Download as PDF, PPTX




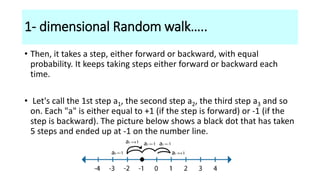
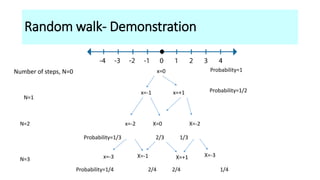




![Consider a drunkard whose motion is confined to the X-axis. For simplicity let us assume that
after every unit of time, he moves one step either to the right or to the left with probabilities p
and q respectively.
If he starts at the origin, how far his typical distance after N units of time have elapsed?
OR
What is the probability [PN(m)] that drunkard is at coordinate m?
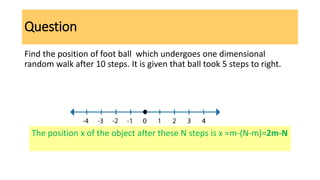
Question
Answer
N=n1+n2
m =n1-n2
Let n1 be the number of steps to the right, n2 be the number of steps to left,](https://image.slidesharecdn.com/1-230130062915-0609e5d6/85/1-Random-walk-pdf-15-320.jpg)













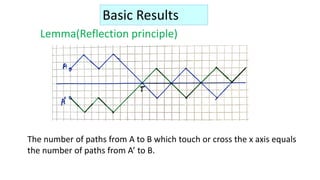










The document discusses the concept of random walks, including definitions, mathematical foundations, and applications in various fields such as physics and biology. It details one-dimensional and multi-dimensional random walks, Brownian motion, and the probabilities associated with different paths taken during the walk. Additionally, it covers generating functions and their role in understanding random walks and makes references to notable principles such as the ballot theorem.













































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)




