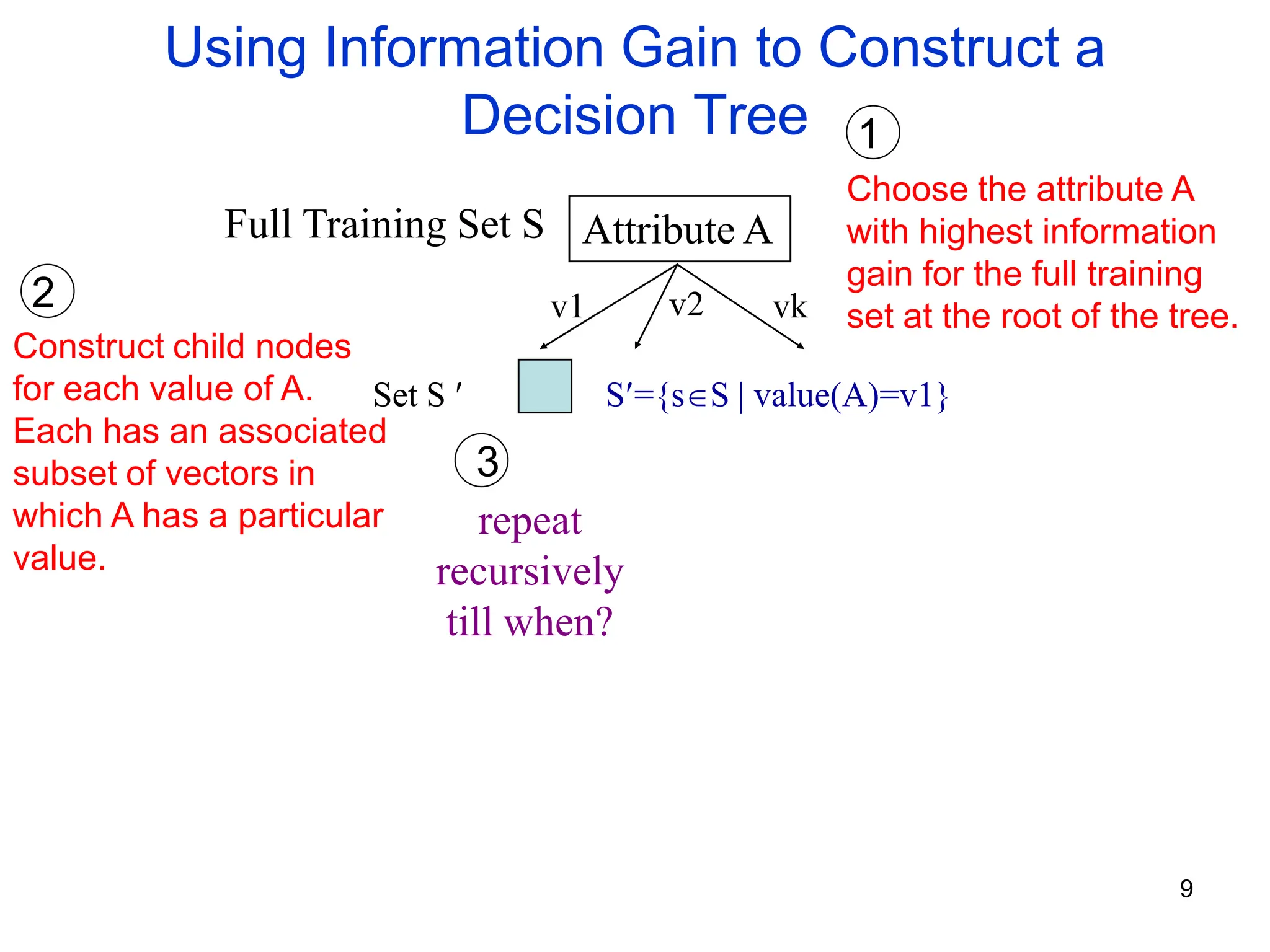
