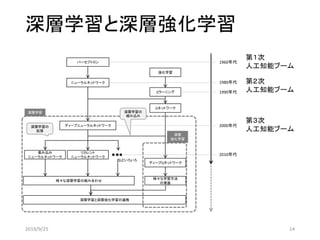
人間に勝る深層学習技術
• 囲碁の世界チャンピオンに勝利: AlphaGo (Zero)
• By Google DeepMind
• 対話などの自然発話に対する音声認識
• By Microsoft
• 機械翻訳(一部の言語対)
• By Google
• 読唇術
• By Oxford and Google
• 音声合成
• By Google
• 手書き文字認識
• 画像からの「ガン」発見
“I’m from Japan”
→“7”
cancer
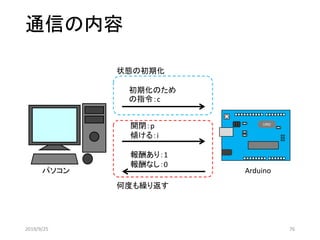
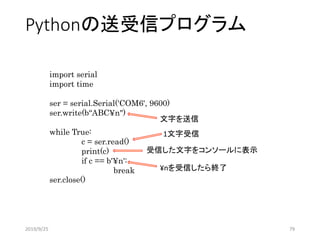
Pythonの送受信プログラム
import serial
import time
ser= serial.Serial('COM6', 9600)
ser.write(b“ABC¥n")
while True:
c = ser.read()
print(c)
if c == b'¥n':
break
ser.close()
1文字受信
文字を送信
受信した文字をコンソールに表示
¥nを受信したら終了
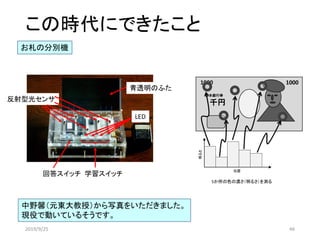
2019/9/25 79














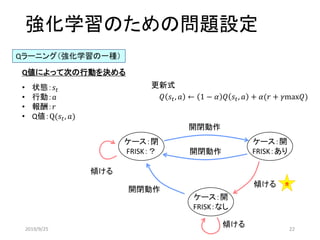
![強化学習のための問題設定
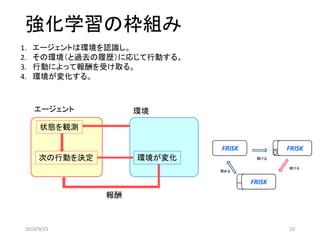
Qラーニング(強化学習の一種)
• 状態:𝒔 𝒕
• 行動:𝑎
• 報酬:𝑟
• Q値:Q(𝑠𝑡, 𝑎)
Q値によって次の行動を決める
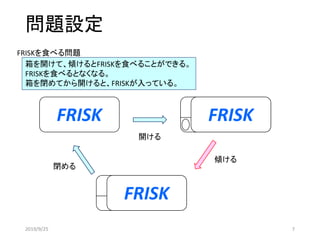
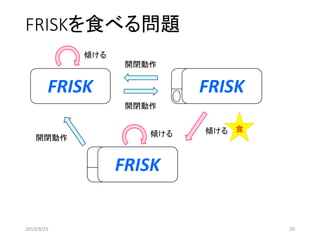
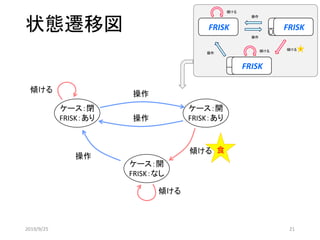
ケース:閉
FRISK:あり
[0 1]
ケース:開
FRISK:あり
[1 1]
ケース:開
FRISK:なし
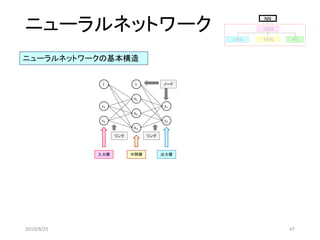
[1 0]
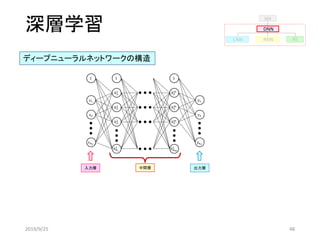
開閉動作
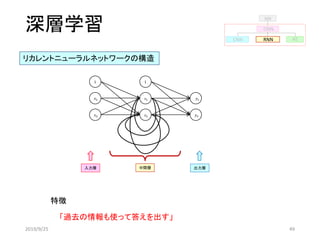
(行動:1)
開閉動作
(行動:1)
開閉動作
(行動:1)
傾ける
(行動:0)
傾ける
(行動:0)
傾ける
(行動:0)
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
更新式
状態に番号を付ける
ケース
閉:0 開:1
FRISK:
なし:0 あり:1
食
2019/9/25 24](https://image.slidesharecdn.com/190925-190925160925/85/slide-24-320.jpg)
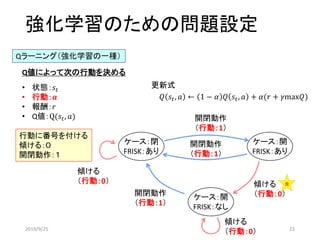
![傾ける
(行動:0 報酬:1)
強化学習のための問題設定
Qラーニング(強化学習の一種)
• 状態:𝑠𝑡
• 行動:𝑎
• 報酬:𝒓
• Q値:Q(𝑠𝑡, 𝑎)
Q値によって次の行動を決める
ケース:閉
FRISK:あり
[0 1]
ケース:開
FRISK:あり
[1 1]
ケース:開
FRISK:なし
[1 0]
開閉動作
(行動:1 報酬:0)
開閉動作
(行動:1 報酬:0 )
開閉動作
(行動:1 報酬:0 )
傾ける
(行動:0 報酬:0 )
傾ける
(行動:0 報酬:0 )
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
更新式
行動によって報酬
あり:1
なし:0
食
2019/9/25 25](https://image.slidesharecdn.com/190925-190925160925/85/slide-25-320.jpg)
![強化学習のための
問題設定
Qラーニング(強化学習の一種)
• 状態:𝑠𝑡
• 行動:𝑎
• 報酬:𝑟
• Q値:Q(𝑠𝑡, 𝑎)
Q値によって次の行動を決める
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
更新式
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
状態、行動、報酬を
すべて数字で表せた。
FRISK FRISK
FRISK
操作
傾ける
操作
操作
傾ける
傾ける
食
2019/9/25 26](https://image.slidesharecdn.com/190925-190925160925/85/slide-26-320.jpg)
![強化学習のための
問題設定
Qラーニング(強化学習の一種)
• 状態:𝑠𝑡
• 行動:𝑎
• 報酬:𝑟
• Q値:𝐐(𝒔 𝒕, 𝒂)
Q値によって次の行動を決める
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
更新式
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q値とは
それぞれの状態で
行動の選びやすさ
を示す値
初めはすべて0にしておく
FRISK FRISK
FRISK
操作
傾ける
操作
操作
傾ける
傾ける
食
2019/9/25 27](https://image.slidesharecdn.com/190925-190925160925/85/slide-27-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
𝐐 𝒔 𝒕, 𝟏 = 𝟎
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝑄 [0 1], 1 ← 1 − 0.6 𝑄 [0 1], 1 + 0.6(0 + 0.8max𝑄)
「ケース:閉」から「操作」を選んだとする
以下のように設定
𝛼 = 0.6
𝛾 = 0.8
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
次の状態の
最も大きいQ値
= 1 − 0.6 𝑄 [0 1], 1 + 0.6 0 + 0.8 × 0 = 0 変わらず2019/9/25 28](https://image.slidesharecdn.com/190925-190925160925/85/slide-28-320.jpg)
![変化
学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝒂 = 𝟏
𝒓 = 𝟏
