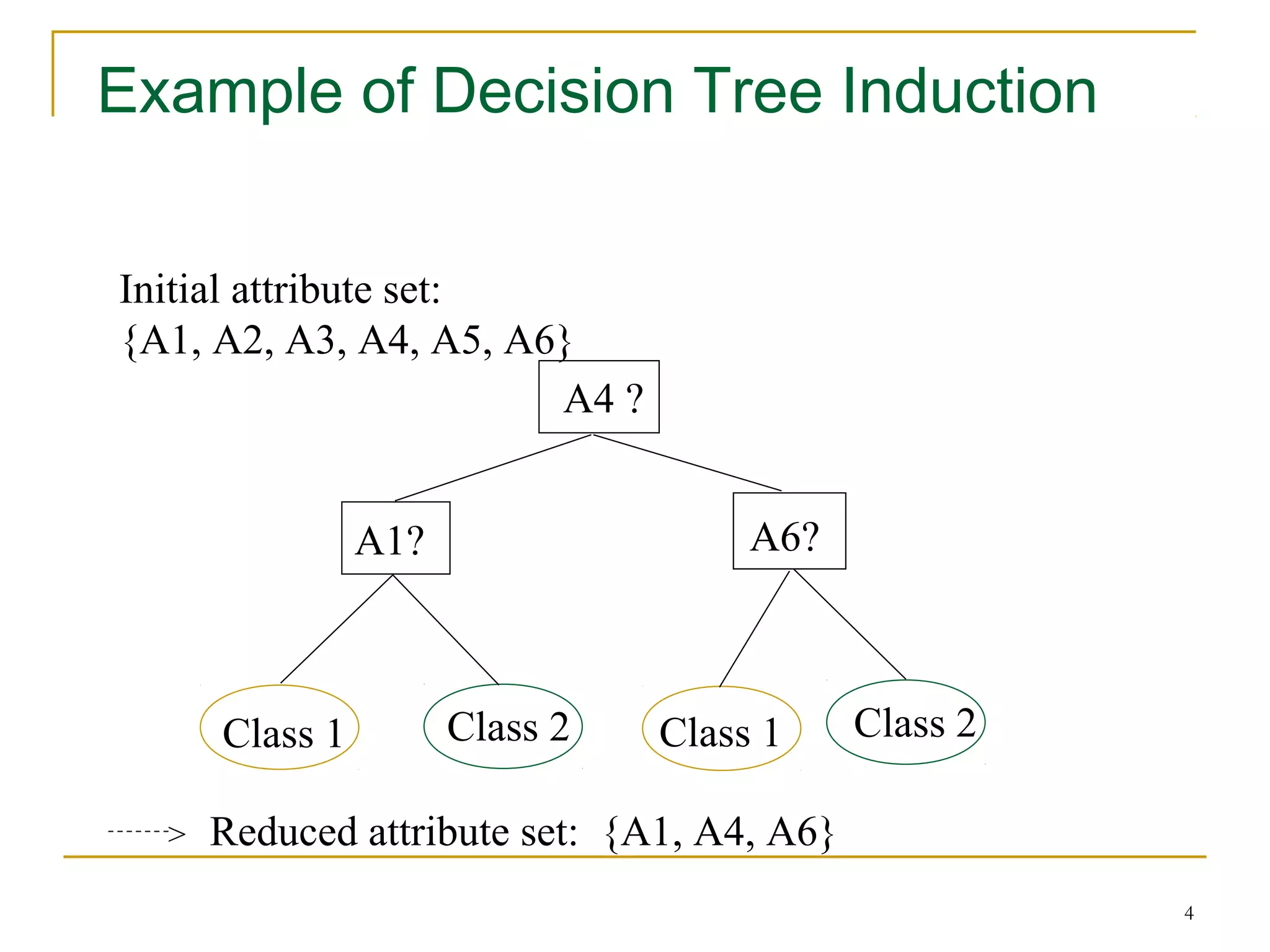
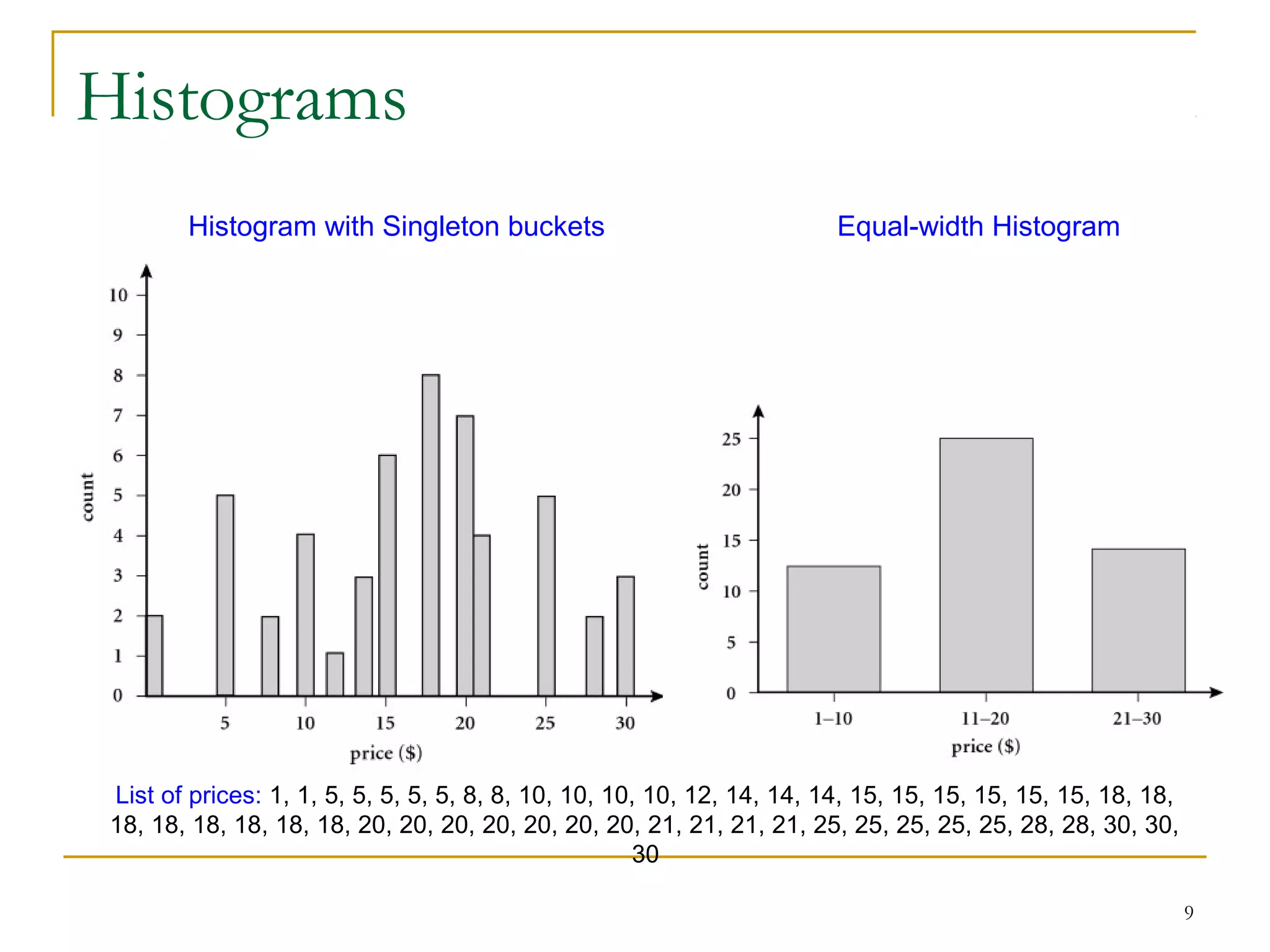
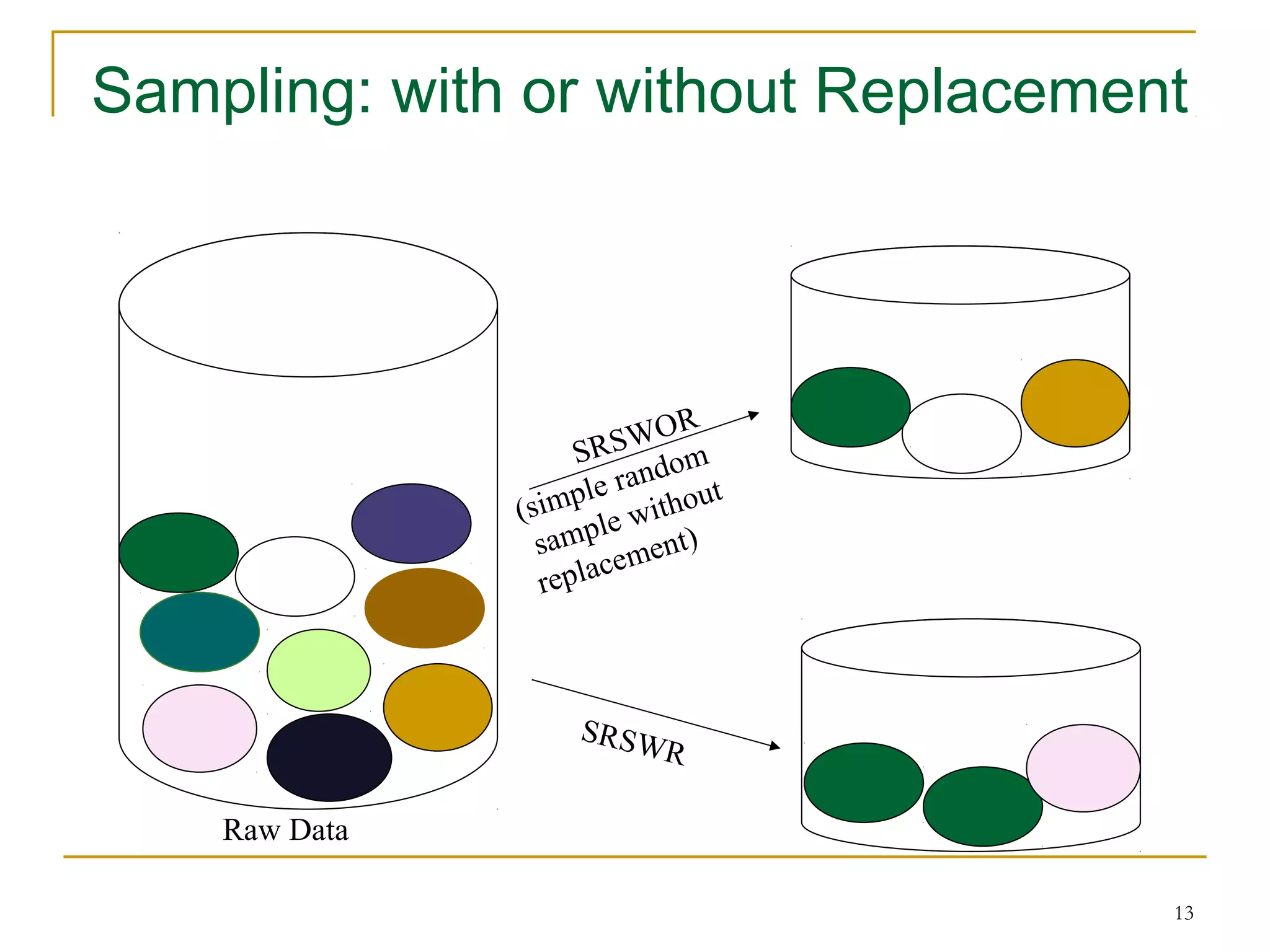
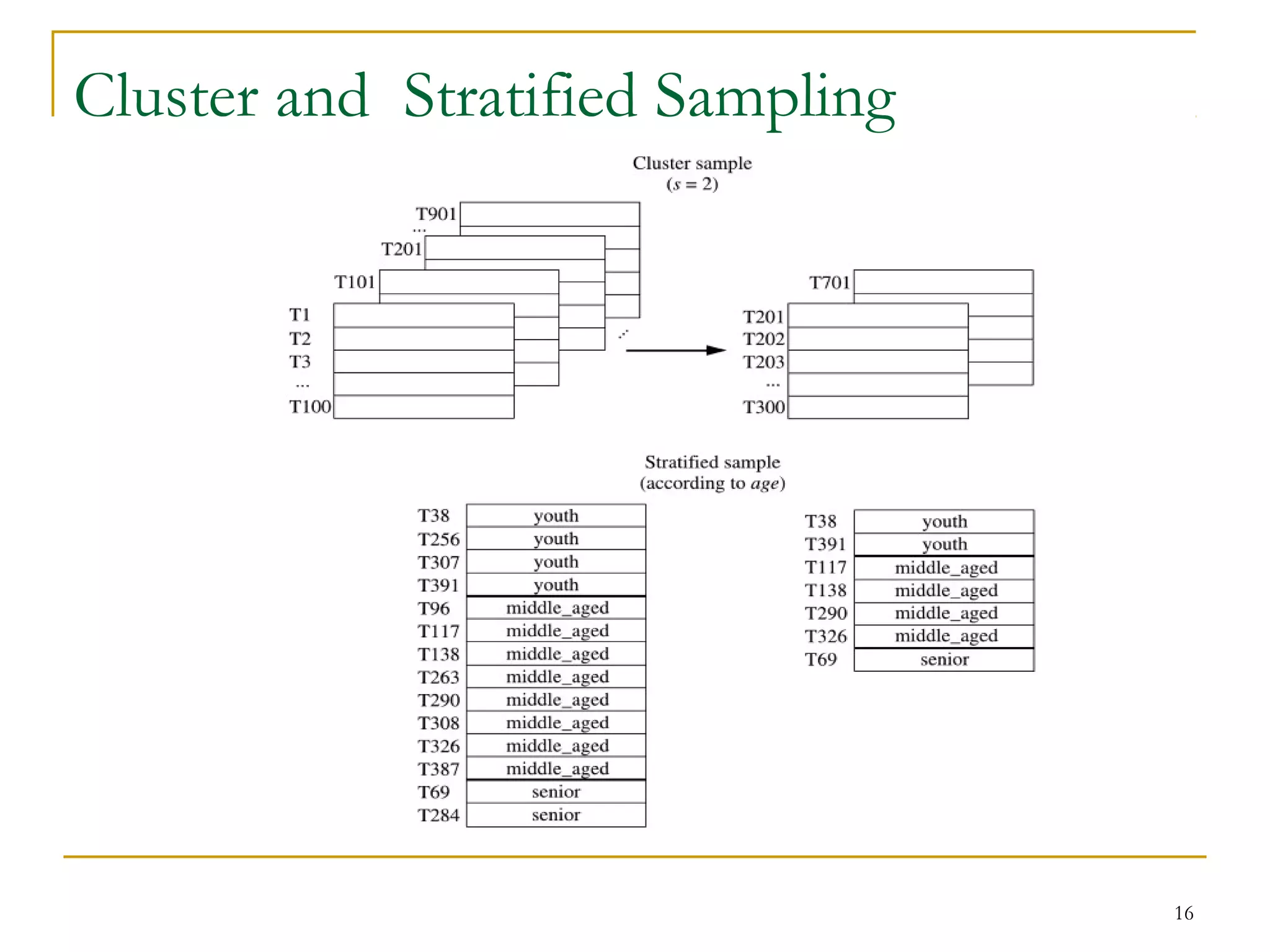
