The document discusses the fundamentals and applications of policy gradient reinforcement learning, focused on maximizing future rewards through a well-defined reward function. It details various algorithms and emphasizes the importance of techniques such as variance reduction in policy gradient methods. Additionally, it touches on the MDP (Markov Decision Process) structure used in reinforcement learning, including state and action spaces, reward functions, and value functions.

![3
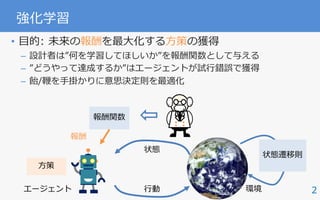
強化学習でできること
ngaging for human players. We used the same network
yperparameter values (see Extended Data Table 1) and
urethroughout—takinghigh-dimensionaldata(210|160
t 60 Hz) as input—to demonstrate that our approach
successful policies over a variety of games based solely
utswithonlyveryminimalpriorknowledge(thatis,merely
were visual images, and the number of actions available
but not their correspondences; see Methods). Notably,
as able to train large neural networks using a reinforce-
ignalandstochasticgradientdescentinastablemanner—
he temporal evolution of two indices of learning (the
e score-per-episode and average predicted Q-values; see
plementary Discussion for details).
We compared DQN with the best performing methods from the
reinforcement learning literature on the 49 games where results were
available12,15
. In addition to the learned agents, we alsoreport scores for
aprofessionalhumangamestesterplayingundercontrolledconditions
and a policy that selects actions uniformly at random (Extended Data
Table 2 and Fig. 3, denoted by 100% (human) and 0% (random) on y
axis; see Methods). Our DQN method outperforms the best existing
reinforcement learning methods on 43 of the games without incorpo-
rating any of the additional prior knowledge about Atari 2600 games
used by other approaches (for example, refs 12, 15). Furthermore, our
DQN agent performed at a level that was comparable to that of a pro-
fessionalhumangamestesteracrossthesetof49games,achievingmore
than75%ofthe humanscore onmorethanhalfofthegames(29 games;
Convolution Convolution Fully connected Fully connected
No input
matic illustration of the convolutional neural network. The
hitecture are explained in the Methods. The input to the neural
s of an 843 843 4 image produced by the preprocessing
by three convolutional layers (note: snaking blue line
symbolizes sliding of each filter across input image) and two fully connected
layers with a single output for each valid action. Each hidden layer is followed
by a rectifier nonlinearity (that is, max 0,xð Þ).
a b
c d
0
200
400
600
800
1,000
1,200
1,400
1,600
1,800
2,000
2,200
0 20 40 60 80 100 120 140 160 180 200
Averagescoreperepisode
Training epochs
8
9
10
11
lue(Q)
0
1,000
2,000
3,000
4,000
5,000
6,000
0 20 40 60 80 100 120 140 160 180 200
Averagescoreperepisode
Training epochs
7
8
9
10
alue(Q)
LETTER
ゲーム [Mnih+ 15]
IEEE ROBOTICS & AUTOMATION MAGAZINE MARCH 2016104
sampled from real systems. On the other hand, if the environ-
ment is extremely stochastic, a limited amount of previously
acquired data might not be able to capture the real environ-
ment’s property and could lead to inappropriate policy up-
dates. However, rigid dynamics models, such as a humanoid
robot model, do not usually include large stochasticity. There-
fore, our approach is suitable for a real robot learning for high-
dimensional systems like humanoid robots.
formance. We proposed recursively using the off-policy
PGPE method to improve the policies and applied our ap-
proach to cart-pole swing-up and basketball-shooting
tasks. In the former, we introduced a real-virtual hybrid
task environment composed of a motion controller and vir-
tually simulated cart-pole dynamics. By using the hybrid
environment, we can potentially design a wide variety of
different task environments. Note that complicated arm
movements of the humanoid robot need to be learned for
the cart-pole swing-up. Furthermore, by using our pro-
posed method, the challenging basketball-shooting task
was successfully accomplished.
Future work will develop a method based on a transfer
learning [28] approach to efficiently reuse the previous expe-
riences acquired in different target tasks.
Acknowledgment
This work was supported by MEXT KAKENHI Grant
23120004, MIC-SCOPE, ``Development of BMI Technolo-
gies for Clinical Application’’ carried out under SRPBS by
AMED, and NEDO. Part of this study was supported by JSPS
KAKENHI Grant 26730141. This work was also supported by
NSFC 61502339.
References
[1] A. G. Kupcsik, M. P. Deisenroth, J. Peters, and G. Neumann, “Data-effi-
cient contextual policy search for robot movement skills,” in Proc. National
Conf. Artificial Intelligence, 2013.
[2] C. E. Rasmussen and C. K. I. Williams Gaussian Processes for Machine
Learning. Cambridge, MA: MIT Press, 2006.
[3] C. G. Atkeson and S. Schaal, “Robot learning from demonstration,” in Proc.
14th Int. Conf. Machine Learning, 1997, pp. 12–20.
[4] C. G. Atkeson and J. Morimoto, “Nonparametric representation of poli-
cies and value functions: A trajectory-based approach,” in Proc. Neural Infor-
mation Processing Systems, 2002, pp. 1643–1650.Figure 13. The humanoid robot CB-i [7]. (Photo courtesy of ATR.)