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝐐 𝒔 𝒕, 𝟎 = 𝟎
𝑄 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝑄 [1 1], 0 ← 1 − 0.6 𝑄 [1 1], 0 + 0.6 𝟏 + 0.8 × 0 = 0.6
「ケース:開、FRISK:あり」から「食べる」を選んだとする
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
2019/9/25 29](https://image.slidesharecdn.com/190925-190925160925/85/slide-29-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝐐 𝒔 𝒕, 𝟎 = 𝟎. 𝟔
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
「ケース:開、FRISK:なし」の状態
報酬が得られるとQ値に値が入る
2019/9/25 30](https://image.slidesharecdn.com/190925-190925160925/85/slide-30-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝒂 = 𝟏
𝒓 = 𝟎
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
𝐐 𝒔 𝒕, 𝟏 = 𝟎
𝑄 [1 0], 1 ← 1 − 0.6 𝑄 [1 0], 1 + 0.6(0 + 0.8 × 0)
「ケース:開、FRISK:あり」から「食べる」を選んだとする
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
2019/9/25 31](https://image.slidesharecdn.com/190925-190925160925/85/slide-31-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
𝐐 𝒔 𝒕, 𝟏 = 𝟎
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝑄 [0 1], 1 ← 1 − 0.6 𝑄 [0 1], 1 + 0.6(0 + 0.8max𝑄)
もう一度、「ケース:閉」から「操作」を選んだとする
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
次の状態の
最も大きいQ値
= 1 − 0.6 𝑄 [0 1], 1 + 0.6 0 + 0.8 × 0.6 = 0.288 変化2019/9/25 32](https://image.slidesharecdn.com/190925-190925160925/85/slide-32-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0 𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
𝐐 𝒔 𝒕, 𝟏 = 𝟎
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝑄 [0 1], 1 ← 1 − 0.6 𝑄 [0 1], 1 + 0.6(0 + 0.8max𝑄)
もう一度、「ケース:閉」から「操作」を選んだとする
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
次の状態の
最も大きいQ値
= 1 − 0.6 𝑄 [0 1], 1 + 0.6 0 + 0.8 × 0.6 = 0.288 変化2019/9/25 33](https://image.slidesharecdn.com/190925-190925160925/85/slide-33-320.jpg)
![学ぶ手順
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0.288
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q値の大きい選択をすると報酬が得られる。
それぞれの行動に答えがなくともQ値というものを使って自ら報酬が得ら
れる行動を選択できるようになる。
2019/9/25 34](https://image.slidesharecdn.com/190925-190925160925/85/slide-34-320.jpg)
![テーブルで書ける
状態[1 1]の場合
参照 出力
行動0を選択
行動
0 1
状態 [0 1] 0 0.7
[1 1] 0.8 0.4
[1 0] 0 0.2
強化学習(Qラーニング)はこの表を自動的に作成することに相当
2019/9/25 35](https://image.slidesharecdn.com/190925-190925160925/85/slide-35-320.jpg)
![追加の説明
Q値が同じとき
同じQ値の中から
ランダムに行動を選ぶ
ランダムな行動
Q 𝑠𝑡, 0 = 0.0
Q 𝑠𝑡, 𝟏 = 0.5
Q 𝑠𝑡, 2 = 0.2
Q 𝑠𝑡, 𝟑 = 0.5
Q 𝑠𝑡, 𝟒 = 0.5
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0.288
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
1,3,4のいずれかの
行動をランダムに選ぶ
ある確率で
Q値に関係なく
行動を選ぶ
深層強化学習でも
設定が必須な機能 本来選ばれる
行動
ランダムに選ばれた行動
2019/9/25 36](https://image.slidesharecdn.com/190925-190925160925/85/slide-36-320.jpg)
![プログラムで実装する
# coding:utf-8
import numpy as np
def random_action():
return np.random.choice([0, 1])
def get_action(next_state, episode):
ns = next_state[0]+next_state[1]*2-1
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0,1):
a = np.where(q_table[ns]==q_table[ns].max())[0]
next_action= np.random.choice(a)
else:
next_action= random_action()
return next_action
def step(state, action):