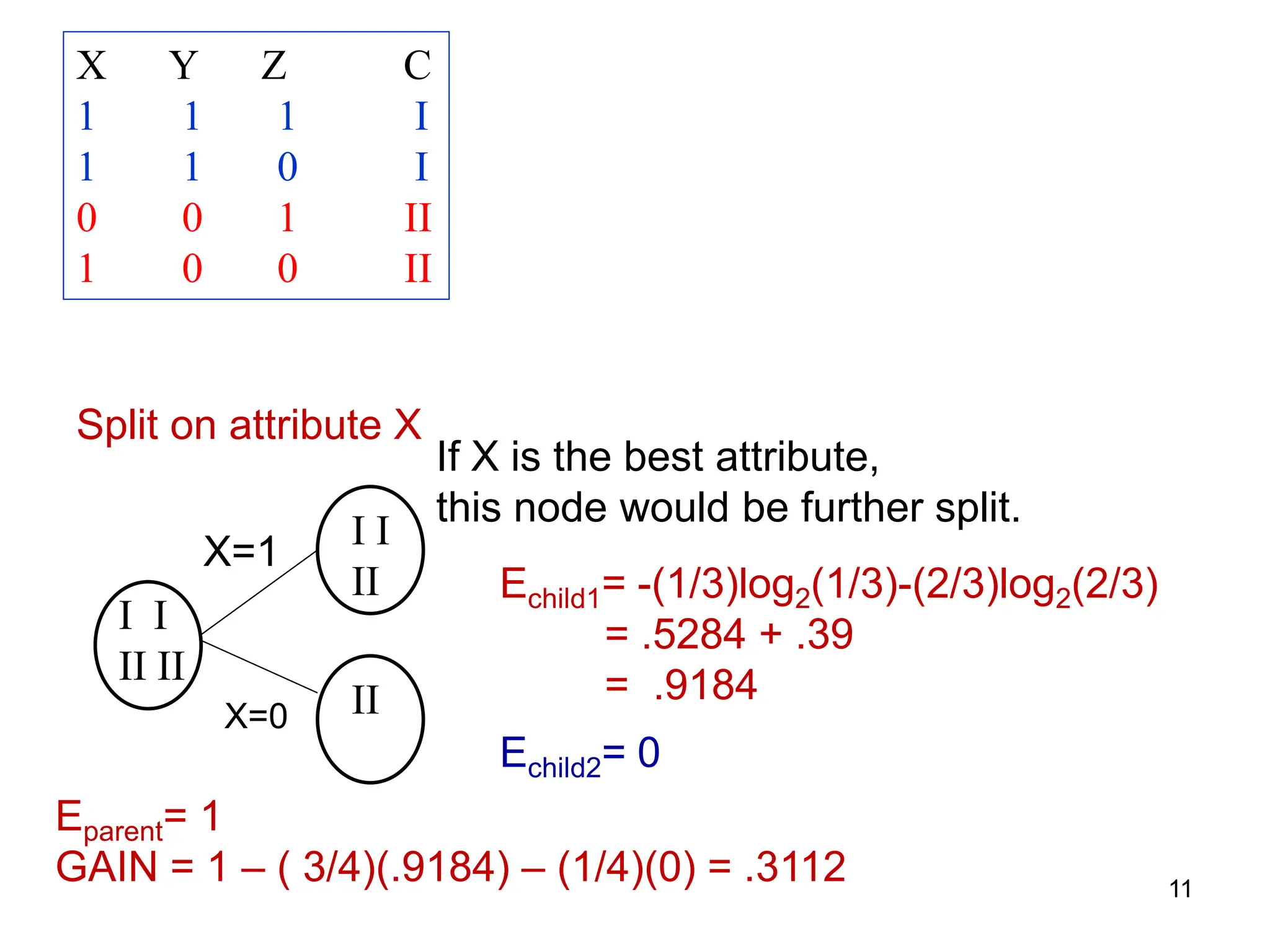
