Downloaded 12 times



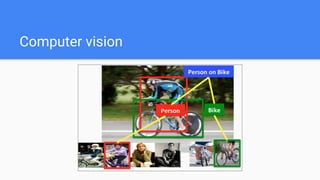

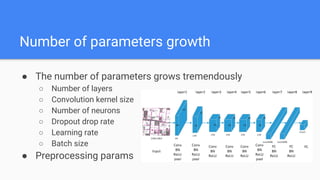







![Grid Search
1. Define a search space
2. Try all 4*3=12
configurations
Search space for SVM Classifier
{
'C': [1, 10, 100, 1000],
'gamma': [1e-2, 1e-3, 1e-4],
'kernel': ['rbf']
}](https://image.slidesharecdn.com/random-170526111052/85/DataScienceLab2017_-16-320.jpg)
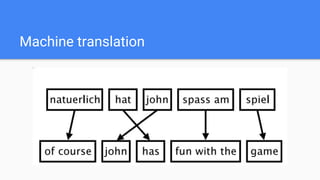
![Random Search
1. Define the search space
2. Sample the search space
and run ML algorithm
Search space for SVM Classifier
{
'C': scipy.stats.expon(scale=100),
'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf']
}](https://image.slidesharecdn.com/random-170526111052/85/DataScienceLab2017_-17-320.jpg)








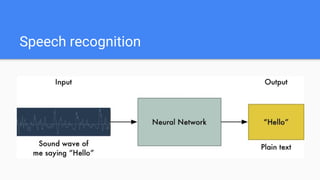
![● X - a search space
{
'C': [1, 1000],
'gamma': [0.0001, 0.1],
'kernel': ['rbf'],
}
Background: Examples](https://image.slidesharecdn.com/random-170526111052/85/DataScienceLab2017_-27-320.jpg)


















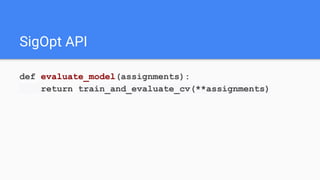
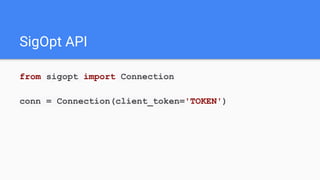
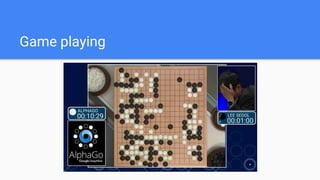
![experiment = conn.experiments().create(
name='Some Optimization (Python)',
parameters=[
dict(name='C', type='double', bounds=dict(min=0.0, max=1.0)),
dict(name='gamma', type='double', bounds=dict(min=0.0, max=1.0)),
],
)
SigOpt API](https://image.slidesharecdn.com/random-170526111052/85/DataScienceLab2017_-62-320.jpg)



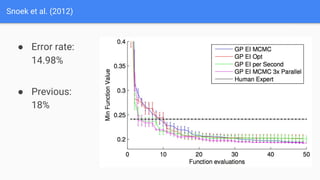

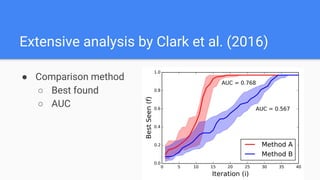

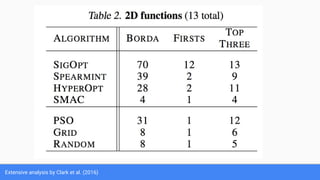
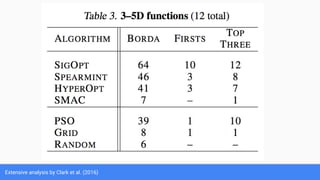
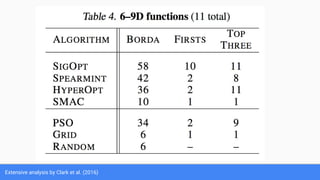
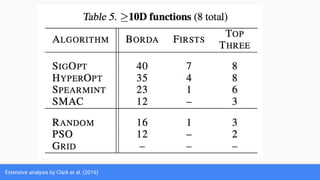