reward = 0
if state[0]==0:
if action==1:
state = [1,1]
else:
if state[1]==1:
if action==0:
state = [1,0]
reward= 1
else:
state = [0,1]
else:
if action==1:
state = [0,1]
return state, reward
def update_Qtable(q_table, state, action, reward, next_state):
gamma = 0.9
alpha = 0.5
ns = next_state[0]+next_state[1]*2-1
s = state[0]+state[1]*2-1
next_maxQ=max(q_table[ns])
q_table[s, action] = (1 - alpha) * q_table[s, action] +¥
alpha * (reward+ gamma * next_maxQ)
return q_table
max_number_of_steps = 5
num_episodes = 10
q_table = np.zeros((3, 2))
for episode in range(num_episodes):
state = [0,1]
episode_reward= 0
for t in range(max_number_of_steps): #1???s?̃??[?v
action = get_action(state, episode) # a_{t+1}
next_state, reward = step(state, action)
print(state, action, reward)
episode_reward+= reward #? V? ヌ?チ
q_table= update_Qtable(q_table, state, action, reward, next_state)
state = next_state
print('episode: %d total reward %d' %(episode+1, episode_reward))
print(q_table)
Q値を基に次の行動を決める
Q値の更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
2019/9/25 37](https://image.slidesharecdn.com/190925-190925160925/85/slide-37-320.jpg)
![変数の設定
max_number_of_steps = 5
num_episodes = 10
q_table = np.zeros((3, 2))
for episode in range(num_episodes):
state = [0,1]
episode_reward = 0
ほかの処理
1エピソードでの行動の回数
エピソードの回数
行動
0 1
状態 [0 1] 0 0.7
[1 1] 0.8 0.4
[1 0] 0 0.2
Q値のテーブル
𝒔 𝒕 = [𝟎 𝟏]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0.288
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
報酬の合計
Q値を基に次の行動を決める
Q値の更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
2019/9/25 38](https://image.slidesharecdn.com/190925-190925160925/85/slide-38-320.jpg)
![次の行動&ランダム行動
def random_action():
return np.random.choice([0, 1])
def get_action(next_state, episode):
ns = next_state[0]+next_state[1]*2-1
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
a = np.where(q_table[ns]==q_table[ns].max())[0]
next_action = np.random.choice(a)
else:
next_action = random_action()
return next_action
Q値を基に次の行動を決める
Q値の更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
ランダムな行動をとるため
の関数を作っておく
深層強化学習でも必要
ある確率でランダムな
行動を起こすように
最も大きいQ値を持つ行動を選択
このように書くことで、最も大きい
Q値となる行動が複数の場合には
リストで値が得られる。
Q 𝑠𝑡, 0 = 0.0
Q 𝑠𝑡, 𝟏 = 0.5
Q 𝑠𝑡, 2 = 0.2
Q 𝑠𝑡, 𝟑 = 0.5
Q 𝑠𝑡, 𝟒 = 0.5
1,3,4のいずれかの
行動をランダムに選ぶ
2019/9/25 39](https://image.slidesharecdn.com/190925-190925160925/85/slide-39-320.jpg)
![状態の更新
def step(state, action):
reward = 0
if state[0]==0:
if action==1:
state = [1,1]
else:
if state[1]==1:
if action==0:
state = [1,0]
reward = 1
else:
state = [0,1]
else:
if action==1:
state = [0,1]
return state, reward
𝒔 𝒕 = [𝟎 𝟏]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0.288
Q 𝑠𝑡, 0 = 0.6
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q値を基に次の行動を決める
Q値の更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
状態遷移図通りの行動
確認しましょう。
2019/9/25 40](https://image.slidesharecdn.com/190925-190925160925/85/slide-40-320.jpg)
![Q値の更新
def update_Qtable(q_table, state, action, reward, next_state):
gamma = 0.9
alpha = 0.5
ns = next_state[0]+next_state[1]*2-1
