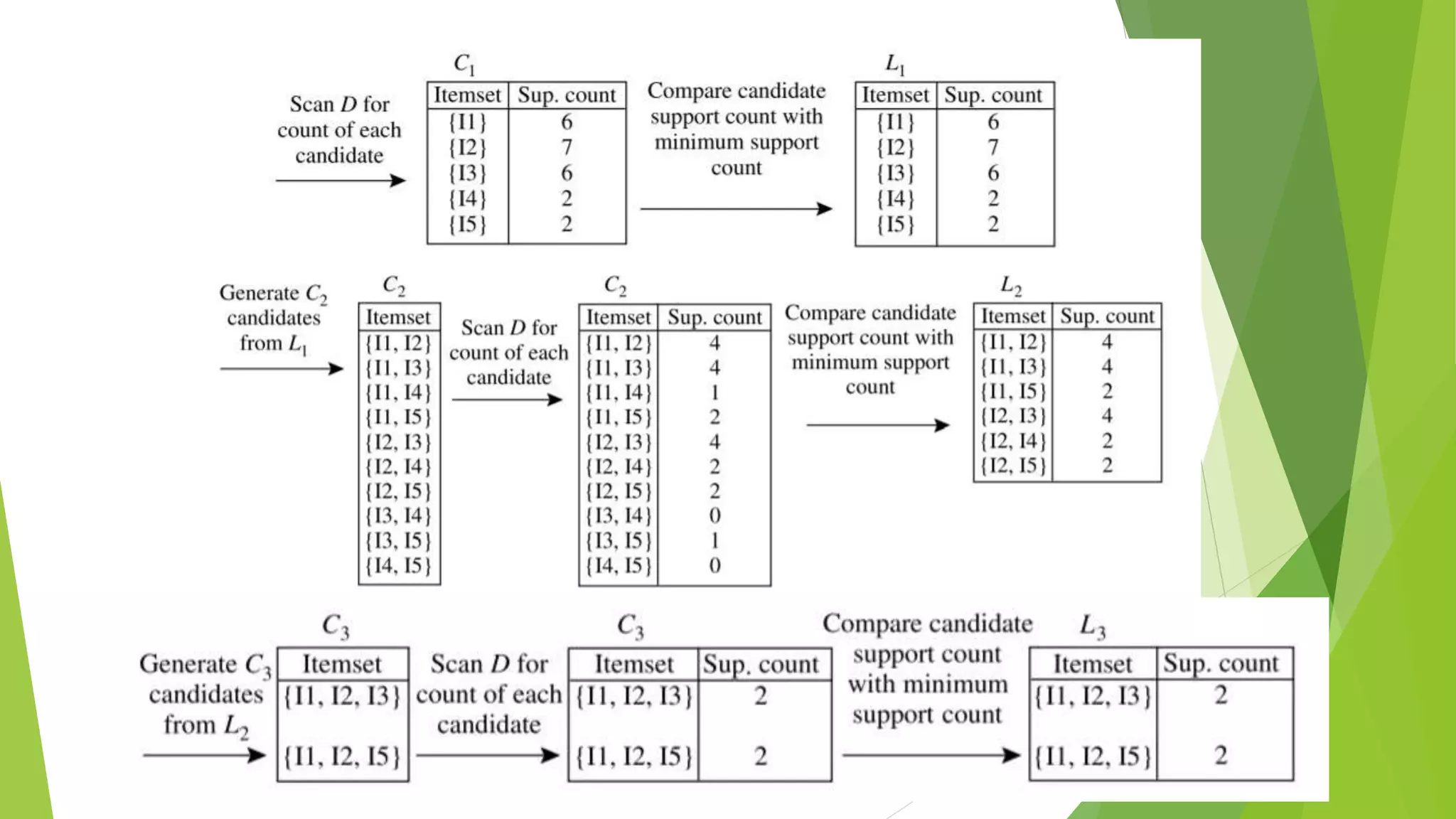
This document discusses frequent pattern mining and association rule learning. It begins by defining frequent patterns as patterns that occur frequently in a dataset. Apriori and FP-Growth are introduced as two popular algorithms for mining frequent itemsets and generating association rules. The document then provides more details on the concepts and implementation of these two algorithms. It explains how Apriori uses a generate-and-test approach with candidate generation while FP-Growth adopts a pattern growth method to avoid candidate generation. Examples are also given to illustrate how each algorithm works step-by-step.

![2
What Is Frequent Pattern Analysis?
Frequent pattern: a pattern (a set of items, subsequences,
substructures, etc.) that occurs frequently in a data set
First proposed by Agrawal, Imielinski, and Swami [AIS93] in the context
of frequent itemsets and association rule mining
Motivation: Finding inherent regularities in data
What products were often purchased together?— Milk and Bread ?!
What are the subsequent purchases after buying a PC?
Can we automatically classify web documents?
Applications
Basket data analysis, cross-marketing, catalog design, sale campaign
analysis etc](https://image.slidesharecdn.com/unit3-230320163126-916da568/75/Unit-3-pptx-2-2048.jpg)