More Related Content

PDF

PDF

PPTX
Sliced Wasserstein距離と生成モデル 
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) 
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング 
PPTX

PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた 
PDF
What's hot

PDF

PDF

PDF

PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に) ![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction ![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜 
PDF
(DL hacks輪読) Difference Target Propagation 
PDF

PDF

PDF

PDF

PDF

PDF
![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第15章 表現学習 
PDF

PPTX
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder 
PPTX

PDF
Similar to 強化学習その5

PDF

PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) 
PDF

PPTX

PDF

PPTX

PPTX
Reinforcement Learning(方策改善定理) 
PPTX

PDF

PDF
Inverse Reinforcement On POMDP 
PDF

DOCX

PPTX
データサイエンス勉強会~機械学習_強化学習による最適戦略の学習 
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course) ![[Oracle Code Night] Reinforcement Learning Demo Code](https://cdn.slidesharecdn.com/ss_thumbnails/20210831orajam7crypto-210921030945-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[Oracle Code Night] Reinforcement Learning Demo Code 
PPTX
【最新ではありません。再度URL送付しています→https://www.slideshare.net/ssuserf4860b/day-250965207... More from nishio

PDF

PDF

PPTX

PDF

PDF

PDF

PDF

PDF
Wifiにつながるデバイス(ESP8266EX, ESP-WROOM-02, ESPr Developerなど) 
PDF

PDF

PDF

PDF

PDF

PDF
首都大学東京「情報通信特別講義」2016年西尾担当分 
PDF

PDF

PDF

PDF
「ネットワークを作ることで�イノベーションを加速」�ってどういうこと? 
PDF

PDF
強化学習その5
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
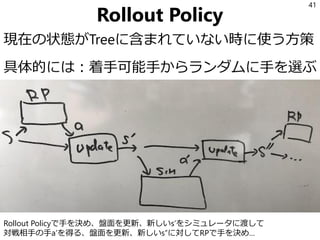
今後の予定
第8回 2.3 逆強化学習
第9回2.4 経験強化型学習
2.5 群強化学習(飛ばします)
第10回 2.6 リスク考慮型強化学習
2.7 複利型強化学習(飛ばします)
第11回
3 強化学習の工学応用
3.3 対話処理における強化学習
6
- 7.
- 8.
- 9.
- 10.
前回のおさらい
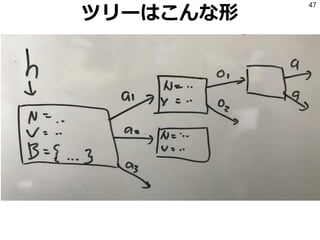
元のMDPがD次元ならbelief MDPの信念状態bは
𝑏 ∈ℝ 𝐷
になって大変
幸いbelief MDP上の価値関数Vは区分線形で下に
凸なので、D次元ベクトルの集合で効率的に表現
できる
しかし厳密に計算するとベクトルの数が指数的
オーダーで増える。そこで定数個のベクトルで近
似するのがPoint Based Value Iteration
この両者を実装して2状態3行動で実験した。
10
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
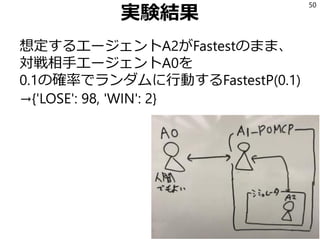
確率を変えて実験
Fastest→ {‘LOSE’: 95,‘WIN’: 5}
FastestP(0.1)→ {'LOSE': 98, 'WIN': 2}
FastestP(0.3)→ {‘LOSE’: 95, ‘WIN’: 5}
FastestP(0.5)→ {'LOSE': 92, 'WIN': 8}
FastestP(0.7)→ {'LOSE': 95, 'WIN': 5}
FastestP(0.9)→ {'LOSE': 90, 'WIN': 10}
Random→ {'LOSE': 88, 'WIN': 12}
ランダム戦略とFastest戦略のどんな比率での混合
に対してもPOMCPは9割以上の勝率
51
- 52.
- 53.
- 54.
- 55.
- 56.
まとめ
• Point BasedValue Iterationは状態遷移確率を与
える必要がある
• そこでブラックボックスシミュレータを使う
部分観測モンテカルロ計画法(POMCP)を実装
• ガイスターに適用して、ある確率で青コマで
のゴールを目指すような相手に対しては隠れ
状態を推定して9割近い勝率を出した
• もっと人間にとって自明でない思考ルーチン
で実験をしたい
56
- 57.
参考文献
David Silver andJoel Veness
"Monte-Carlo planning in large POMDPs."
Advances in neural information processing
systems. 2010.
57


![参考文献
2016年10月に左の本が出た。
これを読んでいく。
右下の本が長らくバイブル
だったが2000年(原著1998年)
発行。
3
http://amzn.to/2josIJ1
http://amzn.to/2jCnYQg言及する時 [こ] と呼ぶことにする(著者多いので)](https://image.slidesharecdn.com/5-170902005015/85/5-3-320.jpg)