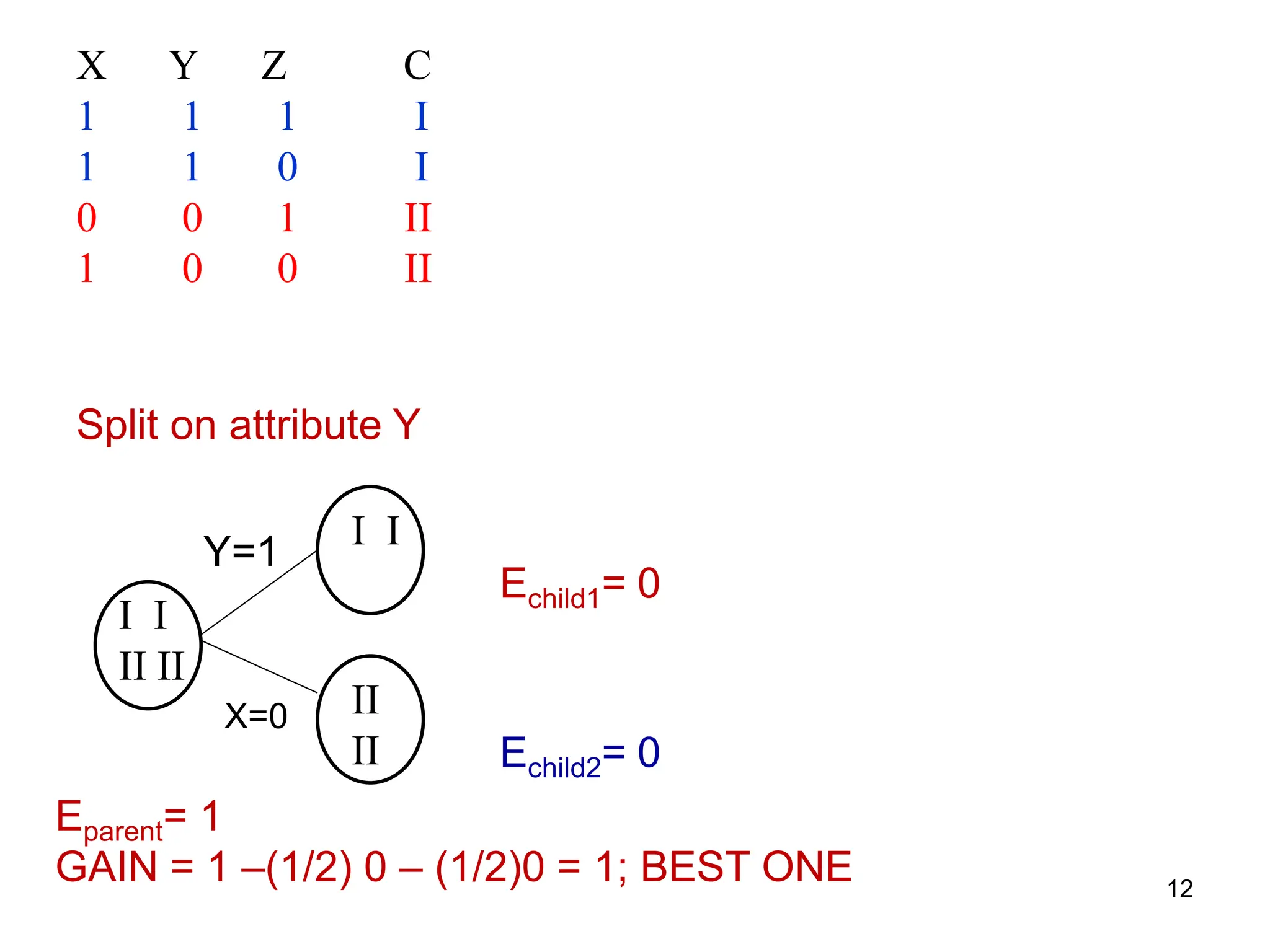