s = state[0]+state[1]*2-1
next_maxQ=max(q_table[ns])
q_table[s, action] = (1 - alpha) * q_table[s, action] +alpha * (reward + gamma * next_maxQ)
return q_table
𝑄 𝑠𝑡, 𝑎 ← 1 − 𝛼 𝑄 𝑠𝑡, 𝑎 + 𝛼(𝑟 + 𝛾max𝑄)
更新式
Q値を基に次の行動を決める
Q値の更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
2019/9/25 41](https://image.slidesharecdn.com/190925-190925160925/85/slide-41-320.jpg)
![実行結果
[[0. 1.15432465]
[0. 1.55835535]
[1.9273458 0. ]]
[0, 1] 1 0
[1, 1] 0 1
[1, 0] 1 0
[0, 1] 1 0
[1, 1] 0 1
episode : 10 total reward 2
[[0. 0.]
[0. 0.]
[0. 0.]]
[0, 1] 0 0
[0, 1] 0 0
[0, 1] 0 0
[0, 1] 1 0
[1, 1] 1 0
episode : 1 total reward 0
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 0
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 1.15
Q 𝑠𝑡, 0 = 1.92
Q 𝑠𝑡, 1 = 0
Q 𝑠𝑡, 0 = 0
Q 𝑠𝑡, 1 = 1.55
食
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
2019/9/25 42](https://image.slidesharecdn.com/190925-190925160925/85/slide-42-320.jpg)



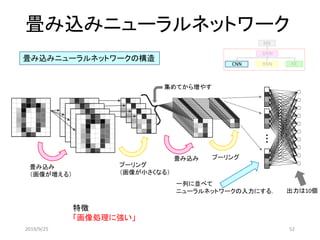



![プログラムで実装する
# -*- coding: utf-8 -*-
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import chainer.initializers as I
from chainer import training
from chainer.training import extensions
from sklearn.datasets import load_digits
from sklearn.model_selection importtrain_test_split
class MyChain(chainer.Chain):
def __init__(self):
super(MyChain, self).__init__()
with self.init_scope():
self.conv1=L.Convolution2D(1,16, 3, 1, 1) # 1層目の畳み込み層(フィルタ数は16)
self.conv2=L.Convolution2D(16, 64, 3, 1, 1) # 2層目の畳み込み層(フィルタ数は64)
self.l3=L.Linear(256,10) #クラス分類用
def __call__(self,x):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)),2, 2) # 最大値プーリングは2×2,活性化関数はReLU
h2 = F.max_pooling_2d(F.relu(self.conv2(h1)),2, 2)
y = self.l3(h2)
return y
epoch = 20
batchsize = 100
# データの作成
digits = load_digits()
data_train, data_test, label_train, label_test = train_test_split(digits.data, digits.target, test_size=0.2)
data_train= data_train.reshape((len(data_train),1, 8, 8))#8x8の行列に変更
data_test = data_test.reshape((len(data_test), 1, 8, 8))#
data_train= (data_train).astype(np.float32)
data_test = (data_test).astype(np.float32)
train = chainer.datasets.TupleDataset(data_train, label_train)
test = chainer.datasets.TupleDataset(data_test, label_test)
# ニューラルネットワークの登録
model = L.Classifier(MyChain(), lossfun=F.softmax_cross_entropy)
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# イテレータの定義
train_iter = chainer.iterators.SerialIterator(train, batchsize)# 学習用
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)# 評価用
# アップデータの登録
updater = training.StandardUpdater(train_iter, optimizer)
# トレーナーの登録
trainer = training.Trainer(updater, (epoch, 'epoch'))
# 学習状況の表示や保存
trainer.extend(extensions.LogReport())#ログ
trainer.extend(extensions.Evaluator(test_iter, model))# エポック数の表示
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss','main/accuracy', 'validation/main/accuracy', 'elapsed_time'] ))#計算状態の表示
#trainer.extend(extensions.dump_graph('main/loss'))#ニューラルネットワークの構造
#trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], 'epoch',file_name='loss.png'))#誤差のグラフ