ロボット制御 [Sugimoto+ 16]
IBM Research / Center for Business Optimization
Modeling and Optimization
Engine
Actions
Other
System 1
System 2
System 3
Event Listener
Event
Notification
Event
Notification
Event
Notification
< inserts >
TP Profile
Taxpayer State
( Current )
Modeler
Optimizer
< input to >
State Generator
< input to >
Case Inventory
< reads >
< input to >
Allocation Rules
Resource
Constraints
< input to >
< inserts , updates >
Business Rules
< input to >
< generates >
Segment Selector Action
1
Cnt Action
2
Cnt Action
n
Cnt
1 C
1
^ C
2
V C
3
200 50 0
2 C
4
V C
1
^ C
7
0 50 250
TP ID Feat
1
Feat
2
Feat
n
123456789 00 5 A 1500
122334456 01 0 G 1600
122118811 03 9 G 1700
Rule Processor
< input to >
< input to >
Recommended
Actions
< inserts , updates >
TP ID Rec. Date Rec. Action Start Date
123456789 00 6/21/2006 A1 6/21/2006
122334456 01 6/20/2006 A2 6/20/2006
122118811 03 5/31/2006 A2
Action Handler
< input to >
New
Case
Case Extract
Scheduler
< starts > < updates >
State
Time Expired
Event
Notification
< input to >
Taxpayer State
History
State
TP ID State Date Feat
1
Feat
2
Feat
n
123456789 00 6/1/2006 5 A 1500
122334456 01 5/31/2006 0 G 1600
122118811 03 4/16/2006 4 R 922
122118811 03 4/20/2006 9 G 1700
< inserts >
Feature Definitions
(XML)
(XSLT)
(XML)
(XML)
(XSLT)
Figure 2: Overall collections system architecture.
債権回収の最適化 [Abe+ 10]
囲碁 [Silver+ 16]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-3-320.jpg)
![5
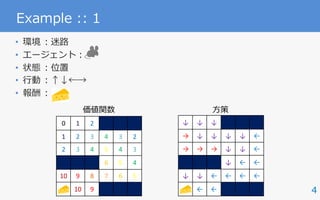
Example :: 2 :: Atari 2600
• 状態:ゲームのプレイ画⾯
• ⾏動:コントローラの操作
• 報酬:スコア
Convolution Convolution Fully connected Fully connected
No input
Figure 1 | Schematic illustration of the convolutional neural network. The symbolizes sliding of each filter across input image) and two fu
RESEARCH LETTER
[Mnih+ 15]
LETTER RESEARCH](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-5-320.jpg)
![6
Example :: 3 :: Basketball Shooting
• 状態:ロボットの関節⾓度(使ってない)
• ⾏動:関節⾓度の⽬標値
• 報酬:ゴールからの距離
dimensional dynamics models with a limited amount of data
sampled from real systems. On the other hand, if the environ-
ment is extremely stochastic, a limited amount of previously
acquired data might not be able to capture the real environ-
ment’s property and could lead to inappropriate policy up-
dates. However, rigid dynamics models, such as a humanoid
robot model, do not usually include large stochasticity. There-
fore, our approach is suitable for a real robot learning for high-
dimensional systems like humanoid robots.
es of a humanoid robot to eff
formance. We proposed recu
PGPE method to improve the
proach to cart-pole swing-u
tasks. In the former, we intr
task environment composed o
tually simulated cart-pole dy
environment, we can potenti
different task environments.
movements of the humanoid
the cart-pole swing-up. Furt
posed method, the challengi
was successfully accomplished
Future work will develop a
learning [28] approach to effici
riences acquired in different tar
Acknowledgment
This work was supported b
23120004, MIC-SCOPE, ``De
gies for Clinical Application’’
AMED, and NEDO. Part of thi
KAKENHI Grant 26730141. Th
NSFC 61502339.
References
[1] A. G. Kupcsik, M. P. Deisenroth, J.
cient contextual policy search for robo
Conf. Artificial Intelligence, 2013.
[2] C. E. Rasmussen and C. K. I. Will
Learning. Cambridge, MA: MIT Press, 2
[3] C. G. Atkeson and S. Schaal, “Robot
14th Int. Conf. Machine Learning, 1997, pp
[4] C. G. Atkeson and J. Morimoto, “N
cies and value functions: A trajectory-b
mation Processing Systems, 2002, pp. 164Figure 13. The humanoid robot CB-i [7]. (Photo courtesy of ATR.)
our proposed approach,
we compared the following methods:
● REINFORCE: The REINFORCE algorithm [25]
● PGPE: Standard PGPE [6]
● IW-PGPE: Standard IW-PGPE [34]
● Proposed: Proposed recursive IW-PGPE.
For each method, we updated the parameters every ten trials
and used the same learning rate.
2 m
(a)
0.9 m
0.5 m
0.5 m
0.1 m
y
z
x
Robot
i5, i6, i7
p(xp, yp, zp = 0.5) i1, i2, i3
i4
[Sugimoto+ 16]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-6-320.jpg)
![7
Example :: 4 :: Go
• 状態:盤⾯
• ⾏動:次に打つ⼿
• 報酬:勝敗
[Silver+ 16]
ARTICLE RESEARC
and architecture. a, A fast the current player wins) in positions from the self-play data set.
