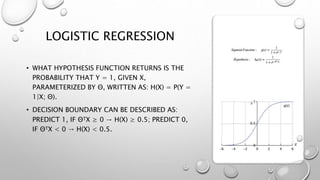
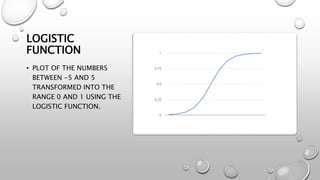
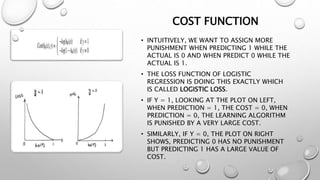
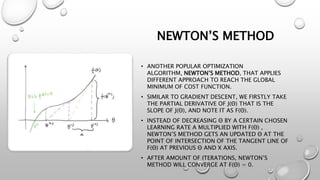
Logistic regression is a machine learning classification algorithm that predicts the probability of a categorical dependent variable. It models the probability of the dependent variable being in one of two possible categories, as a function of the independent variables. The model transforms the linear combination of the independent variables using the logistic sigmoid function to output a probability between 0 and 1. Logistic regression is optimized using maximum likelihood estimation to find the coefficients that maximize the probability of the observed outcomes in the training data. Like linear regression, it makes assumptions about the data being binary classified with no noise or highly correlated independent variables.