#trainer.extend(extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'],'epoch', file_name='accuracy.png'))#精度のグラフ
#trainer.extend(extensions.snapshot(), trigger=(100, 'epoch'))# 再開のためのファイル出力
#chainer.serializers.load_npz("result/snapshot_iter_500",trainer)#再開用
# 学習開始
trainer.run()
# 途中状態の保存
chainer.serializers.save_npz("result/CNN.model", model)
ネットワークの設定
実行の設定
データの読み込み
変数などの設定
2019/9/25 59](https://image.slidesharecdn.com/190925-190925160925/85/slide-59-320.jpg)
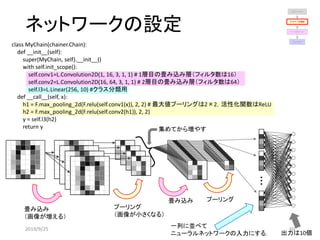


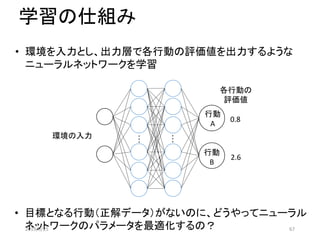
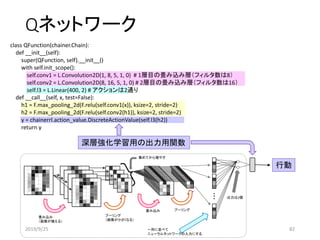
![強化学習との違い
状態[1 1]の場合
入力 出力
行動0を選択
𝑥2
𝑥1
𝑥3
ℎ2
ℎ1
ℎ3
ℎ4
𝑦1
𝑦2
状態[1 1]の場合
参照 出力
行動0を選択
行動
0 1
状態 [0 1] 0 0.7
[1 1] 0.8 0.4
[1 0] 0 0.2
強化学習(Qラーニング)の場合:表を参照して行動を選択
深層強化学習の場合:表の代わりにニューラルネットワーク
2019/9/25 63](https://image.slidesharecdn.com/190925-190925160925/85/slide-63-320.jpg)
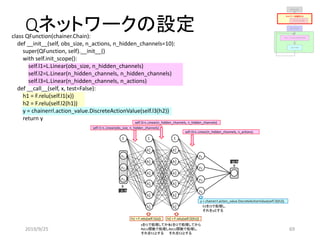
![プログラムで実装する# coding:utf-8
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import chainerrl
import copy
class QFunction(chainer.Chain):
def __init__(self, obs_size, n_actions, n_hidden_channels=10):
super(QFunction, self).__init__()
with self.init_scope():
self.l1=L.Linear(obs_size, n_hidden_channels)
self.l2=L.Linear(n_hidden_channels, n_hidden_channels)
self.l3=L.Linear(n_hidden_channels, n_actions)
def __call__(self,x, test=False):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = chainerrl.action_value.DiscreteActionValue(self.l3(h2))
return y
def random_action():
return np.random.choice([0, 1])
def step(_state, action):
state = _state.copy()
reward = 0
if state[0]==0 and state[1]==1:
if action==1:
state[0] = 1
elif state[0]==1 and state[1]==1:
if action==1:
state[0] = 0
elifaction==0:
state[1] = 0
reward = 1
elif state[0]==1 and state[1]==0:
if action==1:
state[0] = 0
state[1] = 1
return np.array(state), reward
gamma = 0.8
alpha = 0.5
max_number_of_steps = 15 #1試行のstep数
num_episodes = 50 #総試行回数
q_func = QFunction(2, 2)
optimizer= chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
explorer = chainerrl.explorers.LinearDecayEpsilonGreedy(start_epsilon=1.0,
end_epsilon=0.0, decay_steps=num_episodes,
random_action_func=random_action)
replay_buffer = chainerrl.replay_buffer.PrioritizedReplayBuffer(capacity=10** 6)
phi = lambda x: x.astype(np.float32,copy=False)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=50,update_interval=1, target_update_interval=10, phi=phi)
#agent.load('agent')
for episode in range(num_episodes): #試行数分繰り返す
state = np.array([0,1])
R = 0
reward = 0
done = True
for t in range(max_number_of_steps): #1試行のループ
action = agent.act_and_train(state, reward)
next_state, reward = step(state, action)
print(state, action, reward, next_state)
R += reward #報酬を追加
state = next_state
agent.stop_episode_and_train(state, reward, done)
print('episode: ', episode+1, 'R', R, 'statistics:', agent.get_statistics())
agent.save('agent')
ネットワークを設定する
Qネットワークの更新
行動による状態と報酬の更新
ランダムな行動
変数の設定
実行の設定
2019/9/25 68](https://image.slidesharecdn.com/190925-190925160925/85/slide-68-320.jpg)