Regression
SelfPlay
radient
b
Self-play positions
NeuralnetworkData
p (a⎪s) (s′)p
RL policy network Value network Policy network Value network
s s′
phaGo than a value function ( )≈ ( )θ σv s v sp derived from the
etwork.
ng policy and value networks requires several orders of
more computation than traditional search heuristics. To
combine MCTS with deep neural networks, AlphaGo uses
onous multi-threaded search that executes simulations on
computes policy and value networks in parallel on GPUs.
ersion of AlphaGo used 40 search threads, 48 CPUs, and
e also implemented a distributed version of AlphaGo that
exploited multiple machines, 40 search thre
176 GPUs. The Methods section provides full d
and distributed MCTS.
Evaluating the playing strength of Alp
To evaluate AlphaGo, we ran an internal tourn
of AlphaGo and several other Go programs, i
commercial programs Crazy Stone13
and Zen,
source programs Pachi14
and Fuego15
. All of th
Principal variation
Value networka
fPolicy network Percentage of simulations
b c Tree evaluation from rolloutsTree evaluation from value net
d e g](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-7-320.jpg)
![8
内容
• ⽅策勾配型強化学習のざっくりとした説明
– ⽅策勾配の理論的な側⾯に着⽬
– 実際のアルゴリズムなどについてはほぼ触れない
– Variance Reduction も⾮常に重要だがパス
• 基礎:これをおさえればほぼ勝ち
– REINFORCE [Williams 92]
– ⽅策勾配定理 [Sutton+ 99]
• 応⽤:⽅策勾配定理からの様々な派⽣](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-8-320.jpg)

![10
Notation :: Markov Decision Process
• マルコフ決定過程 / MDP
• 状態・⾏動空間
• 状態遷移則
• 報酬関数
• 初期状態分布
• 割引率
• ⽅策
• 状態の分布
Agent
Environment
state actionreward
S, A
P : S ⇥ A ⇥ S ! R
R : S ⇥ A ! [ Rmax, Rmax]
⇢0 : S ! R
2 [0, 1)
(S, A, P, R, ⇢0, )
⇡ : S ⇥ A ! R or ⇡ : S ! A
⇢⇡
(s) =
1X
t=0
t
Pr (st = s|⇢0, ⇡)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-10-320.jpg)

![13
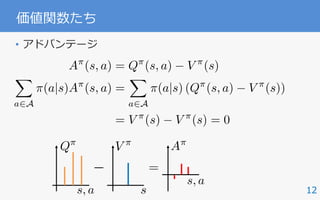
MDPを解く
• 強化学習の⽬的: 価値を最⼤化する最適⽅策の獲得
• MDPには最適価値関数 が⼀意に存在し,
少なくとも⼀つの最適な決定論的⽅策が存在する.
– greedy⽅策:常に価値が最⼤になる⾏動を選ぶ
V ⇤
(s), Q⇤
(s, a)
⇡⇤
2 arg max
⇡
⌘(⇡),
where ⌘(⇡) =
X
s2S
⇢0(s)V ⇡
(s) =
X
s2S,a2A
⇢⇡
(s)⇡(a|s)R(s, a)
= E⇡ [R(s, a)]
⇡⇤
(s) = arg maxa2AQ⇤
(s, a)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-13-320.jpg)
![14
Bellman ⽅程式
P(s0
|s, a)
P(s00
|s0
, a0
)
⇡(a|s)
⇡(a0
|s0
)
s
s0
a0
a
s00
V ⇡
(s) = E
" 1X
t=0
t
R(st, at) |s0 = s
#
= E [R(s, a) |s0 = s] + E
" 1X
t=0
t
R(st+1, at+1) |s0 = s
#
=
X
a2A
⇡(a|s)R(s, a) +
X
a2A
⇡(a|s)
X
s02S
P(s0
|s, a)E
" 1X
t=0
t
R(st+1, at+1) |s1 = s0
#
=
X
a2A
⇡(a|s)R(s, a) +
X
a2A
⇡(a|s)
X
s02S
P(s0
|s, a)V ⇡
(s0
)
=
X
a2A
⇡(a|s) R(s, a) +
X
s02S
P(s0
|s, a)V ⇡
(s0
)
!](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-14-320.jpg)


![17
近似価値反復 / Approximate Value Iteration
• 価値反復では毎更新ですべての状態・⾏動の組を評価
– 状態・⾏動空間が⼤きくなると計算量が指数関数的に爆発
• そもそも状態遷移確率と報酬関数は⼀般に未知
• 近似価値反復
– サンプル (s,a,sʼ,r) から近似的に価値反復
– Q学習 [Watkins 89] + greedy ⽅策
Q(s, a) (1 ↵)Q(s, a) + ↵
✓
R(s, a) + max
a02A
Q(s0
, a0
)
◆
⇡(s) = arg maxa2AQ(s, a)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-17-320.jpg)
![18
⽅策探索
• 強化学習の⽬的:
価値を最⼤化する最適⽅策の獲得
• ⽅策探索 / (direct) policy search
– ⽅策を陽に表現して直接最適化
– 連続な⾏動を扱いやすい
– ロボティクスへの応⽤が盛ん
IEEE ROBOTICS & AUTOMATION MAGAZINE MARCH 2016104
mensional systems like
humanoid robots, this
problem becomes more
serious due to the difficul-
ty of approximating high-
dimensional dynamics models with a limited amount of data
sampled from real systems. On the other hand, if the environ-
ment is extremely stochastic, a limited amount of previously
acquired data might not be able to capture the real environ-
ment’s property and could lead to inappropriate policy up-
dates. However, rigid dynamics models, such as a humanoid
robot model, do not usually include large stochasticity. There-
fore, our approach is suitable for a real robot learning for high-
dimensional systems like humanoid robots.
