Download as PDF, PPTX










![R training and conversion API
#library("caret")
library("gbm")
library("r2pmml")
cars = read.csv("cars.tsv", sep = "t", na.strings = "N/A")
factor_cols = c("category", "colour", "ac", "fuel_type", "gearbox", "interior_color", "interior_type")
for(factor_col in factor_cols){
cars[, factor_col] = as.factor(cars[, factor_col])
}
# Doesn't work with factors with missing values
#cars.gbm = train(price ~ ., data = cars, method = "gbm", na.action = na.pass, ..)
cars.gbm = gbm(price ~ ., data = cars, n.trees = 100, shrinkage = 0.1, interaction.depth = 6)
r2pmml(cars.gbm, "gbm.pmml")](https://image.slidesharecdn.com/rscikit-learnapachesparkml-whatdifferencedoesitmake-170322133417/85/R-Scikit-Learn-and-Apache-Spark-ML-What-difference-does-it-make-15-320.jpg)
![Scikit-Learn training and conversion API
from sklearn_pandas import DataFrameMapper
from sklearn.model_selection import GridSearchCV
from sklearn2pmml import sklearn2pmml, PMMLPipeline
cars = pandas.read_csv("cars.tsv", sep = "t", na_values = ["N/A", "NA"])
mapper = DataFrameMapper(..)
regressor = ..
tuner = GridSearchCV(regressor, param_grid = .., fit_params = ..)
tuner.fit(mapper.fit_transform(cars), cars["price"])
pipeline = PMMLPipeline([
("mapper", mapper),
("regressor", tuner.best_estimator_)
])
sklearn2pmml(pipeline, "pipeline.pmml", with_repr = True)](https://image.slidesharecdn.com/rscikit-learnapachesparkml-whatdifferencedoesitmake-170322133417/85/R-Scikit-Learn-and-Apache-Spark-ML-What-difference-does-it-make-16-320.jpg)
![LightGBM via Scikit-Learn
from sklearn_pandas import DataFrameMapper
from sklearn2pmml.preprocessing import PMMLLabelEncoder
from lightgbm import LGBMRegressor
mapper = DataFrameMapper(
[(factor_column, PMMLLabelEncoder()) for factor_column in factor_columns] +
[(continuous_columns, None)]
)
transformed_cars = mapper.fit_transform(cars)
regressor = LGBMRegressor(n_estimators = 100, learning_rate = 0.1, max_depth = 6, num_leaves = 64)
regressor.fit(transformed_cars, cars["price"],
categorical_feature = list(range(0, len(factor_columns))))](https://image.slidesharecdn.com/rscikit-learnapachesparkml-whatdifferencedoesitmake-170322133417/85/R-Scikit-Learn-and-Apache-Spark-ML-What-difference-does-it-make-18-320.jpg)
![XGBoost via Scikit-Learn
from sklearn_pandas import DataFrameMapper
from sklearn2pmml.preprocessing import PMMLLabelBinarizer
from xgboost.sklearn import XGBRegressor
mapper = DataFrameMapper(
[(factor_column, PMMLLabelBinarizer()) for factor_column in factor_columns] +
[(continuous_columns, None)]
)
transformed_cars = mapper.fit_transform(cars)
regressor = XGBRegressor(n_estimators = 100, learning_rate = 0.1, max_depth = 6)
regressor.fit(transformed_cars, cars["price"])](https://image.slidesharecdn.com/rscikit-learnapachesparkml-whatdifferencedoesitmake-170322133417/85/R-Scikit-Learn-and-Apache-Spark-ML-What-difference-does-it-make-19-320.jpg)





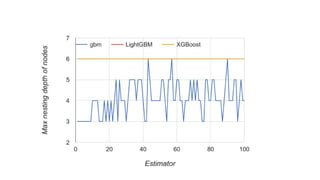
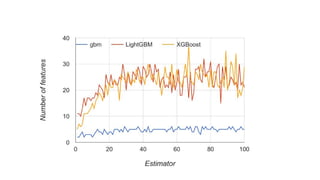
![LightGBM feature importances
Age 936
Mileage 887
Performance 738
[Category] 205
New? 179
[Type of fuel] 170
[Type of interior] 167
Airbags? 130
[Colour] 129
[Type of gearbox] 105](https://image.slidesharecdn.com/rscikit-learnapachesparkml-whatdifferencedoesitmake-170322133417/85/R-Scikit-Learn-and-Apache-Spark-ML-What-difference-does-it-make-30-320.jpg)

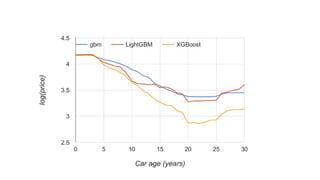
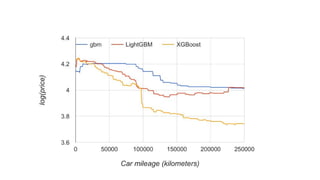



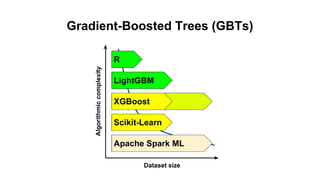
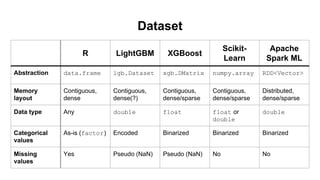
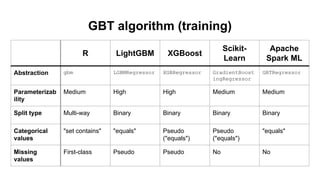
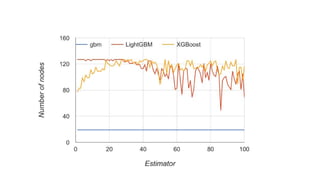
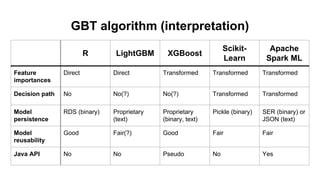
This document discusses different machine learning frameworks like R, Scikit-Learn, LightGBM, XGBoost, and Apache Spark ML and compares their capabilities for predictive modeling tasks. It highlights differences in how each framework handles data formats, parameter tuning, model serialization, and execution. It also presents a case study predicting car prices using gradient boosted trees in various frameworks and discusses lessons learned, emphasizing that ease-of-use and integration often outweigh raw performance.





























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)












