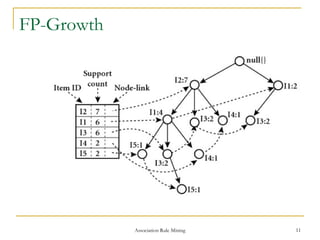
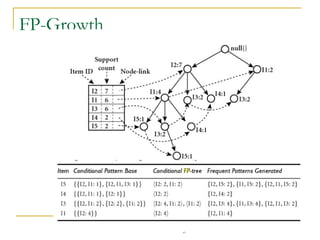
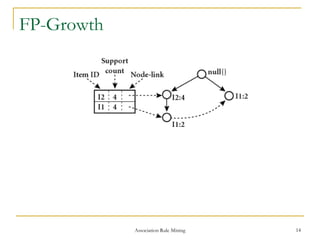
Association rule mining is used to find relationships between items in transactional datasets. It involves finding frequent itemsets that satisfy minimum support and generating association rules from these itemsets that satisfy minimum confidence. FP-Growth is an efficient algorithm for mining frequent itemsets without candidate generation by constructing a frequent-pattern tree and mining it recursively. It avoids multiple database scans and generates far fewer candidates than Apriori, making it faster and more scalable.












![Association Rule Mining 15
Algorithm
Input: A transaction db D; min_sup
Output: Frequent patterns
Construction of FP-Tree
1. Scan database, collect frequent items F and sort in descending
order of support
2. Create root of FP-tree labeled null
For each Trans, sort in descending order [p|P]
Insert_tree([p|P],T)
If T has a child N = p, increment count
else create new node with count 1 and set parent and node
links
If P is non-empty call insert_tree(P,N) recursively](https://image.slidesharecdn.com/1-150506061654-conversion-gate01/85/1-10-association-mining-2-15-320.jpg)



































![평범한 이야기[Intro: 2015 의기제]](https://cdn.slidesharecdn.com/ss_thumbnails/1stcardslide-150505225911-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)









































