might be inter
work as a futur
Conclusions
In this article,
es of a human
formance. We
PGPE method
proach to car
tasks. In the f
task environm
tually simulate
environment,
different task
movements of
the cart-pole
posed method
was successful
Future wor
learning [28] a
riences acquire
Acknowledg
This work wa
23120004, MIC
gies for Clinic
AMED, and N
KAKENHI Gra
NSFC 6150233
References
[1] A. G. Kupcsik,
cient contextual po
Conf. Artificial Inte
[2] C. E. Rasmusse
Learning. Cambrid
[3] C. G. Atkeson a
14th Int. Conf. Mach
[4] C. G. Atkeson
cies and value func
mation Processing S
environments.
Figure 13. The humanoid robot CB-i [7]. (Photo courtesy of ATR.)
[Sugimoto+ 16]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-18-320.jpg)
![20
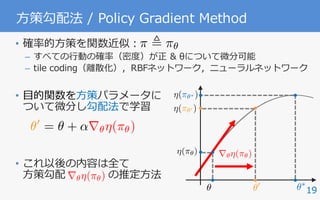
REINFORCE
• [Williams 92]
• REward Increment
= Nonnegative Factor x Offset Reinforcement
x Characteristic Eligibility
• 勾配を不偏推定
• b: ベースライン
• ⽅策勾配法の興り
• Alpha Goの⾃⼰対戦で⽤いられた
✓0
= ✓ + ↵ (r b) r✓ ln ⇡✓(a|s)
r✓⌘(⇡✓)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-20-320.jpg)
![21
REINFORCE :: 導出 :: 1
• を仮定(成り⽴つはずがない)
r✓⌘(⇡) = r✓E⇡ [R(s, a)]
= r✓
X
s2S,a2A
⇢⇡
(s)⇡✓(a|s)R(s, a)
'
X
s2S,a2A
⇢⇡
(s)r✓⇡✓(a|s)R(s, a)
=
X
s2S,a2A
⇢⇡
(s)⇡✓(a|s)
r✓⇡✓(a|s)
⇡✓(a|s)
R(s, a)
= E⇡ [r✓ ln ⇡✓(a|s)R(s, a)]
r✓⇢⇡
(s) = 0
(ln x)0
=
x0
x](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-21-320.jpg)
![22
REINFORCE :: 導出 :: 2
• ⾏動に⾮依存なベースライン b は以下を満たす:
• よって
r✓
X
s2S,a2A
⇢⇡
(s)⇡✓(a|s)b(s) =
X
s2S
⇢⇡
(s)b(s)r✓
X
a2A
⇡✓(a|s)
=
X
s2S
⇢⇡
(s)b(s)r✓1 = 0
r✓⌘(⇡) = E⇡ [r✓ ln ⇡✓(a|s)R(s, a)]
= E⇡ [r✓ ln ⇡✓(a|s) (R(s, a) b(s))]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-22-320.jpg)
![23
⽅策勾配定理 / Policy Gradient Theorem
• [Sutton+ 99]
• この定理を利⽤するのがいわゆる”⽅策勾配法”.
• 即時報酬ではなく,価値(未来の報酬の予測値)を
使って⽅策勾配を推定できる.
