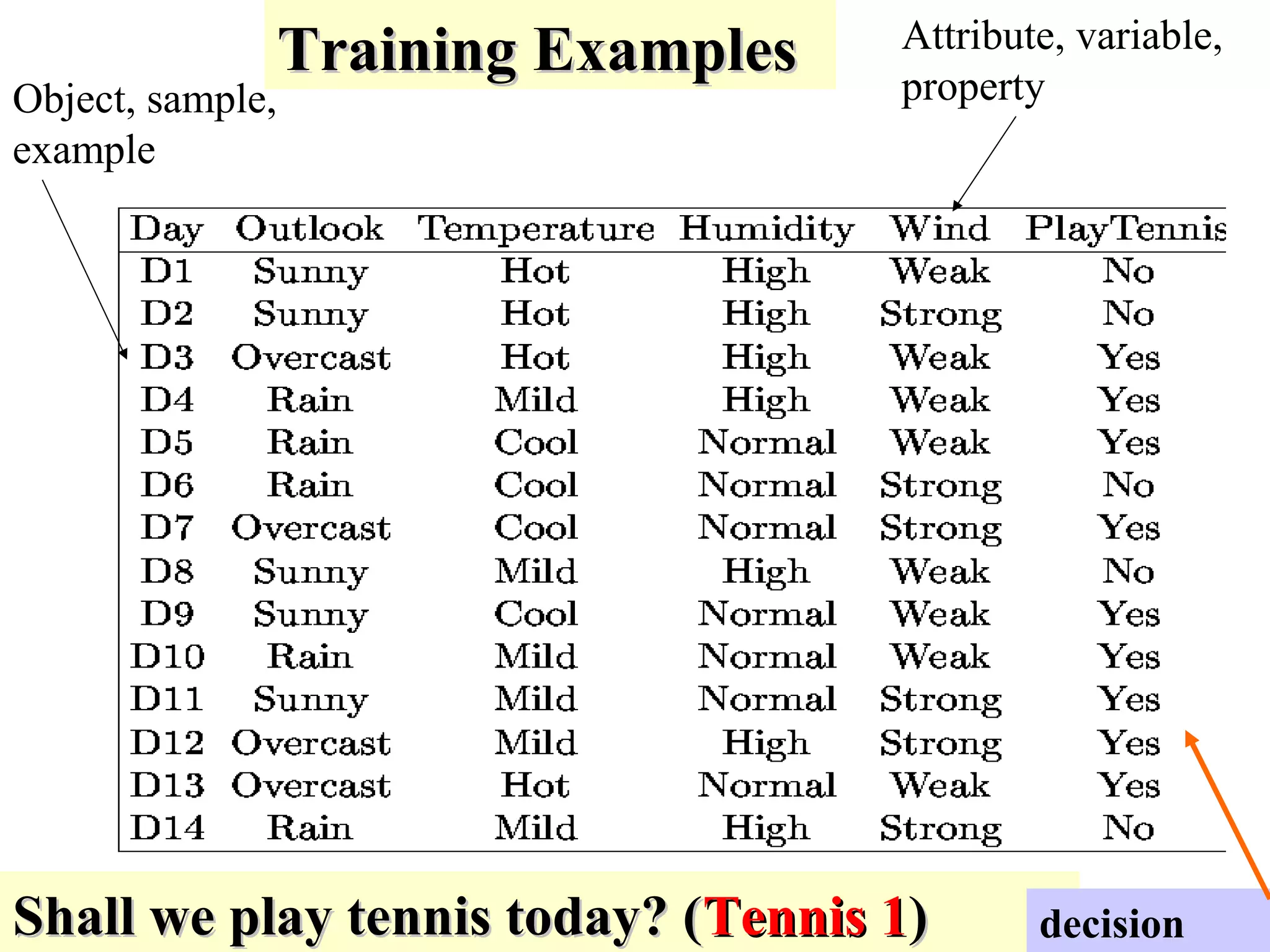
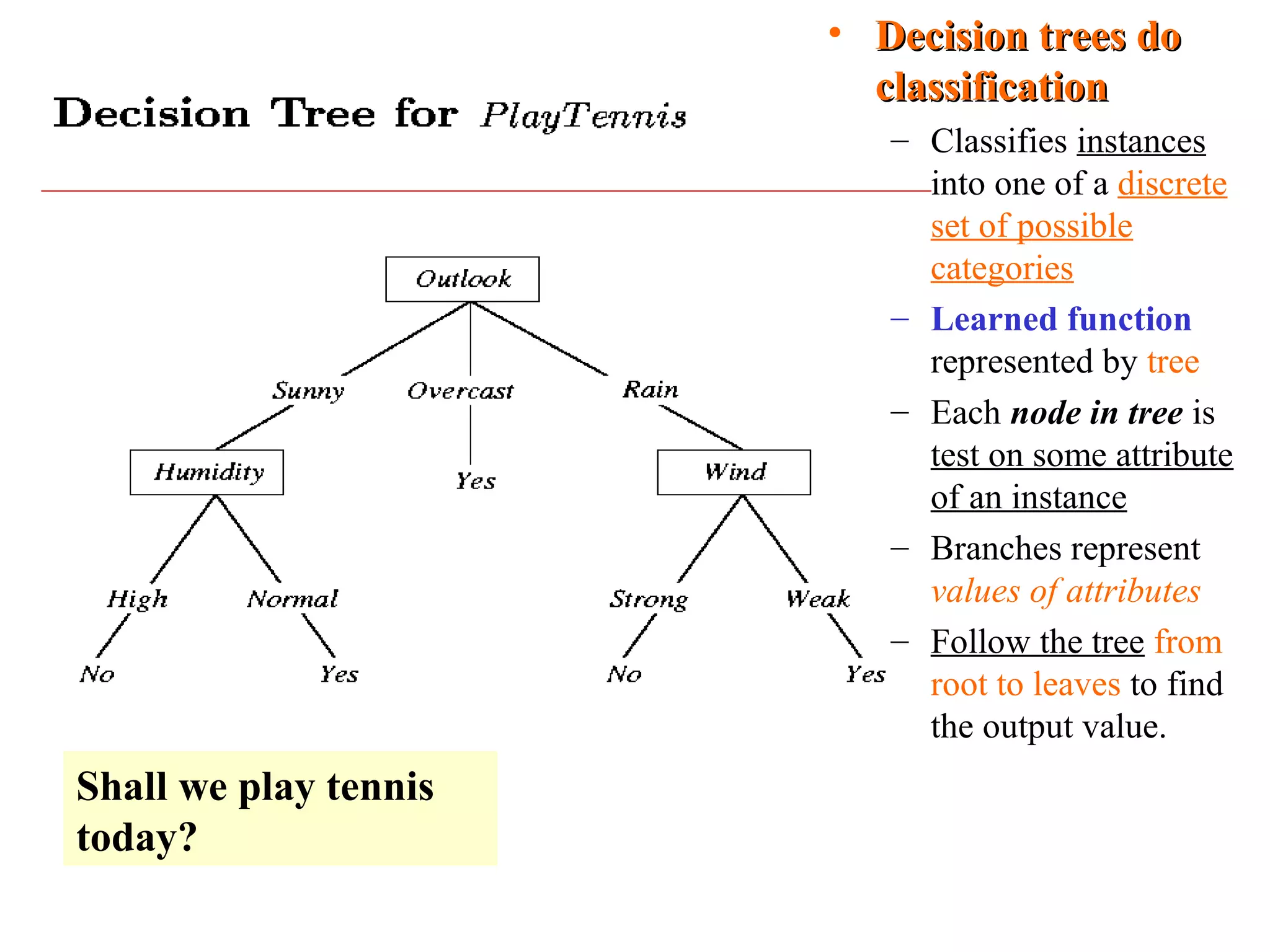
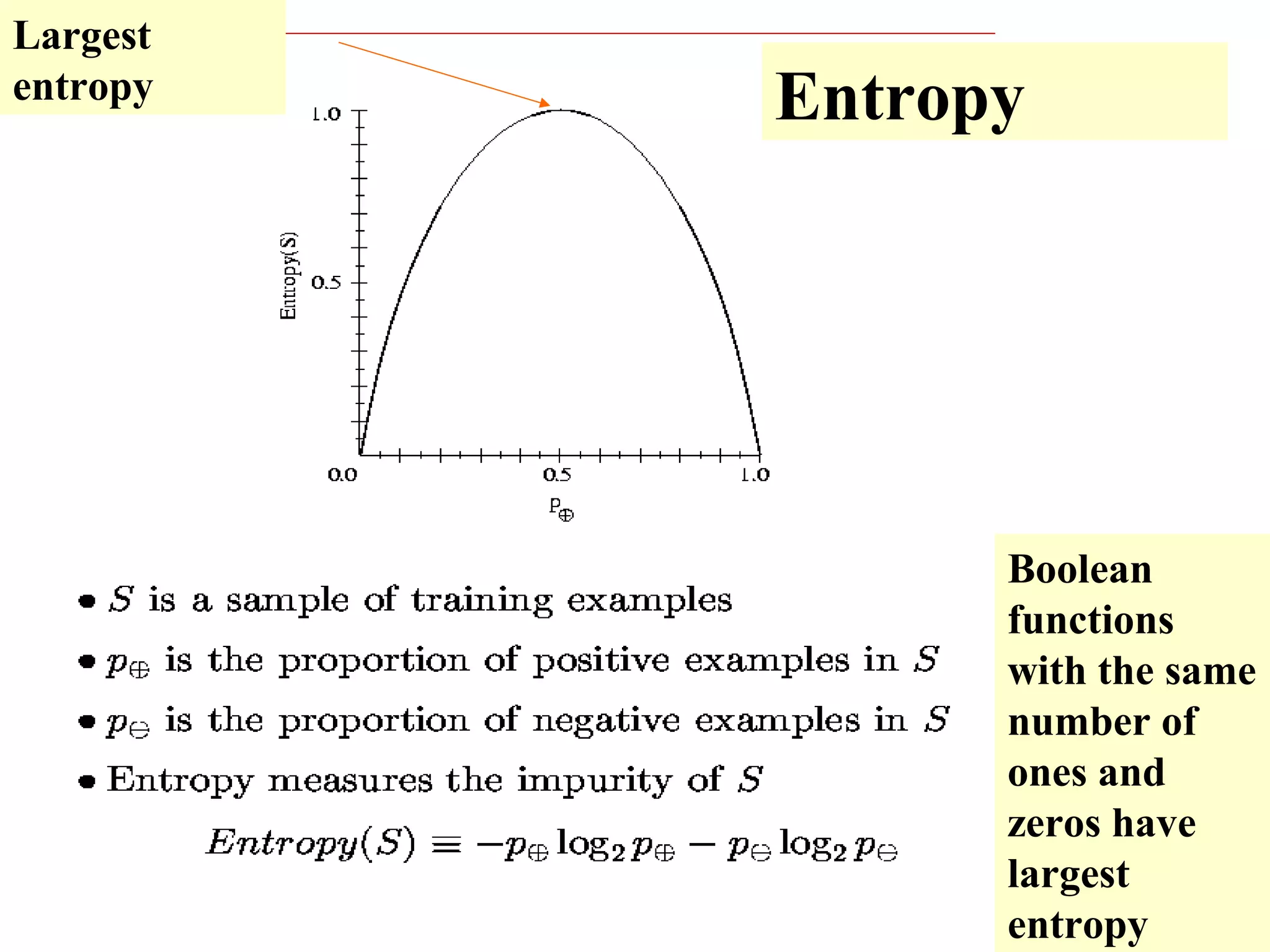
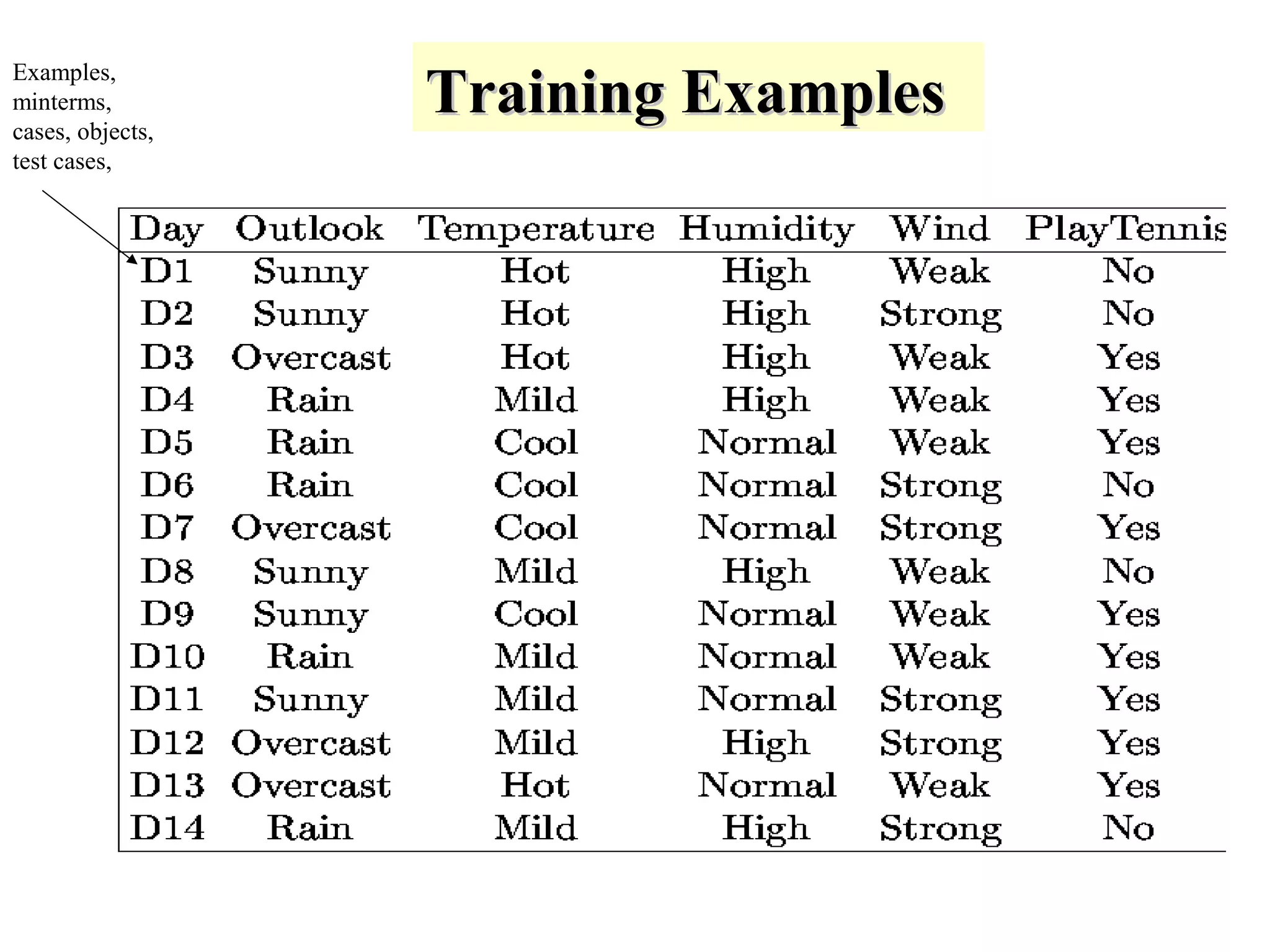
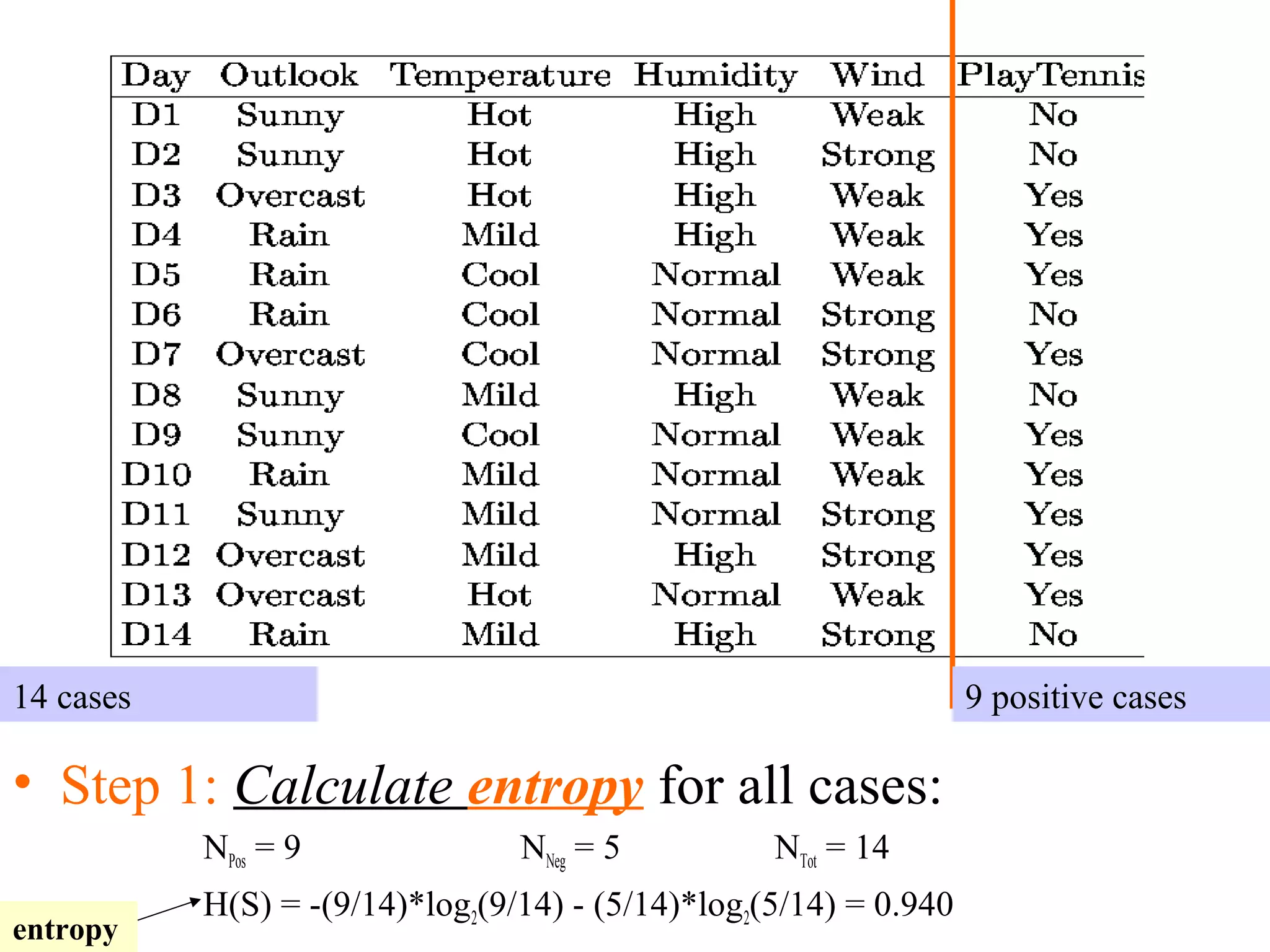
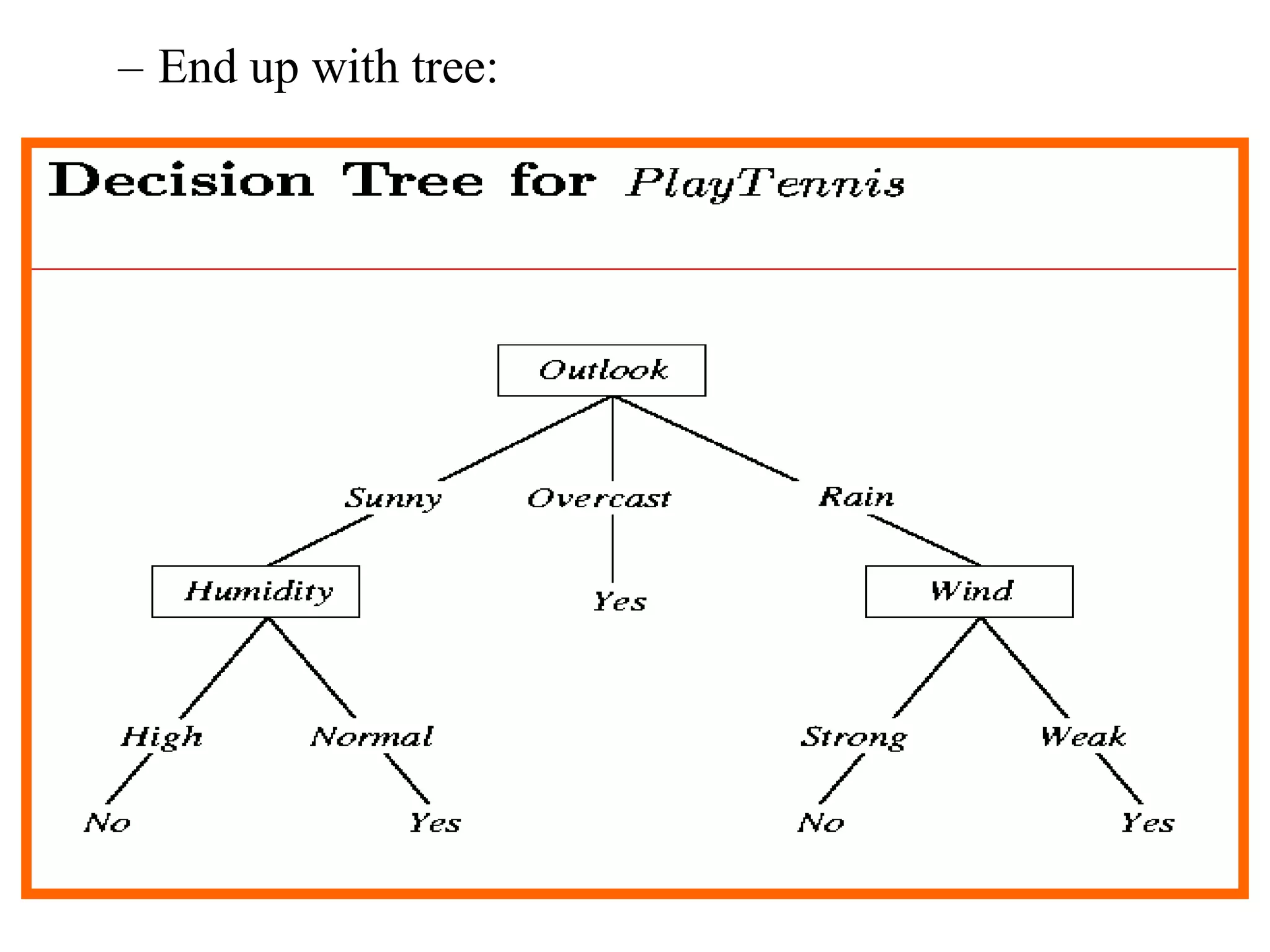
