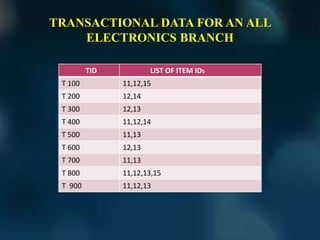
The document discusses mining frequent itemsets and generating association rules from transactional databases. It introduces the Apriori algorithm, which uses a candidate generation-and-test approach to iteratively find frequent itemsets. Several improvements to Apriori's efficiency are also presented, such as hashing techniques, transaction reduction, and approaches that avoid candidate generation like FP-trees. The document concludes by discussing how Apriori can be applied to answer iceberg queries, a common operation in market basket analysis.





![THE JOIN STEP
• To find LK , a set of candidate K-itemsets is generated by joining LK-1
with itself . This set of candidates is denoted CK. Let l1 and l2 be itemsets
in lK-1.
• Apriori assumes that items within a transaction or itemset are stored in
lexicographical order. The join LK-1 ∞ LK-1 is performed.
• That is members l1 and l2 of LK-1 are joined if (l1[1]=l2[1]) ^
(l1[2]=l2[2]) ^….^ (l1[K-2] = l2[K-2]) ^ (l1[K-1] < l2[K-1])
• The condition l1[K-1] < l2[K-1] simply ensures that no duplicates are
generated.](https://image.slidesharecdn.com/miningsingledimensionalbooleanassociationrulesfromtransactional-180305130529/85/Mining-single-dimensional-boolean-association-rules-from-transactional-6-320.jpg)
































































