![実行結果
[0 1] 1 0 [1 1]
[1 1] 0 1 [1 0]
[1 0] 1 0 [0 1]
[0 1] 1 0 [1 1]
[1 1] 0 1 [1 0]
[1 0] 1 0 [0 1]
[0 1] 1 0 [1 1]
[1 1] 0 1 [1 0]
[1 0] 1 0 [0 1]
[0 1] 1 0 [1 1]
[1 1] 0 1 [1 0]
[1 0] 1 0 [0 1]
[0 1] 1 0 [1 1]
[1 1] 0 1 [1 0]
[1 0] 1 0 [0 1]
episode : 50 R 5 statistics: [('average_q', 0.13289504909633182),
('average_loss', 0.012309854020095313), ('n_updates', 700)]
𝑠𝑡 = [0 1]
𝑎 = 1 𝑟 = 0
𝑎 = 1 𝑟 = 0𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 1
𝑎 = 0
𝑟 = 0
𝑎 = 1
𝑟 = 0
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0]
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0] 𝑠𝑡 = [0 1]
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0] 𝑠𝑡 = [0 1]
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0] 𝑠𝑡 = [0 1]
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0] 𝑠𝑡 = [0 1]
食
𝑠𝑡 = [0 1]
𝑠𝑡 = [1 0]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 1]
𝑠𝑡 = [1 0] 𝑠𝑡 = [0 1]
2019/9/25 71](https://image.slidesharecdn.com/190925-190925160925/85/slide-71-320.jpg)

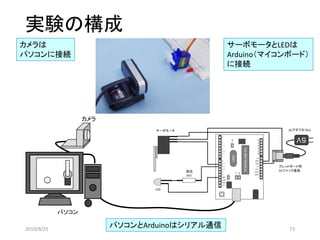
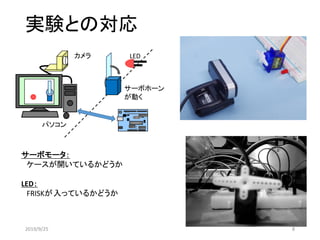
![カメラテストプログラム
サーボモータとLEDがどのように映っているのか確認するためのプログラム
camera.py
ウィンドウにこのような画像が表示
されるので、位置を調整する。
# coding:utf-8
import cv2
n0 = 0
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
xp = int(frame.shape[1]/2)
yp = int(frame.shape[0]/2)
d = 200
cv2.rectangle(gray, (xp-d, yp-d), (xp+d, yp+d), color=0,
thickness=10)
cv2.imshow('gray', gray)
gray = cv2.resize(gray[yp-d:yp + d, xp-d:xp + d],(32, 32))
c =cv2.waitKey(10)
if c == 48:
cv2.imwrite('img/0/{0}.png'.format(n0), gray)
n0 = n0 + 1
elif c == 27:
break
cap.release()
「1」:画像の保存
「ESC」:終了
2019/9/25 74](https://image.slidesharecdn.com/190925-190925160925/85/slide-74-320.jpg)

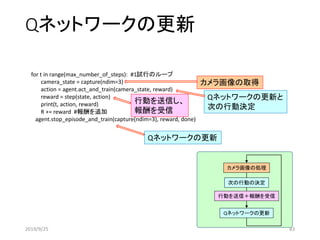
![プログラムで実装する
ネットワークを設定する
Qネットワークの更新
カメラ画像の処理
ランダムな行動
変数の設定
実行の設定
# coding:utf-8
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import chainerrl
import copy
import time
import serial
import cv2
ser = serial.Serial("COM6")
cap = cv2.VideoCapture(0)
class QFunction(chainer.Chain):
def __init__(self):
super(QFunction, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(1, 8, 5, 1, 0) # 1層目の畳み込み層(フィルタ数は8)
self.conv2 = L.Convolution2D(8, 16, 5, 1, 0) # 2層目の畳み込み層(フィルタ数は16)
self.l3 = L.Linear(400, 2) # アクションは2通り
def __call__(self, x, test=False):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2, stride=2)
h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2, stride=2)
y = chainerrl.action_value.DiscreteActionValue(self.l3(h2))
return y
def random_action():
return np.random.choice([0, 1])
def step(_state, action):
reward = 0
if action==0:
ser.write(b"p")
else:
ser.write(b"i")
# time.sleep(1.0)
reward = ser.read();
return int(reward)
def capture(ndim=3):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
xp = int(frame.shape[1]/2)
yp = int(frame.shape[0]/2)
d = 200
cv2.rectangle(gray, (xp-d, yp-d), (xp+d, yp+d), color=0, thickness=10)
cv2.imshow('gray', gray)
gray = cv2.resize(gray[yp-d:yp + d, xp-d:xp + d],(32, 32))