• [Baxter & Bartlett 01]も等価
r✓⌘(⇡) = E⇡ [r✓ ln ⇡✓(a|s)Q⇡
(s, a)]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-23-320.jpg)
![r✓V ⇡
(s) = r✓
X
a2A
⇡✓(a|s)Q⇡
(s, a)
=
X
a2A
[r✓⇡✓(a|s)Q⇡
(s, a) + ⇡✓(a|s)r✓Q⇡
(s, a)]
=
X
a2A
"
r✓⇡✓(a|s)Q⇡
(s, a) + ⇡✓(a|s)r✓ R(s, a) +
X
s02S
P(s0
|s, a)V ⇡
(s0
)
!#
=
X
a2A
"
r✓⇡✓(a|s)Q⇡
(s, a) + ⇡✓(a|s)
X
s02S
P(s0
|s, a)r✓
X
a02A
⇡✓(a0
|s0
)Q⇡
(s0
, a0
)
#
=
X
s02S
1X
t=0
t
Pr(st = s0
|s0 = s, ⇡)
X
a2A
r✓⇡✓(a|s0
)Q⇡
(s0
, a)
24
⽅策勾配定理 :: 導出 :: 1](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-24-320.jpg)
![25
⽅策勾配定理 :: 導出 :: 2
r✓⌘(⇡) =
X
s2S
1X
t=0
t
Pr(st = s|⇢0, ⇡)
X
a2A
r✓⇡✓(a|s)Q⇡
(s, a)
=
X
s2S
⇢⇡
(s)
X
a2A
r✓⇡✓(a|s)Q⇡
(s, a)
= E⇡ [r✓ ln ⇡✓(a|s)Q⇡
(s, a)]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-25-320.jpg)
![26
⽅策勾配定理
• ⽅策勾配は様々な形式で不偏推定できる:
r✓⌘(⇡) = E⇡ [r✓ ln ⇡✓(a|s)Q⇡
(s, a)]
= E⇡ [r✓ ln ⇡✓(a|s) (Q⇡
(s, a) V ⇡
(s))]
= E⇡ [r✓ ln ⇡✓(a|s)A⇡
(s, a)]
= E⇡ [r✓ ln ⇡✓(a|s) ⇡
]
=
s, a
Q⇡
s
V ⇡
A⇡
s, a
A⇡
(s, a) = Q⇡
(s, a) V ⇡
(s)
= R(s, a) +
X
s02S
P(s0
|s, a)V ⇡
(s0
) V ⇡
(s)
= Es0⇠P [r + V ⇡
(s0
) V ⇡
(s)] = Es0⇠P [ ⇡
]<latexit sha1_base64="JdGziPix+c0H39/n+OmPaMIjE1w=">AAAGaXiclVRLb9NAEB4HGkp4tCmXilwsoqStKNGm4i0hFRASxzxIWilOo7WzSaz4JdsJFJMLR/4AB04gIYE4wV/gwh/g0J+A4FYkLhwYr02TNM9uZO/M7HzffDOOVrY01XEJORAip04vRM8sno2dO3/h4tJyfKXsmB1bYSXF1Ex7V6YO01SDlVzV1diuZTOqyxrbkdsP/fOdLrMd1TSeuPsWq+q0aagNVaEuhmpxIXF/T7LUdWeTbsTS98T8kSdeE8uBsxGTJP9M0qnbUqjmFXpBxlVRalJdp6LkdPSa56xJqnGUVOz1+ogcItZecFB5z0NW359UQpa9Rz1O56j6AAXyaazhVux+4RA+RCXZarPlVmMppEylY3OSilKdaS4NxIUUteUkyRC+xFEjGxpJCFfOjEcSIEEdTFCgAzowMMBFWwMKDv4qkAUCFsaq4GHMRkvl5wx6EENsB7MYZlCMtvHdRK8SRg30fU6HoxWsouFjI1KEFPlOPpJD8o18Ij/I34lcHufwtezjLgdYZtWWXq0W/8xE6bi70Oqjpmp2oQG3uVYVtVs84nehBPju89eHxbuFlJcm78hP1P+WHJCv2IHR/a28z7PCmyl6ZNQSTKyOfoNXYAMz8fibYrTJZ+vPS8ee29wmsIlPBm7gnsU98AM+n+cpZ9J5vwZW8DA+zOd/ySqP+z094195cu0kZvdm6K3z/0MbO9Ow51HN2VDzTb7P1jvKN13zuPon0W1jvD5m0hnYGpry/Mr/M86nu19/UPWkGvNxn4xz3kmPmTDeNNnj98qoUdrK3MmQ/PXk9oPwylmEBFyBdSS5BdvwGHJQAkV4KXwQPgtfFn5FV6Kr0ctBakQIMZdgaEWT/wC35HkI</latexit><latexit sha1_base64="JdGziPix+c0H39/n+OmPaMIjE1w=">AAAGaXiclVRLb9NAEB4HGkp4tCmXilwsoqStKNGm4i0hFRASxzxIWilOo7WzSaz4JdsJFJMLR/4AB04gIYE4wV/gwh/g0J+A4FYkLhwYr02TNM9uZO/M7HzffDOOVrY01XEJORAip04vRM8sno2dO3/h4tJyfKXsmB1bYSXF1Ex7V6YO01SDlVzV1diuZTOqyxrbkdsP/fOdLrMd1TSeuPsWq+q0aagNVaEuhmpxIXF/T7LUdWeTbsTS98T8kSdeE8uBsxGTJP9M0qnbUqjmFXpBxlVRalJdp6LkdPSa56xJqnGUVOz1+ogcItZecFB5z0NW359UQpa9Rz1O56j6AAXyaazhVux+4RA+RCXZarPlVmMppEylY3OSilKdaS4NxIUUteUkyRC+xFEjGxpJCFfOjEcSIEEdTFCgAzowMMBFWwMKDv4qkAUCFsaq4GHMRkvl5wx6EENsB7MYZlCMtvHdRK8SRg30fU6HoxWsouFjI1KEFPlOPpJD8o18Ij/I34lcHufwtezjLgdYZtWWXq0W/8xE6bi70Oqjpmp2oQG3uVYVtVs84nehBPju89eHxbuFlJcm78hP1P+WHJCv2IHR/a28z7PCmyl6ZNQSTKyOfoNXYAMz8fibYrTJZ+vPS8ee29wmsIlPBm7gnsU98AM+n+cpZ9J5vwZW8DA+zOd/ySqP+z094195cu0kZvdm6K3z/0MbO9Ow51HN2VDzTb7P1jvKN13zuPon0W1jvD5m0hnYGpry/Mr/M86nu19/UPWkGvNxn4xz3kmPmTDeNNnj98qoUdrK3MmQ/PXk9oPwylmEBFyBdSS5BdvwGHJQAkV4KXwQPgtfFn5FV6Kr0ctBakQIMZdgaEWT/wC35HkI</latexit><latexit