Download as PDF, PPTX
















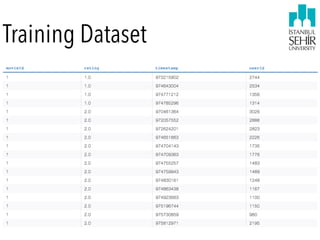

![Data Wrangling
>>> from pyspark.sql import SQLContext
>>> sqlContext = SQLContext(sc)
>>> from pyspark.ml.recommendation import ALS
>>> from pyspark.sql import Row
>>> parts = rdd.map(lambda row: row.split("::"))
>>> ratingsRDD = parts.map(lambda p:
Row(userId=int(p[0]),movieId=int(p[1]),
rating=float(p[2]), timestamp=long(p[3])))
>>> ratings = sqlContext.createDataFrame(ratingsRDD)
>>> (training, test) = ratings.randomSplit([0.8, 0.2])](https://image.slidesharecdn.com/sparkml-180821182842/85/Nose-Dive-into-Apache-Spark-ML-23-320.jpg)
![Data Wrangling
We will use 80% of our
dataset for training, and
20% for testing.
>>> from pyspark.sql import SQLContext
>>> sqlContext = SQLContext(sc)
>>> from pyspark.ml.recommendation import ALS
>>> from pyspark.sql import Row
>>> parts = rdd.map(lambda row: row.split("::"))
>>> ratingsRDD = parts.map(lambda p:
Row(userId=int(p[0]),movieId=int(p[1]),
rating=float(p[2]), timestamp=long(p[3])))
>>> ratings = sqlContext.createDataFrame(ratingsRDD)
>>> (training, test) = ratings.randomSplit([0.8, 0.2])](https://image.slidesharecdn.com/sparkml-180821182842/85/Nose-Dive-into-Apache-Spark-ML-24-320.jpg)




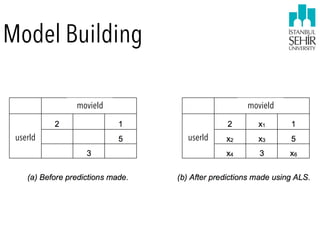
![Estimation Error
>>> from math import sqrt
>>> from pyspark.sql.functions import sum, isnan
>>> predictions = model.transform(test)
>>> df1 = predictions
.select(((predictions.prediction - predictions.rating)**2).alias("error"))
>>> df1 = df1.filter(~isnan(df1.error))
>>> print "RMSE:", sqrt(df1
.select(sum("error").alias("error")).collect()[0].error / df1.count())](https://image.slidesharecdn.com/sparkml-180821182842/85/Nose-Dive-into-Apache-Spark-ML-29-320.jpg)

This document discusses Apache Spark machine learning (ML) workflows for recommendation systems using collaborative filtering. It describes loading rating data from users on items into a DataFrame and splitting it into training and test sets. An ALS model is fit on the training data and used to make predictions on the test set. The root mean squared error is calculated to evaluate prediction accuracy.




































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















