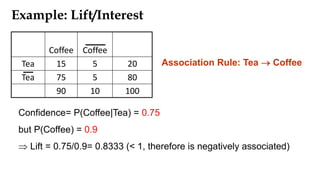
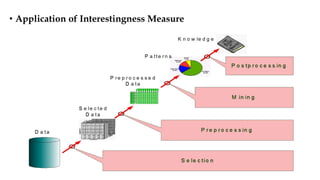
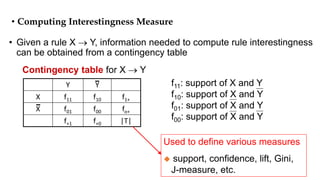
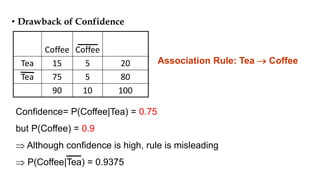
Association rule mining aims to discover interesting relationships between items in large datasets. The document discusses key concepts in association rule mining including support, confidence, and correlation. Support measures how frequently an itemset occurs, while confidence measures the conditional probability of an itemset given another itemset. Correlation evaluates statistical dependence between itemsets and can be used to measure lift. Various measures are proposed to evaluate interestingness and redundancy of discovered rules.




![Correlation Concepts [Cont.]
• corr(A,B) >1 means that A and B are positively correlated
i.e. the occurrence of one implies the occurrence of the other.
• corr(A,B) < 1 means that the occurrence of A is negatively correlated
with (or discourages) the occurrence of B.
• corr(A,B) =1 means that A and B are independent and there is no
correlation between them.
7](https://image.slidesharecdn.com/lect7-associationanalysistocorrelationanalysis-190228021639/85/Lect7-Association-analysis-to-correlation-analysis-7-320.jpg)


[()](1)[(
)()(),(
)()(),(
)()(
),(
)(
)|(
YPYPXPXP
YPXPYXP
tcoefficien
YPXPYXPPS
YPXP
YXP
Interest
YP
XYP
Lift
P(A and B) = P(A) x P(B|A)
P(A) x P(B|A) = P(A and B)
P(B|A) = P(A and B) / P(A)](https://image.slidesharecdn.com/lect7-associationanalysistocorrelationanalysis-190228021639/85/Lect7-Association-analysis-to-correlation-analysis-10-320.jpg)
![Interestingness Measure: Correlations (Lift)
• play basketball eat cereal [40%, 66.7%] is misleading
• The overall % of students eating cereal is 75% > 66.7%.
• play basketball not eat cereal [20%, 33.3%] is more accurate, although with lower
support and confidence
• Measure of dependent/correlated events: lift
89.0
5000/3750*5000/3000
5000/2000
),( CBlift
Basketball Not
basketball
Sum
(row)
Cereal 2000 1750 3750
Not cereal 1000 250 1250
Sum(col.) 3000 2000 5000
)()(
)(
BPAP
BAP
lift
33.1
5000/1250*5000/3000
5000/1000
),( CBlift](https://image.slidesharecdn.com/lect7-associationanalysistocorrelationanalysis-190228021639/85/Lect7-Association-analysis-to-correlation-analysis-11-320.jpg)