env = np.asarray(gray, dtype=np.float32)
if ndim == 3:
return env[np.newaxis, :, :] # 2次元→3次元テンソル(replay用)
else:
return env[np.newaxis, np.newaxis, :, :] # 4次元テンソル(判定用)
gamma = 0.8
alpha = 0.5
max_number_of_steps = 15 #1試行のstep数
num_episodes = 500 #総試行回数
q_func = QFunction()
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
explorer = chainerrl.explorers.LinearDecayEpsilonGreedy(start_epsilon=1.0, end_epsilon=0.0, decay_steps=num_episodes, random_action_func=random_action)
replay_buffer = chainerrl.replay_buffer.PrioritizedReplayBuffer(capacity=10 ** 6)
phi = lambda x: x.astype(np.float32, copy=False)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=50, update_interval=1, target_update_interval=10, phi=phi)
#agent.load('agent')
time.sleep(5.0)
for episode in range(num_episodes): #試行数分繰り返す
state = np.array([0])
R = 0
reward = 0
done = True
ser.write(b"c")
for t in range(max_number_of_steps): #1試行のループ
camera_state = capture(ndim=3)
action = agent.act_and_train(camera_state, reward)
reward = step(state, action)
print(t, action, reward)
R += reward #報酬を追加
agent.stop_episode_and_train(capture(ndim=3), reward, done)
# print('episode : %d total reward %d' %(episode+1, R))
print('episode : ', episode+1, 'R', R, 'statistics:', agent.get_statistics())
ser.close()
cap.release()
agent.save('agent')
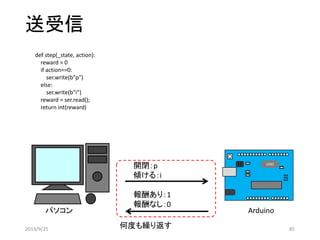
行動を送信+報酬を受信
frisk_exp.py
2019/9/25 81](https://image.slidesharecdn.com/190925-190925160925/85/slide-81-320.jpg)
![カメラ画像の処理def capture(ndim=3):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
xp = int(frame.shape[1]/2)
yp = int(frame.shape[0]/2)
d = 200
cv2.rectangle(gray, (xp-d, yp-d), (xp+d, yp+d), color=0, thickness=10)
cv2.imshow('gray', gray)
gray = cv2.resize(gray[yp-d:yp + d, xp-d:xp + d],(32, 32))
env = np.asarray(gray, dtype=np.float32)
if ndim == 3:
return env[np.newaxis, :, :] # 2次元→3次元テンソル(replay用)
else:
return env[np.newaxis, np.newaxis, :, :] # 4次元テンソル(判定用)
画面の中央だけ使う
2019/9/25 84](https://image.slidesharecdn.com/190925-190925160925/85/slide-84-320.jpg)
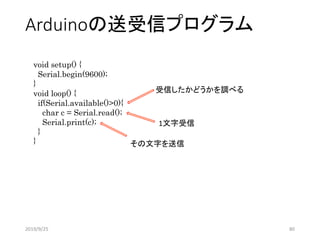
![Arduino #include <Servo.h>
Servo mServo;
int state[2];
void setup() {
mServo.attach(9);
mServo.write(10);
delay(500);
Serial.begin(9600);
pinMode(10, OUTPUT);
state[0] = 0;
state[1] = 1;
digitalWrite(10,LOW);
}
void loop() {
if (Serial.available() > 0) {
char c = Serial.read();
if (c == 'p') {
if (state[0] == 0) {
Serial.print("0");
mServo.write(90);
delay(500);
state[0] = 1;
}
else {
Serial.print("0");
mServo.write(10);
delay(500);
state[0] = 0;
state[1] = 1;
digitalWrite(10, LOW);
}
}
else if (c == 'i') {
if (state[0] == 1 && state[1] == 1) {
Serial.print("1");
digitalWrite(10, HIGH);
state[1] = 0;
}
else {
Serial.print("0");
}
}
else if (c == 'c') {
state[0] = 0;
state[1] = 1;
digitalWrite(10,LOW);
mServo.write(10);
delay(500);
}
}
}
受信時の処理
報酬の送信
サーボモータの角度を変える
状態の遷移
LEDの点灯状態を変える
if (c == 'p') {
if (state[0] == 0) {
Serial.print("0");
mServo.write(10);
delay(500);
state[0] = 0;
state[1] = 1;
digitalWrite(10, LOW);
}
初期設定
受信したか?