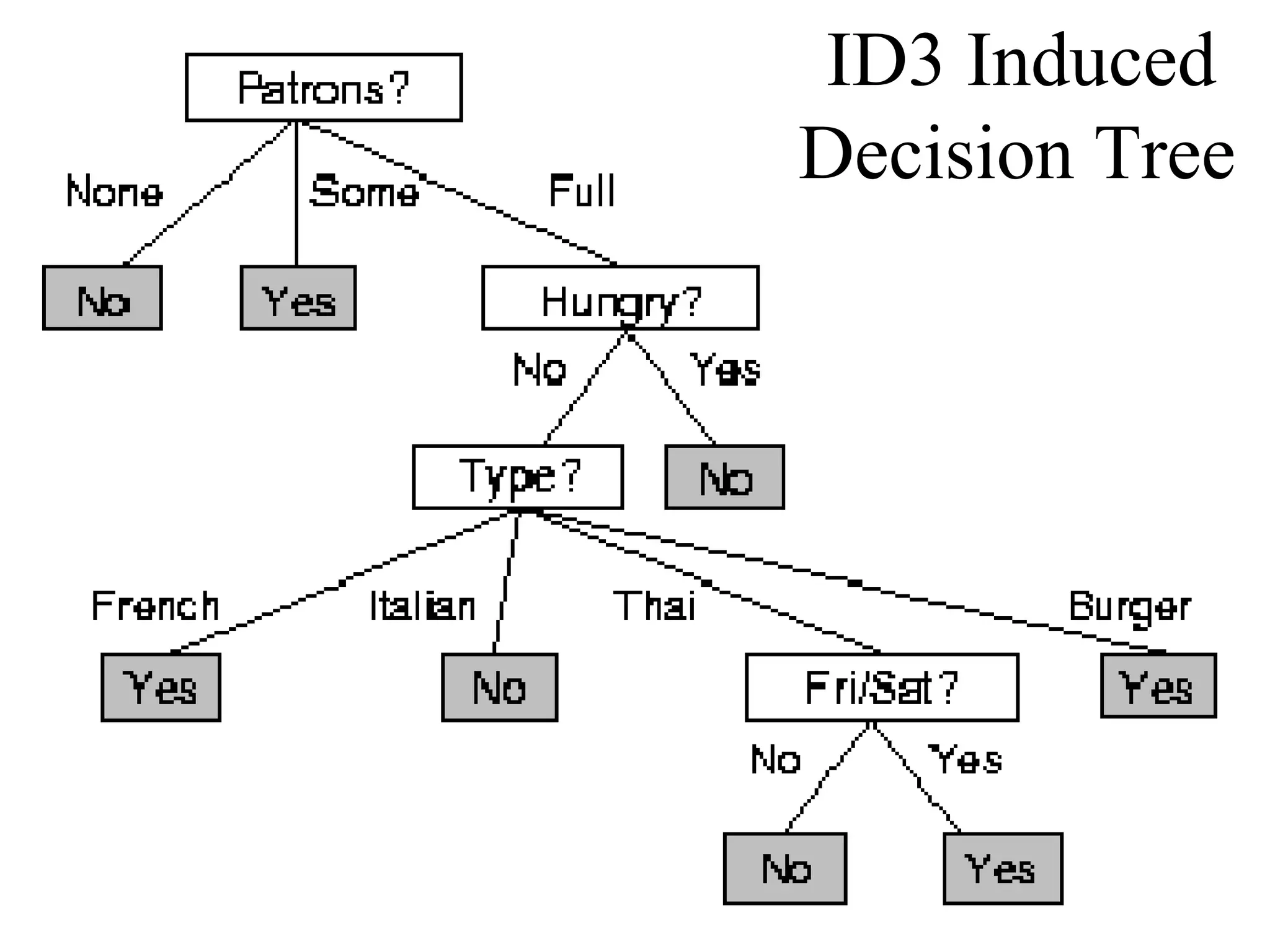
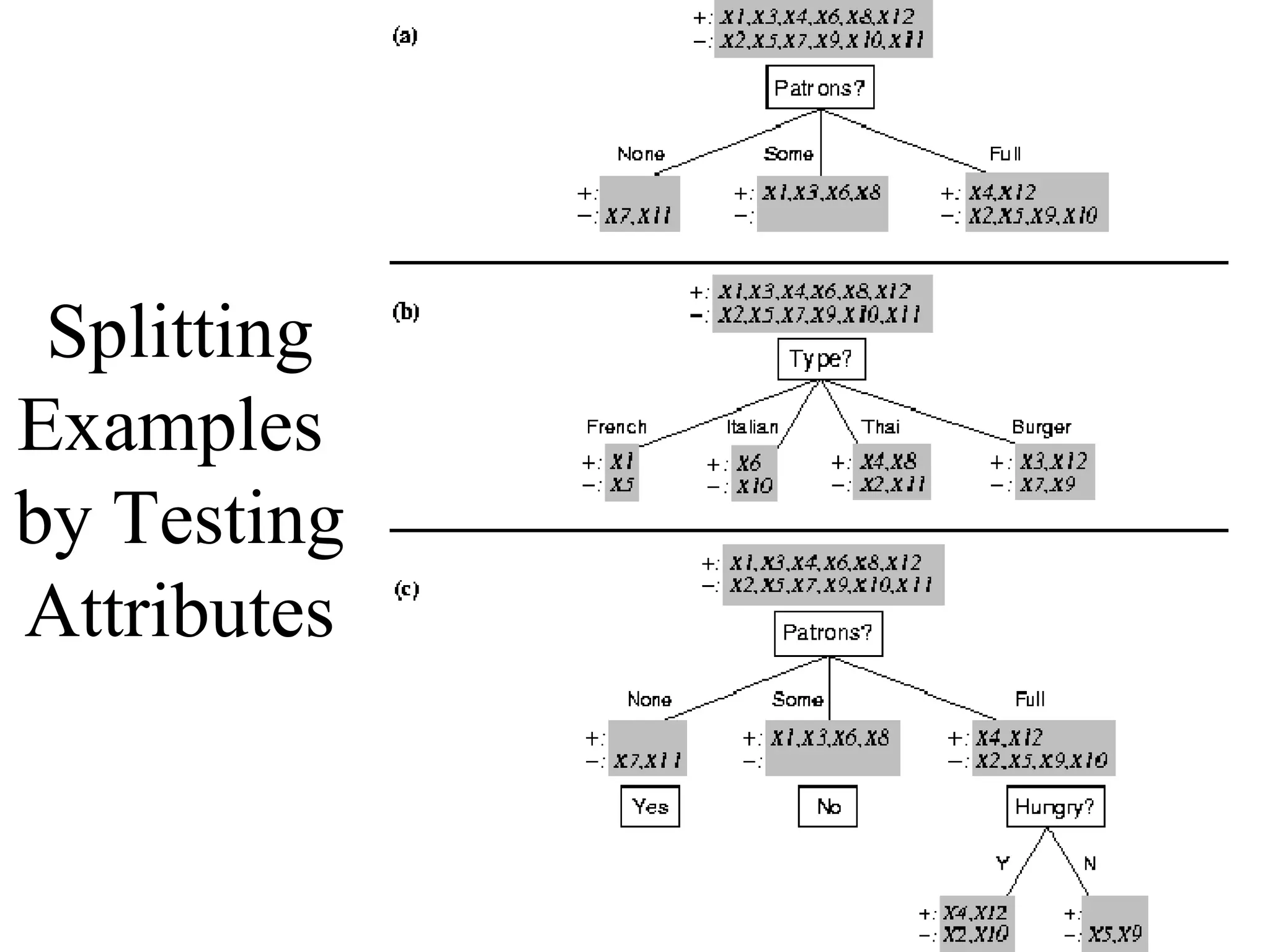
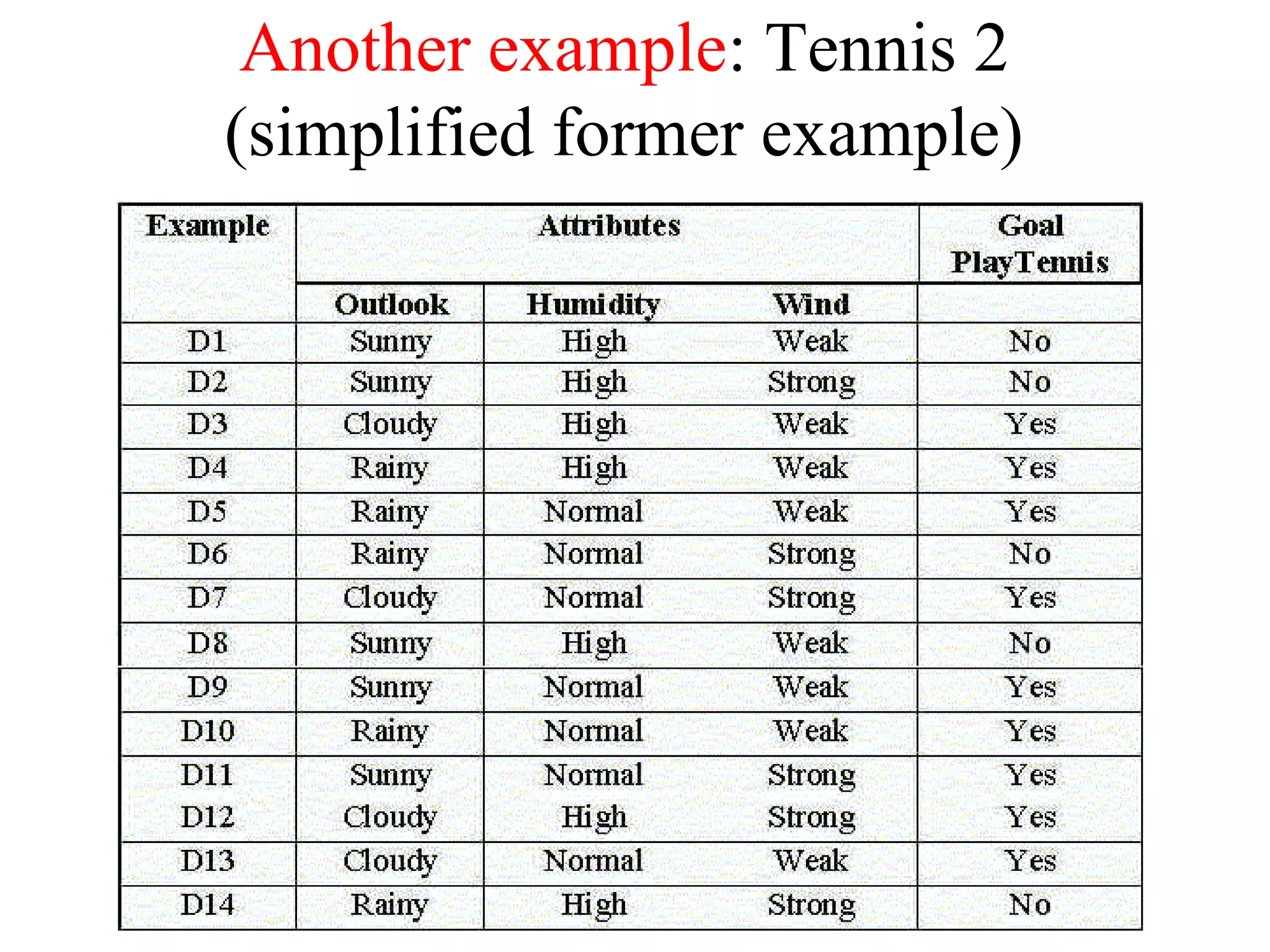
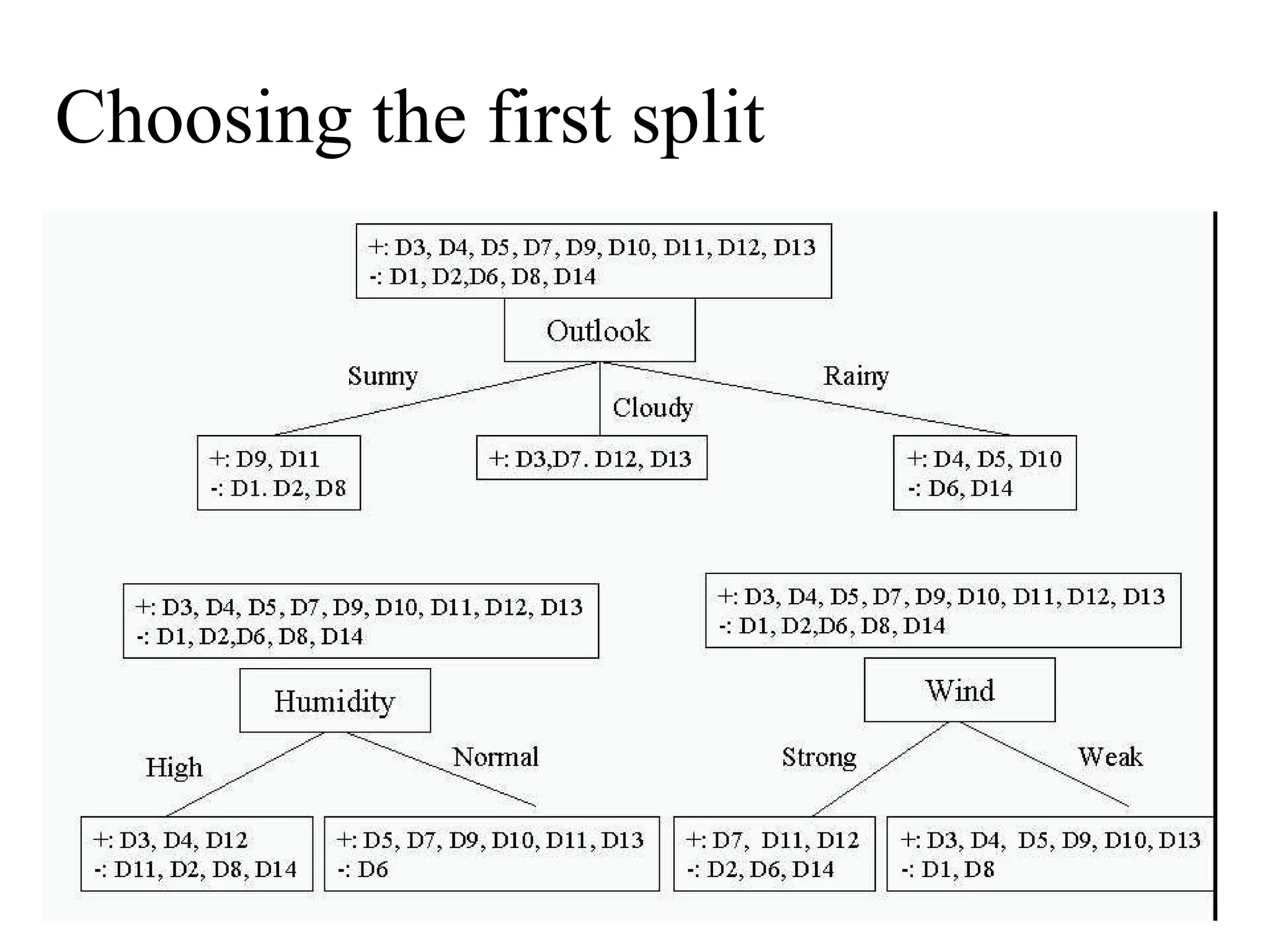
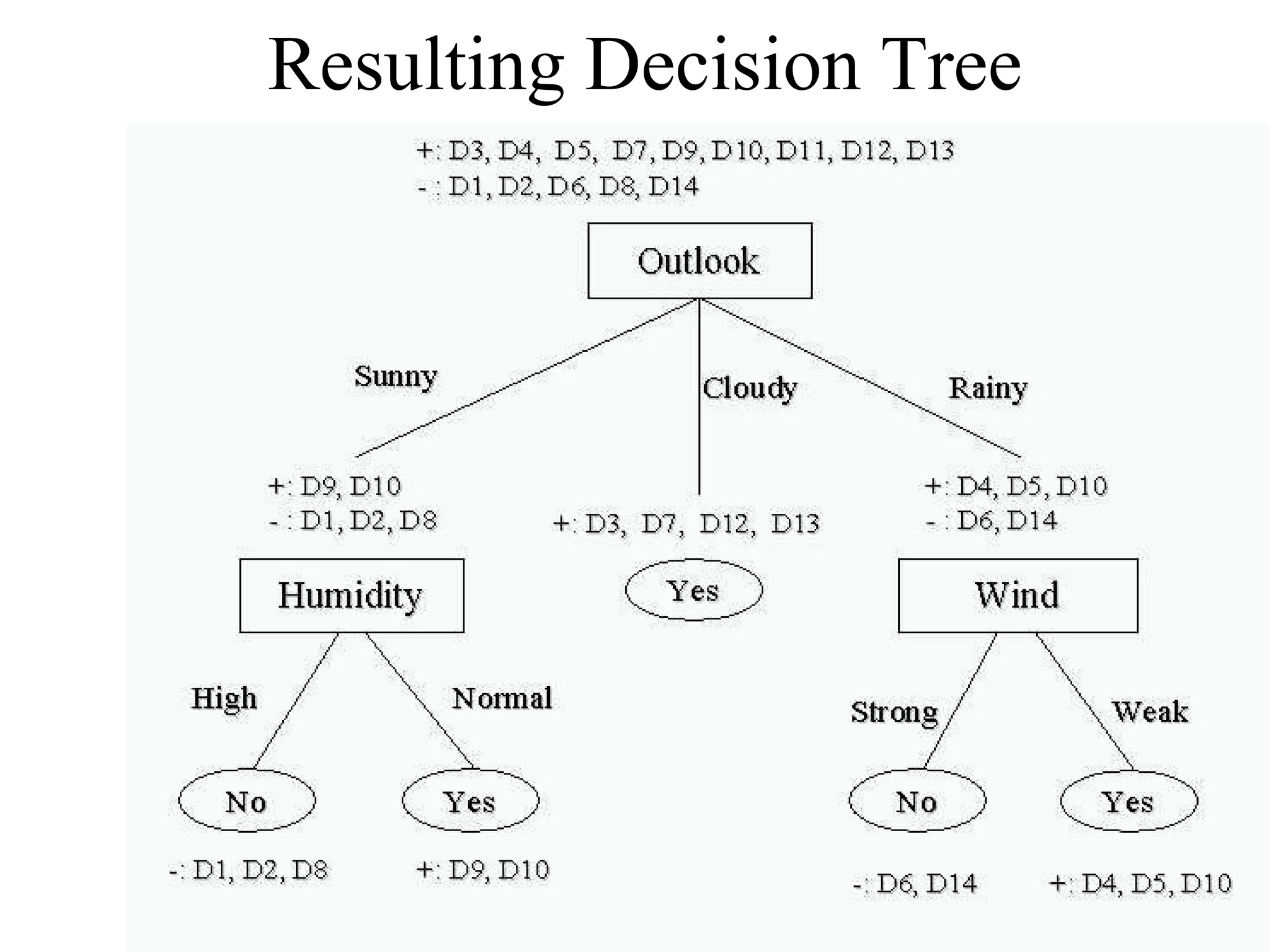
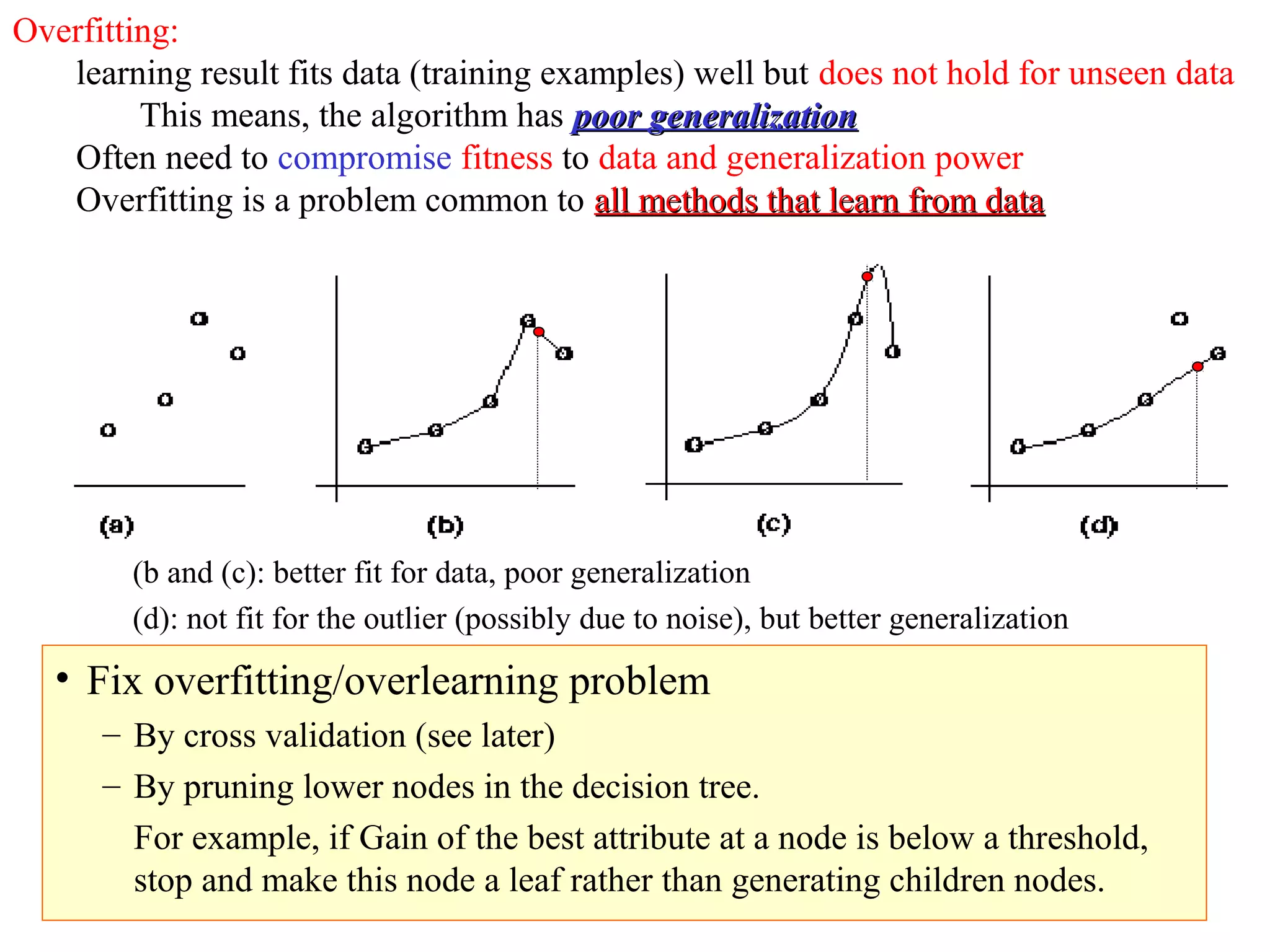
The document discusses decision tree learning, which is a machine learning approach for classification that builds classification models in the form of a decision tree. It describes the ID3 algorithm, which is a popular method for generating a decision tree from a set of training data. The ID3 algorithm uses information gain as the splitting criterion to recursively split the training data into purer subsets based on the values of the attributes. It selects the attribute with the highest information gain to make decisions at each node in the tree. Entropy from information theory is used to measure the information gain, with the goal being to build a tree that best classifies the training instances into target classes. An example applying the ID3 algorithm to a tennis playing dataset is provided to illustrate






![The ID3 algorithm is used to build a decision tree, given a set of non-categorical attributes
C1, C2, .., Cn, the categorical attribute C, and a training set T of records.
