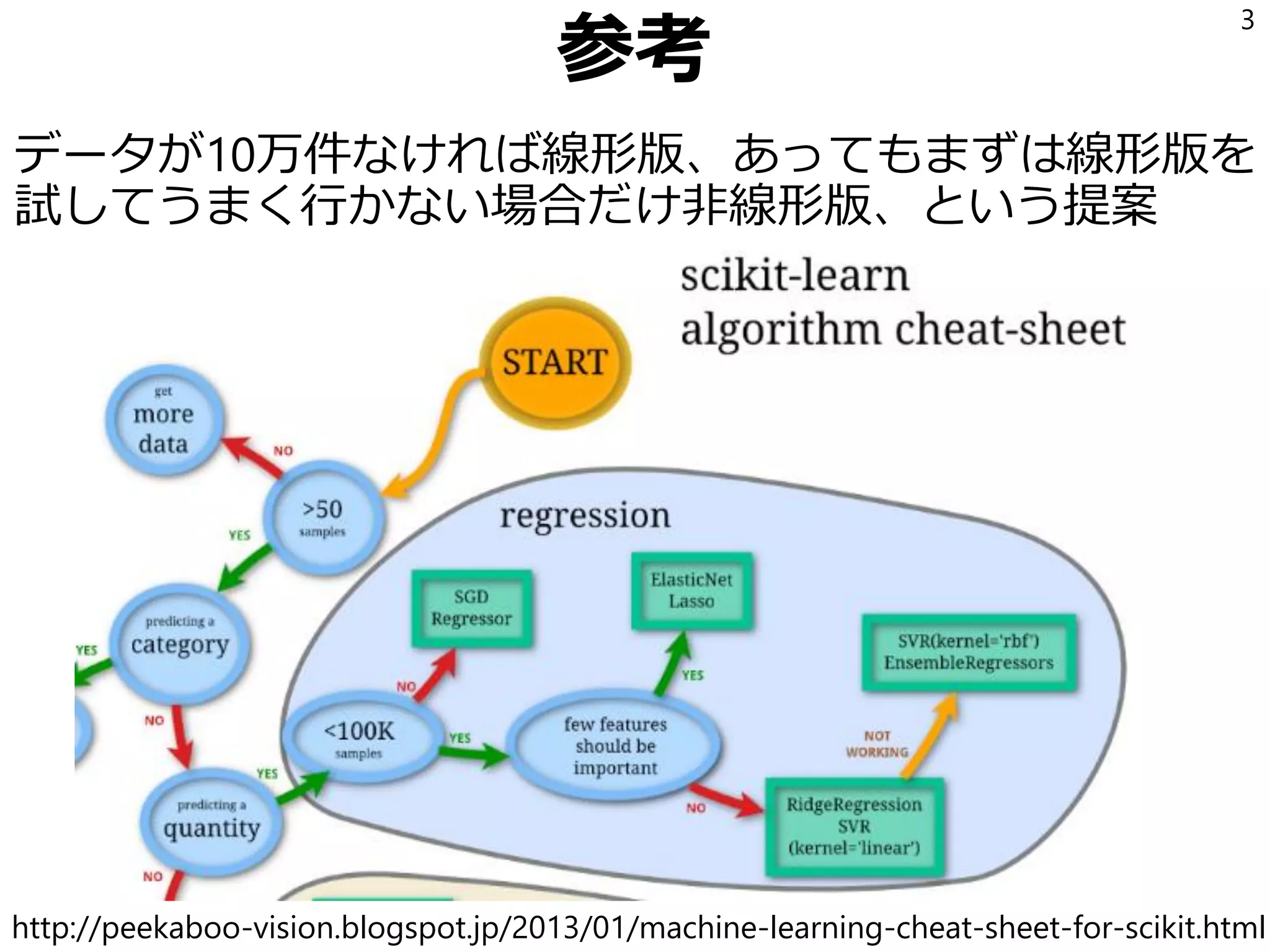
機械学習に関して「線形な学習機より非線形な学習機の方がよい」という誤解が根強い。 モデルの表現力は確かに非線形版の方が高い。 が、トレードオフとして必要なデータ量も多い。 実際に少ないデータ量で非線形版を使うと何が起こるのか回帰を題材に実験して確認する。





































![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)




