sha1_base64="JdGziPix+c0H39/n+OmPaMIjE1w=">AAAGaXiclVRLb9NAEB4HGkp4tCmXilwsoqStKNGm4i0hFRASxzxIWilOo7WzSaz4JdsJFJMLR/4AB04gIYE4wV/gwh/g0J+A4FYkLhwYr02TNM9uZO/M7HzffDOOVrY01XEJORAip04vRM8sno2dO3/h4tJyfKXsmB1bYSXF1Ex7V6YO01SDlVzV1diuZTOqyxrbkdsP/fOdLrMd1TSeuPsWq+q0aagNVaEuhmpxIXF/T7LUdWeTbsTS98T8kSdeE8uBsxGTJP9M0qnbUqjmFXpBxlVRalJdp6LkdPSa56xJqnGUVOz1+ogcItZecFB5z0NW359UQpa9Rz1O56j6AAXyaazhVux+4RA+RCXZarPlVmMppEylY3OSilKdaS4NxIUUteUkyRC+xFEjGxpJCFfOjEcSIEEdTFCgAzowMMBFWwMKDv4qkAUCFsaq4GHMRkvl5wx6EENsB7MYZlCMtvHdRK8SRg30fU6HoxWsouFjI1KEFPlOPpJD8o18Ij/I34lcHufwtezjLgdYZtWWXq0W/8xE6bi70Oqjpmp2oQG3uVYVtVs84nehBPju89eHxbuFlJcm78hP1P+WHJCv2IHR/a28z7PCmyl6ZNQSTKyOfoNXYAMz8fibYrTJZ+vPS8ee29wmsIlPBm7gnsU98AM+n+cpZ9J5vwZW8DA+zOd/ySqP+z094195cu0kZvdm6K3z/0MbO9Ow51HN2VDzTb7P1jvKN13zuPon0W1jvD5m0hnYGpry/Mr/M86nu19/UPWkGvNxn4xz3kmPmTDeNNnj98qoUdrK3MmQ/PXk9oPwylmEBFyBdSS5BdvwGHJQAkV4KXwQPgtfFn5FV6Kr0ctBakQIMZdgaEWT/wC35HkI</latexit>](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-26-320.jpg)
![27
Actor-Critic
• Actor (= ⽅策)
– 環境に対して⾏動を出⼒(act)する
• Critic (= 価値関数)
– actor のとった⾏動を
Temporal Difference (TD) 誤差
などで評価(criticize)する
• 特定の学習則というよりは,
学習器の構造を指す.
• 理論解析
– [Kimura & Kobayashi 98]
– [Konda & Tsitsiklis 00] エージェント
TD 誤
差
環境
Actor
Critic
報酬
t
TD誤差
V (s), Q(s, a)
⇡✓(a|s)
状態 ⾏動](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-27-320.jpg)
![28
A3C
• [Mnih+ 16]
• Asynchronous Advantage Actor Critic
– advantage actor critic:
– asynchronous:
‣ actor-criticのペアを複数⽤意
‣ 各actor-criticが独⽴に環境と相互作⽤して勾配を計算
– ( は陽に推定せず,状態価値関数で近似)
‣ ときどき
• 膨⼤な計算資源による暴⼒
i 2 {1, N}
✓0
= ✓ + ↵ d✓
✓i = ✓0
r✓⌘(⇡) = E⇡ [r✓ ln ⇡✓(a|s)A⇡
(s, a)]
A(st, at)
d✓ d✓ + r✓i
ln ⇡✓i
(at|st)Ai
(st, at)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-28-320.jpg)
![29
Extension: (N)PGPE
• (Natural) Policy Gradient with Parameter based Exploration
[Sehnke+ 10; Miyamae+ 10]
[Zhao+ 12]
µ✓
✓
⇡(a|s; ✓)
a
s
s
p(✓|⇢)
✓
✓
PGPE
PG Var[r✓
ˆJ(✓)]
Var[r⇢
ˆJ(⇢)]
](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-29-320.jpg)
![30
Off-Policy Learning (<---> On-Policy)
• 学習 期待値演算
• Off-policy: 推定⽅策 挙動⽅策
• Off-policyで学習できればデータの再利⽤が可能 !!!
[Sugimoto+ 16]
E
⇡
[·] 6= E[·]
time at
with 0.00
The t
was 2 m
0.11 m)
reward i
ballandt
where th
ball’s po
( 100a =
cost was
where c
pendent
For o
cursive u
tively. T
.0 99c =
The l
ing conv
stage, th
went in.
