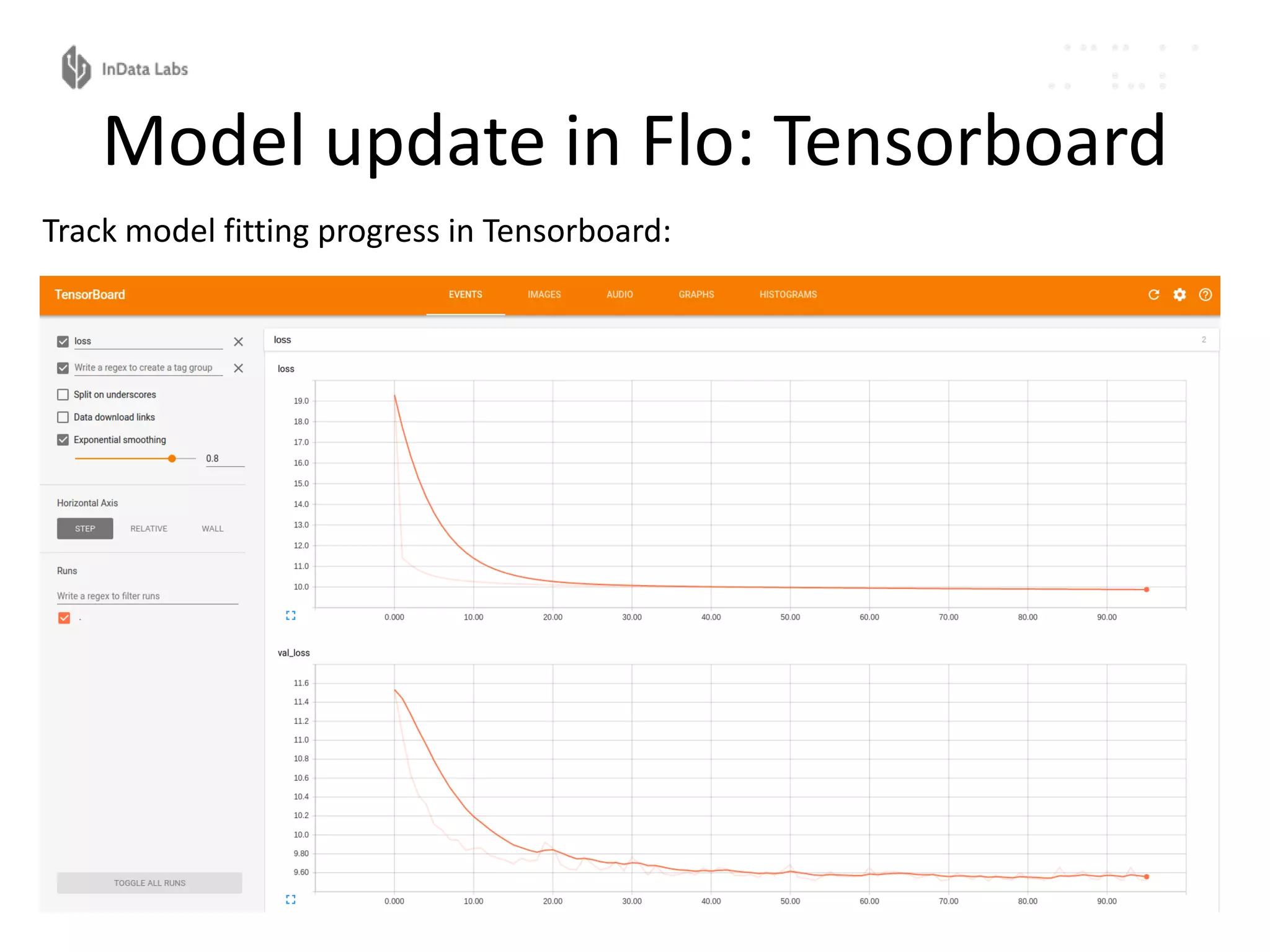




The document discusses the reproducibility and automation of the machine learning process, focusing on data mining, workflow automation, and design concepts. It emphasizes the importance of automating tasks in machine learning for regular model updates and trustable data workflows, highlighting tools like Luigi, Airflow, and Pinball for task orchestration. The conclusion stresses designing and realizing solid processes and environments for efficient and reliable machine learning experiments.




























































