Download to read offline


















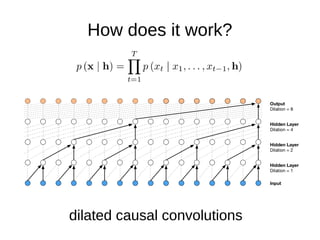
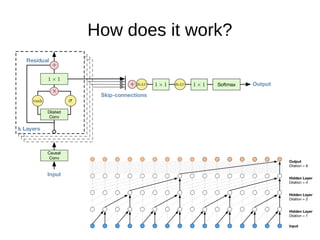
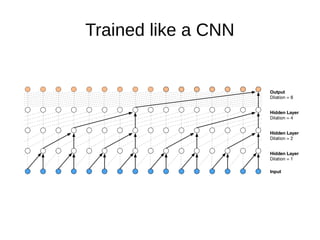
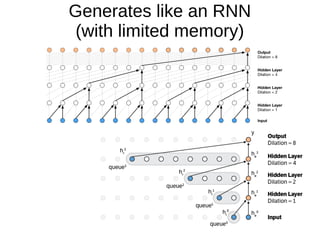


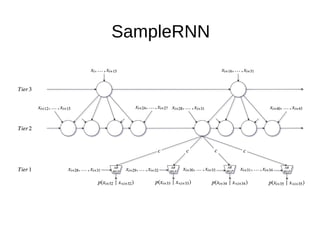
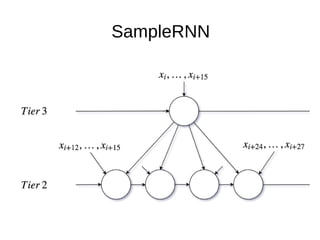
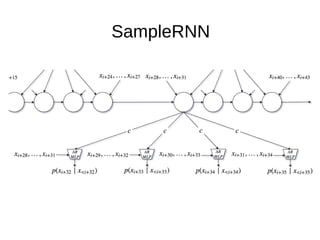




The document discusses sample-based generative models for speech synthesis, including techniques for splitting waveforms into frames, extracting features, and generating audio. Key models mentioned include WaveNet and SampleRNN, each with distinct advantages and disadvantages in terms of quality, generation speed, and memory usage. The document also references various research papers on these advanced synthesis methods.


















![[DSC Europe 24] Vladimir Platonov - Building next-gen speech synthesis for Bo...](https://cdn.slidesharecdn.com/ss_thumbnails/vladimirplatonov-speechsynthesis-241220211228-32267a46-thumbnail.jpg?width=640&height=640&fit=bounds)














