The m
ries of th
are show
nated joi
ketball-s
the mov
tainty of
ing is sho
Discuss
In our P
istic and
Thus, th
can be
Convolution Convolution Fully connected Fully connected
No input
Figure 1 | Schematic illustration of the convolutional neural network. The
details of the architecture are explained in the Methods. The input to the neural
symbolizes sliding of each filter across input image) and two fully connected
layers with a single output for each valid action. Each hidden layer is followed
RESEARCH LETTER
[Mnih+ 15]
LETTER RESEARCH
6=
;](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-30-320.jpg)
![31
Off-Policy ⽅策勾配法
• [Degris+ 12]
• 重点サンプリングを⽤いることで,
off-policyのサンプルから⽅策勾配を推定
O↵-Policy Actor-Critic
ˆZ = {u 2 U | dg(u) = 0} and the value function
weights, vt, converge to the corresponding TD-solution
with probability one.
Proof Sketch: We follow a similar outline to the
two timescale analysis for on-policy policy gradient
actor-critic (Bhatnagar et al., 2009) and for nonlinear
GTD (Maei et al., 2009). We analyze the dynamics
for our two weights, ut and zt
T
= (wt
T
vt
T
), based on
our update rules. The proof involves satisfying seven
requirements from Borkar (2008, p. 64) to ensure con-
vergence to an asymptotically stable equilibrium.
4. Empirical Results
Behavior
Softmax-GQ
O↵-Policy Actor-Critic
= 0} and the value function
the corresponding TD-solution
ollow a similar outline to the
for on-policy policy gradient
et al., 2009) and for nonlinear
9). We analyze the dynamics
and zt
T
= (wt
T
vt
T
), based on
proof involves satisfying seven
kar (2008, p. 64) to ensure con-
tically stable equilibrium.
ults
Behavior Greedy-GQ
Softmax-GQ O↵-PAC
⌘ (⇡✓) ,
X
s2S
⇢ (s)V ⇡
(s)
r✓⌘ (⇡✓) '
X
s2S
⇢ (s)
X
a2A
r✓⇡✓(a|s)Q⇡
(s, a)
=
X
s2S
⇢ (s)
X
a2A
(a|s)
⇡✓(a|s)
(a|s)
r✓⇡✓(a|s)
⇡✓(a|s)
Q⇡
(s, a)
= E
⇡✓(a|s)
(a|s)
r✓ ln ⇡✓(a|s)Q⇡
(s, a)](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-31-320.jpg)
![32
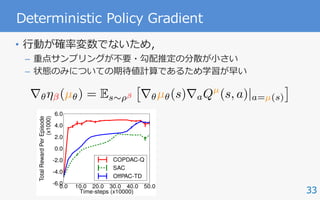
Deterministic Policy Gradient
• [Silver+ 14]
• 決定的⽅策 μ についての⽅策勾配定理
• Off-policy Deterministic Policy Gradient
• Criticとして保持している⾏動価値関数の勾配で学習
r✓⌘(µ✓) = Es⇠⇢µ
⇥
r✓µ✓(s)raQµ
(s, a)|a=µ(s)
⇤
r✓⌘ (µ✓) = Es⇠⇢
⇥
r✓µ✓(s)raQµ
(s, a)|a=µ(s)
⇤](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-32-320.jpg)
![34
⽅策を単調改善したい
• Policy oscillation
/ Policy degradation
• 関数近似の下で
⽅策の単調改善を⽬指した研究たち:
– Conservative Policy Iteration [Kakade & Langford 02]
– Safe Policy Iteration [Pirotta+ 13]
– Trust Region Policy Optimization [Schulman+ 15]
58 P. Wagner / Neural Networks 52 (2014) 43–61
(a) Performance level of the policy after each policy update.
