Download as PDF, PPTX










![References
[1] Walisa Romsaiyud, Wichian Premchaiswadi, " An Adaptive Machine Learning on Map-
Reduce Framework for Improving performance of Large-Scale Data Analysis on EC ",
Eleventh IEEE Int'l Conf. on ICT and knowledge Engineering, 2014
[2] Domenico Talia," Clouds for Scalable Big Data Analytics ", IEEE Computer Society, 2013
[3] Feng Ye, Zhijan Wang , "Cloud-based Big Data Mining & Analyzing Services
Platform integrating R", IEEE International Conference on Advance Cloud and Big Data
, 2013
[4].DzApache-Hadoopdz-http://hadoop.apache.org/#What+Is+Apache+Hadoop%3F](https://image.slidesharecdn.com/2ndreview-141126043201-conversion-gate01/85/MACHINE-LEARNING-ON-MAPREDUCE-FRAMEWORK-13-320.jpg)


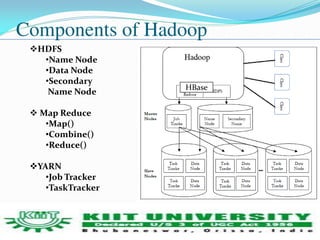
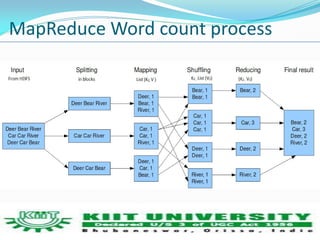
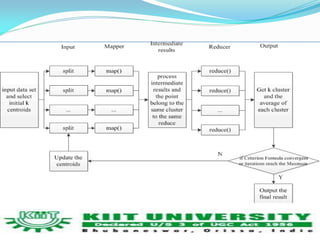
This document discusses using MapReduce and Apache Hadoop for large-scale data mining and analytics. It describes several Apache Hadoop projects like HDFS, MapReduce, HBase and Mahout. It discusses using Mahout for tasks like clustering, classification and recommendation. The document reviews literature on parallel K-means clustering with MapReduce and using clouds for scalable big data analytics. It outlines a plan to study parallel K-means clustering and implement a solution to handle large datasets.






















































