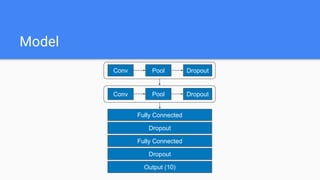




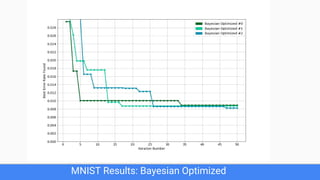
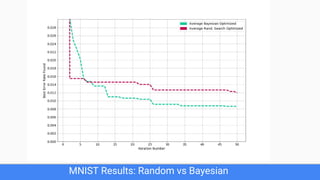
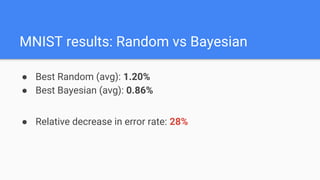





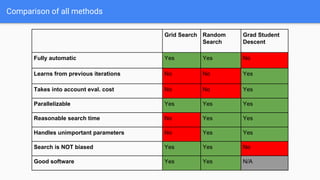
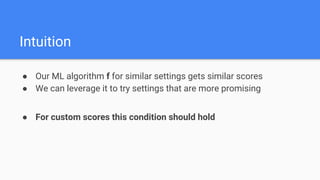
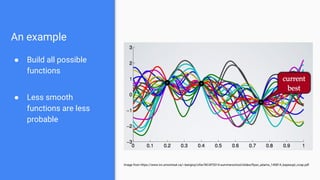
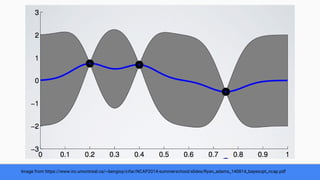
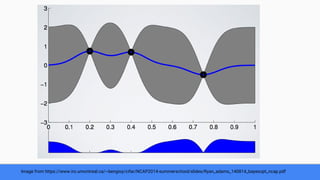
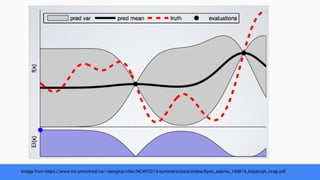
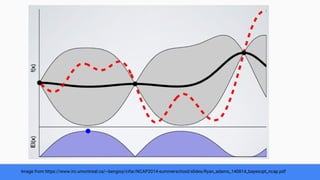
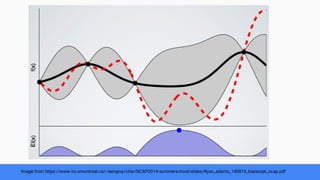
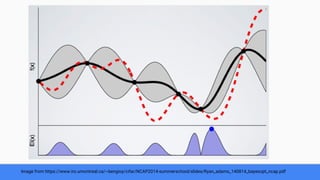
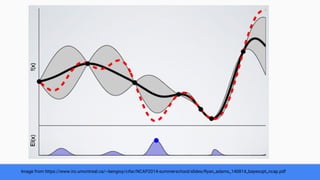
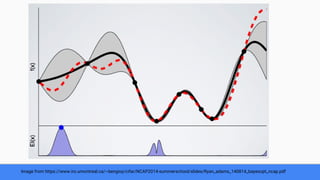
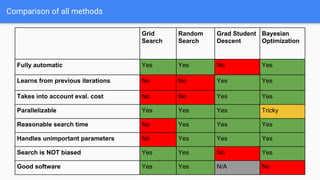
The document discusses Bayesian optimization for tuning machine learning hyper-parameters, highlighting its importance in achieving better algorithm performance. It compares various methodologies such as grid search, random search, and grad student descent, outlining their pros and cons. The author shares personal experiences and research findings to advocate for Bayesian optimization as a preferred method due to its capability of learning from past iterations and considering evaluation costs.



































