[Bertsekas 11; Wagner 11; 14]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-34-320.jpg)
![35
Trust Region Policy Optimization
• [Schulman+ 15]
• 任意の⽅策 π と πʼ について:
• ⽅策 πʼ を実際にサンプリングすることなく評価できる
• 右辺が正であれば⽅策は単調改善
: πʼ の π に対するアドバンテージ
: πʼ と π の 分離度
⌘(⇡0
) ⌘(⇡)
X
s2S
⇢⇡
(s) ¯A⇡
⇡0 (s) c Dmax
KL (⇡0
k⇡)
¯A⇡
⇡0 (s) =
X
a2A
⇡0
(a|s)A⇡
(s, a),
Dmax
KL (⇡0
k⇡) = max
s2S
DKL(⇡0
(·|s)k⇡(·|s))](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-35-320.jpg)
![36
Trust Region Policy Optimization
• Trust Region Policy Optimization [Schulman+ 15]
– 以下の制約付き最適化問題の解として⽅策を更新
• Proximal Policy Optimization [Schulman+ 17a]
– 制約付き最適化ではなく正則化として,勾配法で学習
– の値をある範囲で打ち切ることで学習を安定化
maximize
✓0
L(✓0
, ✓) = Es⇠⇢✓,a⇠⇡✓
⇡✓0 (a|s)
⇡✓(a|s)
A⇡✓
(a|s)
subject to Es⇠⇢✓ [DKL(⇡✓(·|s)k⇡✓0 (·|s))]
⇡✓0 (a|s)/⇡✓(a|s)
LPPO
(✓0
, ✓) = Es⇠⇢✓,a⇠⇡✓
⇡✓0 (a|s)
⇡✓(a|s)
A⇡✓
(a|s) c Es⇠⇢✓ [DKL(⇡✓(·|s)k⇡✓0 (·|s))]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-36-320.jpg)
![37
Benchmarking
• [Duan+ 16]
• Mujoco
Benchmarking Deep Reinforcement L
(a) (b) (c) (d)
F
F](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-37-320.jpg)
![39
Q-Prop / Interpolated Policy Gradient
• [Gu+ 17a; 17b]
• TRPO と DPG の組み合わせ
r✓⌘(⇡✓) ⇡ (1 ⌫)Es⇠⇢✓,a⇠⇡✓
[r✓ ln ⇡✓(a|s)A⇡✓
(a|s)]
+ ⌫Es⇠⇢ [r✓Qµ✓
(s, µ✓(s))]
⇡ (1 ⌫)Es⇠⇢✓,a⇠⇡✓
r✓0
⇡✓0 (a|s)
⇡✓(a|s)
|✓0=✓A⇡✓
(a|s)
+ ⌫Es⇠⇢
⇥
r✓µ✓(s)raQµ✓
(s, a)|a=µ✓(s)
⇤
⇡✓(a|s) = (a µ✓(s))](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-39-320.jpg)
![40
その他の重要な学習法たち
• ACER
– [Wang+ 17]
– Off-policy Actor Critic + Retrace [Munos+ 16]
• ⽅策勾配法 と Q 学習の統⼀的理解
– [OʼDonoghue+ 17; Nachum+ 17a; Schulman+ 17b]
• Trust-PCL
– Off-Policy TRPO
– [Nachum+ 17b]
• ⾃然⽅策勾配法
– [Kakade 01]](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-40-320.jpg)
![41
References :: 1
[Abe+ 10] Optimizing Debt Collections Using Constrained Reinforcement Learning, ACM SIGKDD.
[Baxter & Bartlett 01] Infinite-horizon policy-gradient estimation. JAIR.
[Bertsekas 11] Approximate policy iteration: A survey and some new methods, Journal of Control
Theory and Applications.
[Degris+ 12] Off-Policy Actor-Critic, ICML.
[Duan+ 16] Benchmarking Deep Reinforcement Learning for Continuous Control, ICML.
[Gu+ 17a] Q-prop: Sample-efficient policy gradient with an off-policy critic, ICLR.
[Gu+ 17b] Interpolated policy gradient: Merging on-policy and off-policy gradient estimation for deep
reinforcement learning, NIPS.
[Kakade 01] A Natural Policy Gradient, NIPS.
[Kakade & Langford 02] Approximately Optimal Approximate Reinforcement Learning, ICML.
[Kimura & Kobayashi 98] An analysis of actor/critic algorithms using eligibility traces, ICML.
[Konda & Tsitsiklis 00] Actor-critic algorithms, NIPS.
[Miyamae+ 10] Natural Policy Gradient Methods with Parameter-based Exploration for Control Tasks,
NIPS.
[Mnih+ 15] Human- level control through deep reinforcement learning, Nature.
[Mnih+ 16] Asynchronous Methods for Deep Reinforcement Learning, ICML.
[Munos+ 16] Safe and efficient off-policy reinforcement learning, NIPS.
[Nachum+ 17a] Bridging the Gap Between Value and Policy Based Reinforcement Learning, NIPS.](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-41-320.jpg)
![42
References :: 2
[Nachum+ 17b] Trust-PCL: An Off-Policy Trust Region Method for Continuous Control, arxiv.
[OʼDonoghue+ 17] Combining Policy Gradient and Q-Learning, ICLR.
[Pirotta+ 13] Safe Policy Iteration, ICML.
[Sehnke+ 10] Parameter-exploring policy gradients, Neural Networks.
[Schulman+ 15] Trust Region Policy Optimization, ICML.
[Schulman+ 17a] Proximal Policy Optimization Algorithms, arxiv.
[Schulman+ 17b] Equivalence Between Policy Gradients and Soft Q-Learning, arxiv.
[Silver+ 14] Deterministic Policy Gradient Algorithms, ICML
[Silver+ 16] Mastering the game of Go with deep neural networks and tree search, Nature.
[Sugimoto+ 16] Trial and error: Using previous experiences as simulation models in humanoid motor
learning, IEEE Robotics & Automation Magazine.
[Sutton+ 99] Policy Gradient Methods for Reinforcement Learning with Function Approximation, NIPS.
[Wagner 11] A reinterpretation of the policy oscillation phenomenon in approximate policy iteration,
NIPS.
[Wagner 14] Policy oscillation is overshooting, Neural Networks.
[Wang+ 17] Sample efficient actor-critic with experience replay, ICLR.
[Watkins 89] Learning From Delayed Rewards, PhD Thesis.
[Williams 92] Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement
Learning, Machine Learning,](https://image.slidesharecdn.com/20171213pgss-180213114603/85/slide-42-320.jpg)


![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=640&height=640&fit=bounds)



