function ID3 (R: a set of non-categorical attributes,
C: the categorical attribute,
S: a training set) returns a decision tree;
begin
If S is empty, return a single node with value Failure;
If every example in S has the same value for categorical
attribute, return single node with that value;
If R is empty, then return a single node with most
frequent of the values of the categorical attribute found in
examples S; [note: there will be errors, i.e., improperly
classified records];
Let D be attribute with largest Gain(D,S) among R’s attributes;
Let {dj| j=1,2, .., m} be the values of attribute D;
Let {Sj| j=1,2, .., m} be the subsets of S consisting
respectively of records with value dj for attribute D;
Return a tree with root labeled D and arcs labeled
d1, d2, .., dm going respectively to the trees
ID3(R-{D},C,S1), ID3(R-{D},C,S2) ,.., ID3(R-{D},C,Sm);
end ID3;](https://image.slidesharecdn.com/002-141201083131-conversion-gate01/75/002-decision-trees-9-2048.jpg)








































![– Homework Assignment
• Tom Mitchell’s software
See:
• http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-3/www/ml.html
• Assignment #2 (on decision trees)
• Software is at: http://www.cs.cmu.edu/afs/cs/project/theo-3/mlc/hw2/
– Compiles with gcc compiler
– Unfortunately, README is not there, but it’s easy to figure out:
» After compiling, to run:
dt [-s <random seed> ] <train %> <prune %> <test %> <SSV-format data file>
» %train, %prune, & %test are percent of data to be used for training, pruning &
testing. These are given as decimal fractions. To train on all data, use 1.0 0.0 0.0
– Data sets for PlayTennis and Vote are include with code.
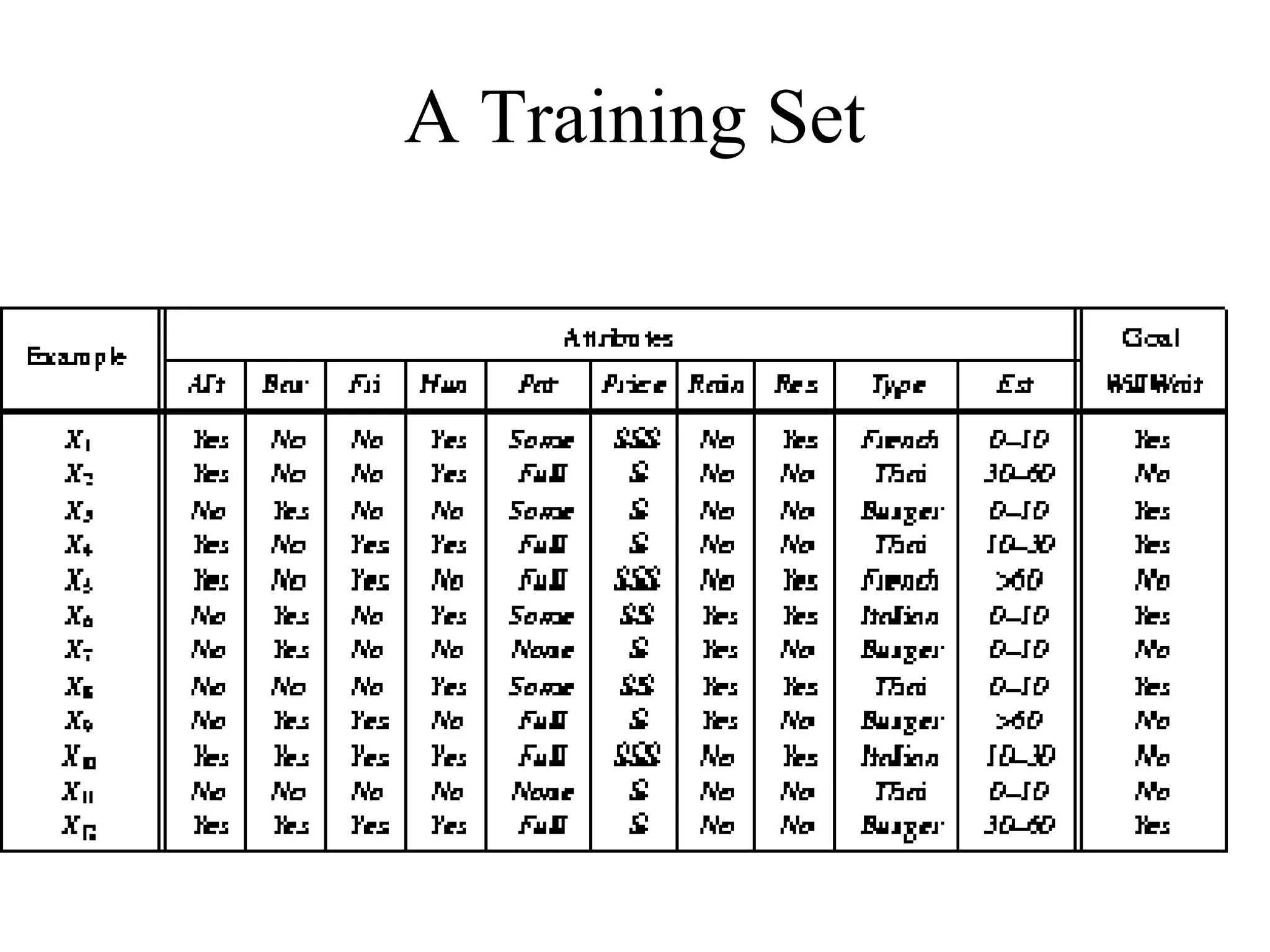
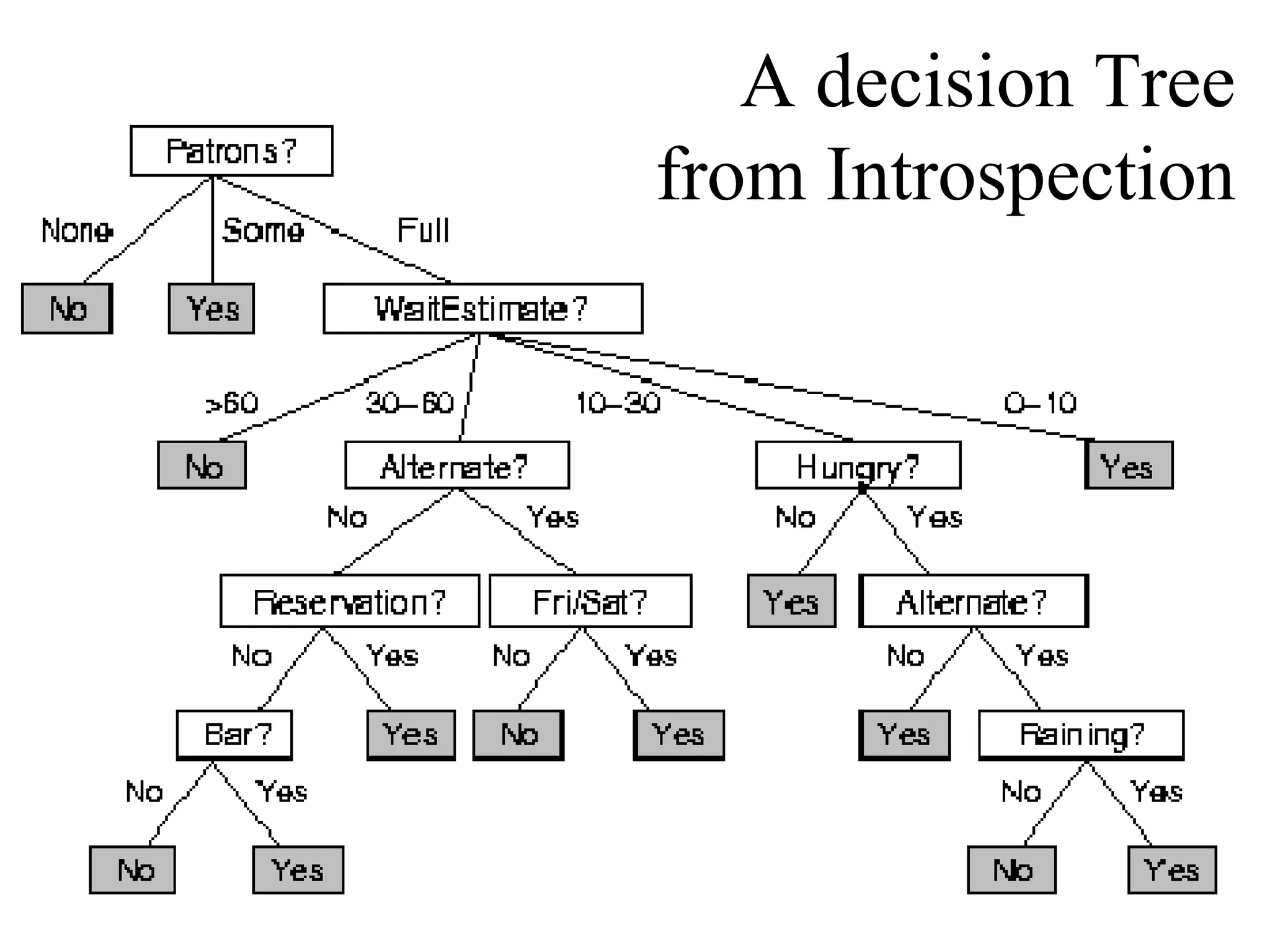
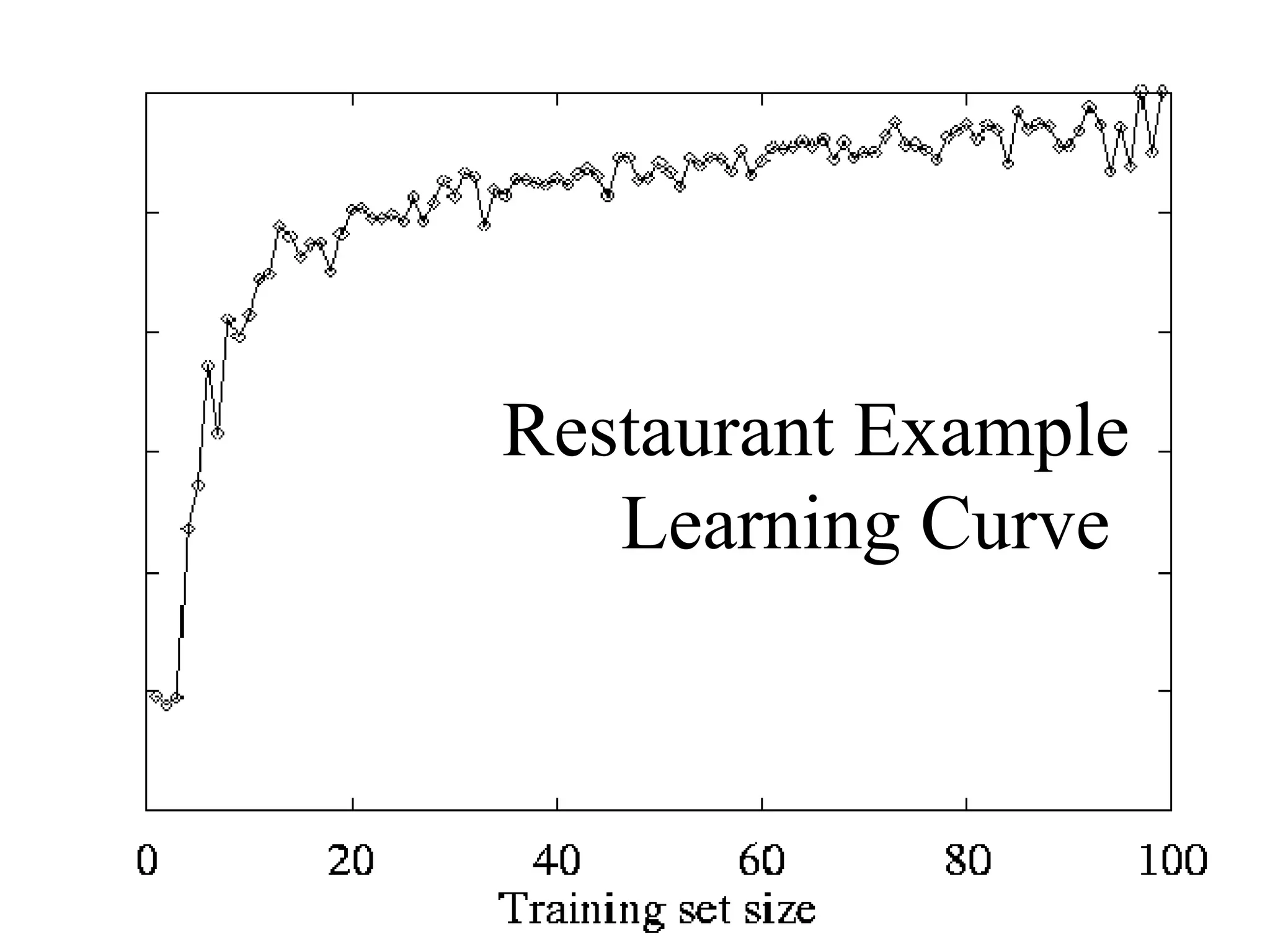
– Also try the Restaurant example from Russell & Norvig
– Also look at www.kdnuggets.com/ (Data Sets)
Machine Learning Database Repository at UC Irvine - (try “zoo” for fun)](https://image.slidesharecdn.com/002-141201083131-conversion-gate01/75/002-decision-trees-63-2048.jpg)















































![Ch 9-2.Machine Learning: Symbol-based[new]](https://cdn.slidesharecdn.com/ss_thumbnails/ch-92machine-learning-symbolbasednew4415-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
