Download to read offline










![tokenizer
apache spark 1
hadoop mapreduce 0
spark machine learning 1
[apache, spark] 1
[hadoop, mapreduce] 0
[spark, machine, learning] 1](https://image.slidesharecdn.com/odessasparkmllibserving-170514211843-170529092302/85/DataScienceLab2017_C-Apache-Spark_-13-320.jpg)
![hashing tf
[apache, spark] 1
[hadoop, mapreduce] 0
[spark, machine, learning] 1
[105, 495], [1.0, 1.0] 1
[6, 638, 655], [1.0, 1.0, 1.0] 0
[105, 72, 852], [1.0, 1.0, 1.0] 1](https://image.slidesharecdn.com/odessasparkmllibserving-170514211843-170529092302/85/DataScienceLab2017_C-Apache-Spark_-14-320.jpg)
![logistic regression
[105, 495], [1.0, 1.0] 1
[6, 638, 655], [1.0, 1.0, 1.0] 0
[105, 72, 852], [1.0, 1.0, 1.0] 1
0 72 -2.7138781446090308
0 94 0.9042505436914775
0 105 3.0835670890496645
0 495 3.2071722417080766
0 722 0.9042505436914775](https://image.slidesharecdn.com/odessasparkmllibserving-170514211843-170529092302/85/DataScienceLab2017_C-Apache-Spark_-15-320.jpg)

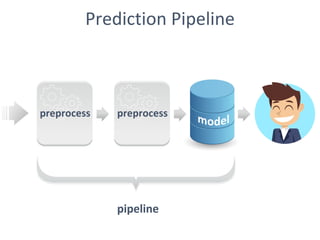


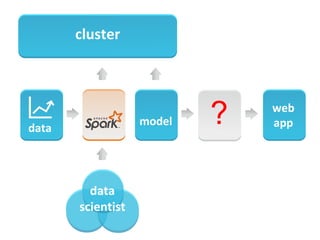
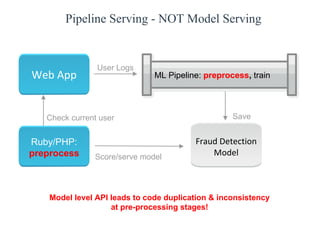

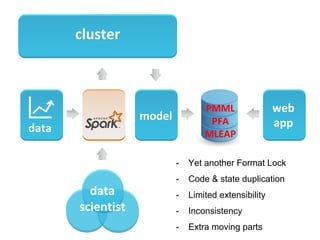
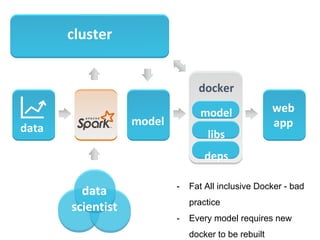
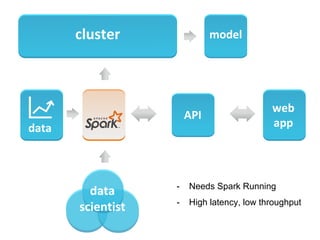
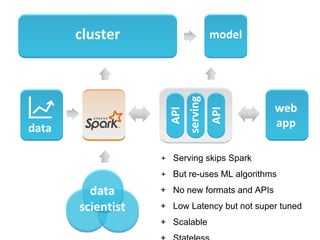

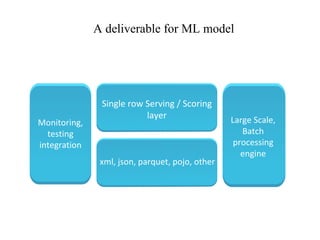
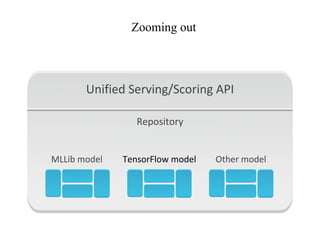
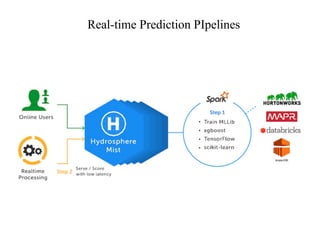




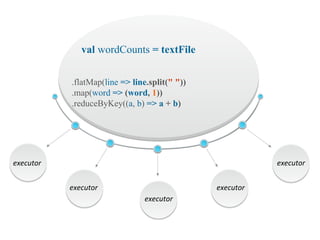
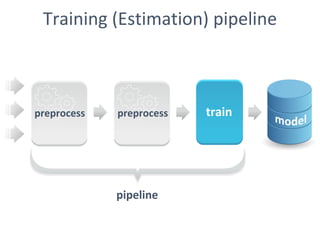
The document discusses the role of data scientists and data engineers in creating smarter products, focusing on various deliverables like machine learning models, scripts, and dashboards. It outlines the machine learning training and serving pipeline using Apache Spark and addresses challenges related to model serving, including code duplication and integration issues. The text also mentions the need for a unified serving/scoring API and invites feedback, advisors, and early adopters for collaboration.



















































