受信時の処理
No
Yes
Frisk_Ar
2019/9/25 86](https://image.slidesharecdn.com/190925-190925160925/85/slide-86-320.jpg)
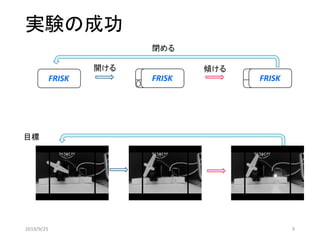
![うまくできました
0 0 0 操作(開ける)
1 1 1 傾ける(食べる)
2 0 0 操作(閉める)
3 0 0 操作(開ける)
4 1 1 傾ける(食べる)
5 0 0 操作(開ける)
6 0 0 操作(開ける)
7 1 1 傾ける(食べる)
8 0 0 操作(開ける)
9 0 0 操作(開ける)
10 1 1 傾ける(食べる)
11 0 0 操作(開ける)
12 0 0 操作(開ける)
13 1 1 傾ける(食べる)
14 0 0 操作(開ける)
episode : 500 R 5 statistics:
[('average_q', 0.5532538031364947),
('average_loss',
0.028086873774230445), ('n_updates',
7450)]
食
食
食
食
食
FRISK FRISK
FRISK
開ける
傾ける
閉める
2019/9/25 87](https://image.slidesharecdn.com/190925-190925160925/85/slide-87-320.jpg)
![うまくできなかった時のために・・・
ネットワークを設定する
Qネットワークの更新
画像の読み取り
ランダムな行動
変数の設定
実行の設定
# coding:utf-8
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import chainerrl
import copy
import time
import serial
import cv2
ser = serial.Serial("COM6")
cap = cv2.VideoCapture(0)
class QFunction(chainer.Chain):
def __init__(self):
super(QFunction, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(1, 8, 5, 1, 0) # 1層目の畳み込み層(フィルタ数は8)
self.conv2 = L.Convolution2D(8, 16, 5, 1, 0) # 2層目の畳み込み層(フィルタ数は16)
self.l3 = L.Linear(400, 2) # アクションは2通り
def __call__(self, x, test=False):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2, stride=2)
h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2, stride=2)
y = chainerrl.action_value.DiscreteActionValue(self.l3(h2))
return y
def random_action():
return np.random.choice([0, 1])
def step(_state, action):
reward = 0
if action==0:
ser.write(b"p")
else:
ser.write(b"i")
# time.sleep(1.0)
reward = ser.read();
return int(reward)
# USBカメラから画像を取得(ラズパイ用)
def capture(ndim=3):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
xp = int(frame.shape[1]/2)
yp = int(frame.shape[0]/2)
d = 200
cv2.rectangle(gray, (xp-d, yp-d), (xp+d, yp+d), color=0, thickness=10)
cv2.imshow('gray', gray)
gray = cv2.resize(gray[yp-d:yp + d, xp-d:xp + d],(32, 32))
env = np.asarray(gray, dtype=np.float32)
if ndim == 3:
return env[np.newaxis, :, :] # 2次元→3次元テンソル(replay用)
else:
return env[np.newaxis, np.newaxis, :, :] # 4次元テンソル(判定用)
gamma = 0.8
alpha = 0.5
max_number_of_steps = 15 #1試行のstep数
num_episodes = 500 #総試行回数
q_func = QFunction()
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
explorer = chainerrl.explorers.LinearDecayEpsilonGreedy(start_epsilon=1.0, end_epsilon=0.0, decay_steps=num_episodes, random_action_func=random_action)
replay_buffer = chainerrl.replay_buffer.PrioritizedReplayBuffer(capacity=10 ** 6)
phi = lambda x: x.astype(np.float32, copy=False)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=50, update_interval=1, target_update_interval=10, phi=phi)
#agent.load('agent')
time.sleep(5.0)
for episode in range(num_episodes): #試行数分繰り返す
state = np.array([0])
R = 0
reward = 0
done = True
ser.write(b"c")
for t in range(max_number_of_steps): #1試行のループ
camera_state = capture(ndim=3)
action = agent.act_and_train(camera_state, reward)
reward = step(state, action)
print(t, action, reward)
R += reward #報酬を追加
agent.stop_episode_and_train(capture(ndim=3), reward, done)
# print('episode : %d total reward %d' %(episode+1, R))
print('episode : ', episode+1, 'R', R, 'statistics:', agent.get_statistics())
ser.close()
cap.release()
agent.save('agent')
行動による状態変化+報酬
frisk_exp_image.py
2019/9/25 88](https://image.slidesharecdn.com/190925-190925160925/85/slide-88-320.jpg)






![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)