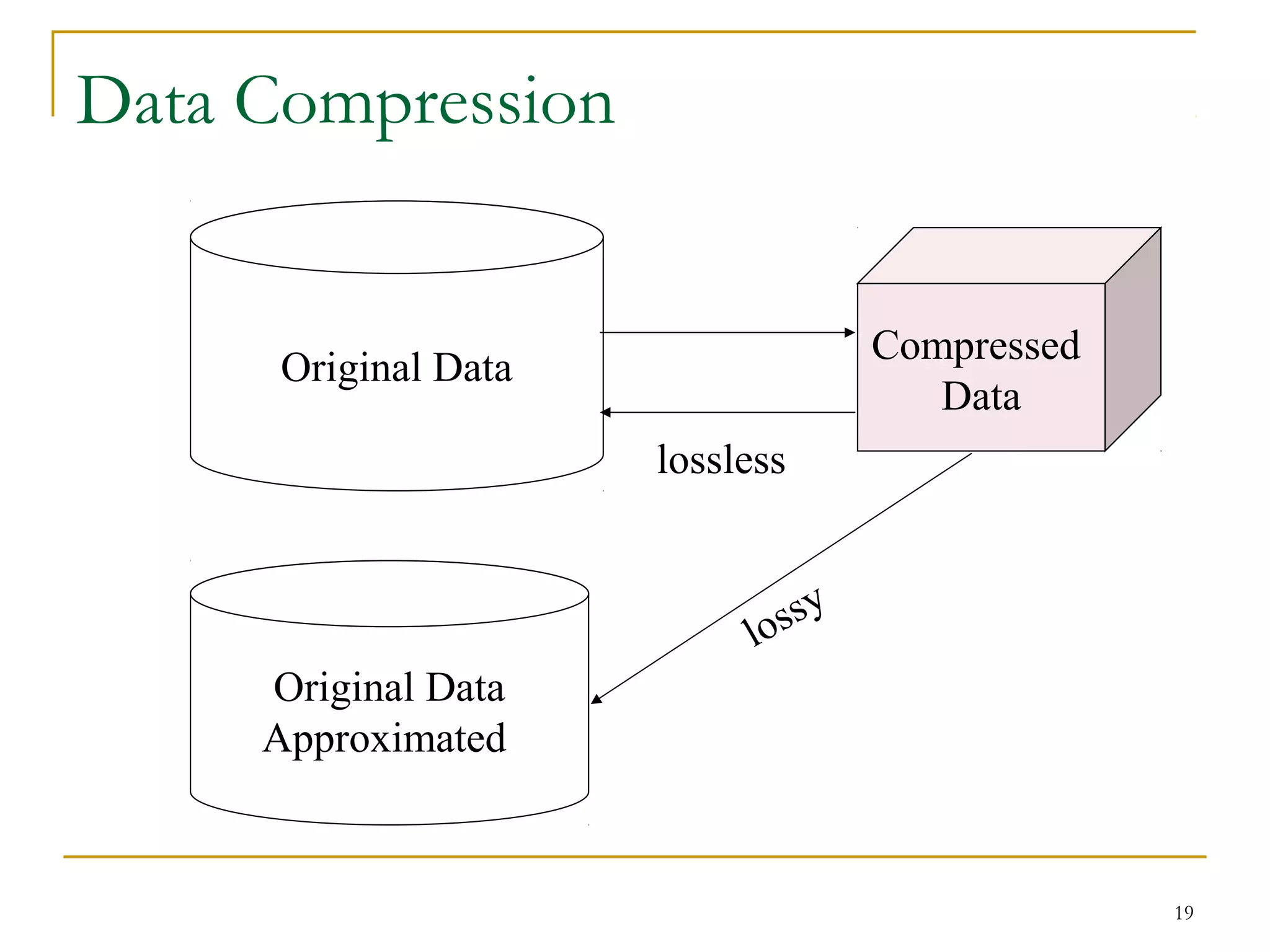
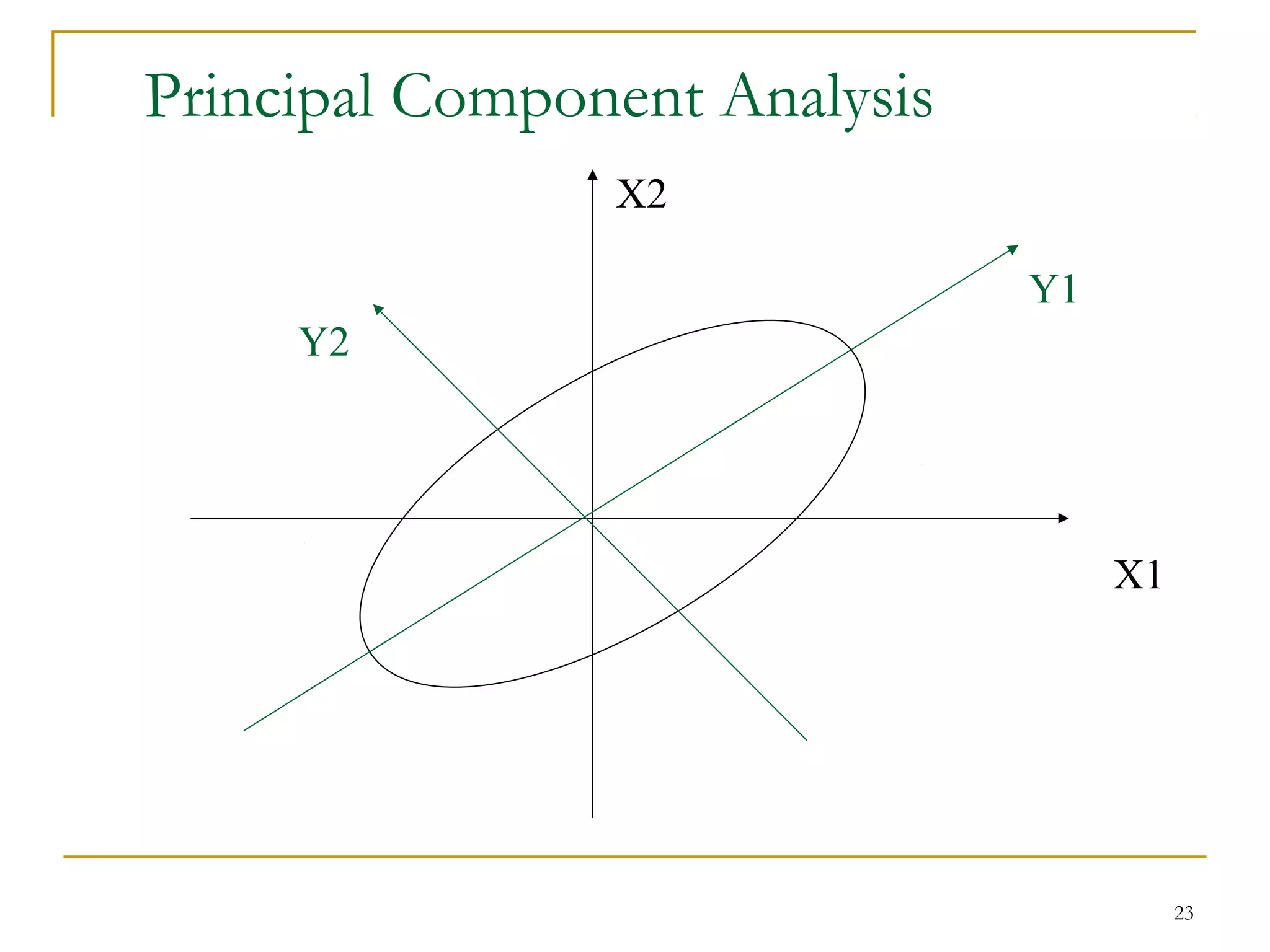
The document discusses various data reduction strategies including attribute subset selection, numerosity reduction, and dimensionality reduction. Attribute subset selection aims to select a minimal set of important attributes. Numerosity reduction techniques like regression, log-linear models, histograms, clustering, and sampling can reduce data volume by finding alternative representations like model parameters or cluster centroids. Dimensionality reduction techniques include discrete wavelet transformation and principal component analysis, which transform high-dimensional data into a lower-dimensional representation.