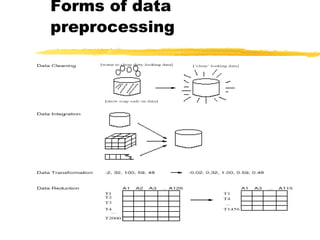
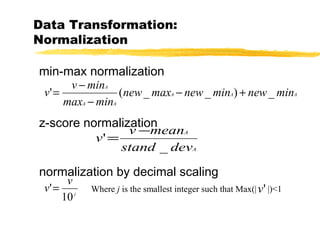
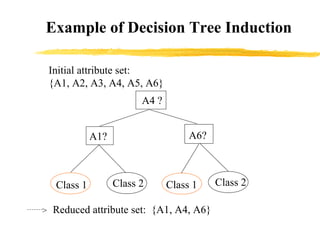
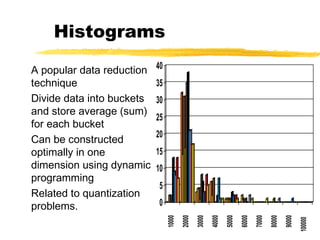
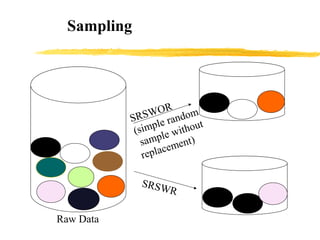
The document discusses the importance of data preprocessing in data mining, highlighting the need for data cleaning, integration, transformation, and reduction to ensure quality mining results. It addresses various issues such as missing, noisy, and inconsistent data, and outlines methods for handling these challenges. Additionally, strategies for data reduction, including dimensionality reduction and discretization, are presented to improve data quality and mining efficiency.