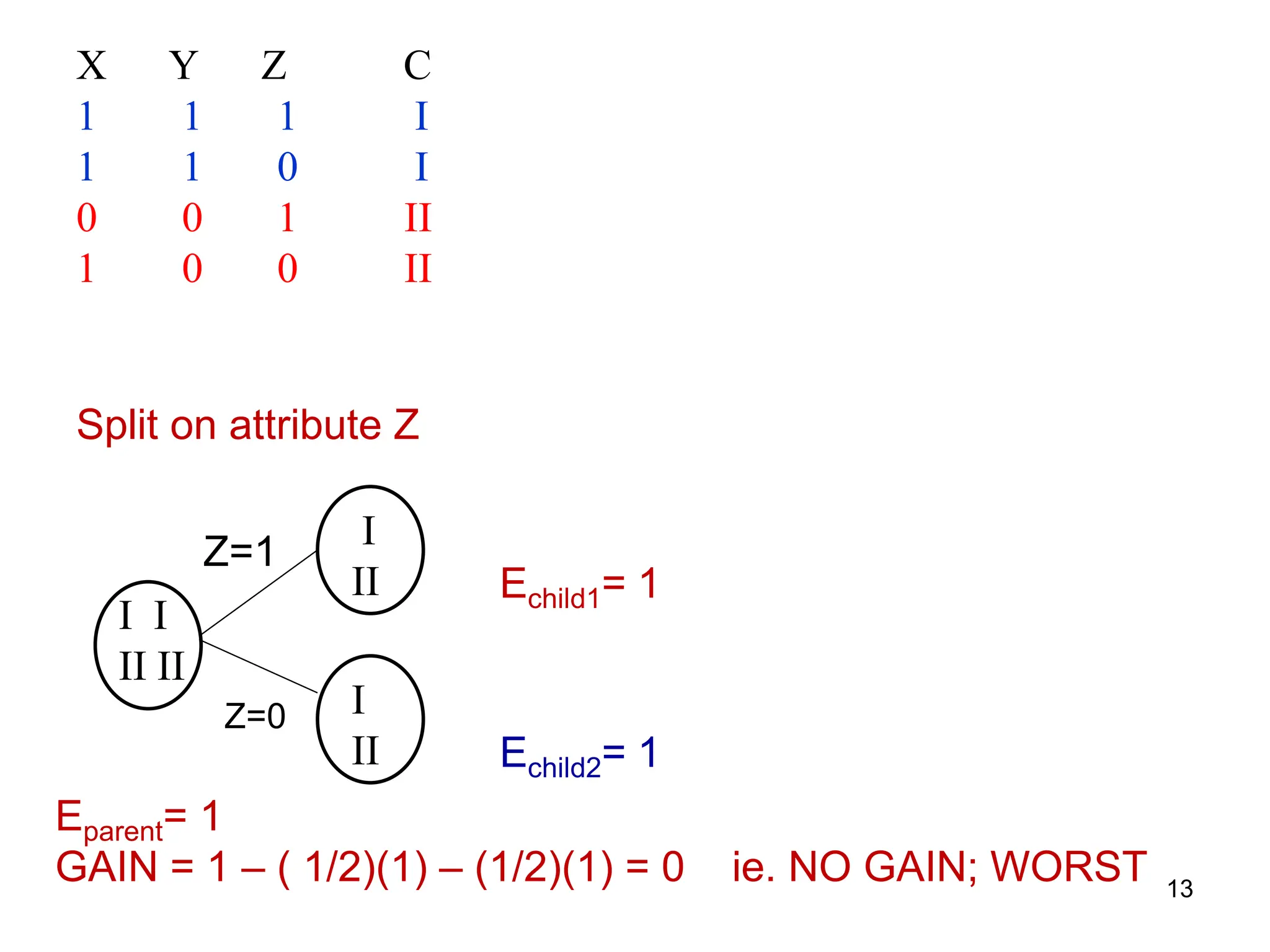
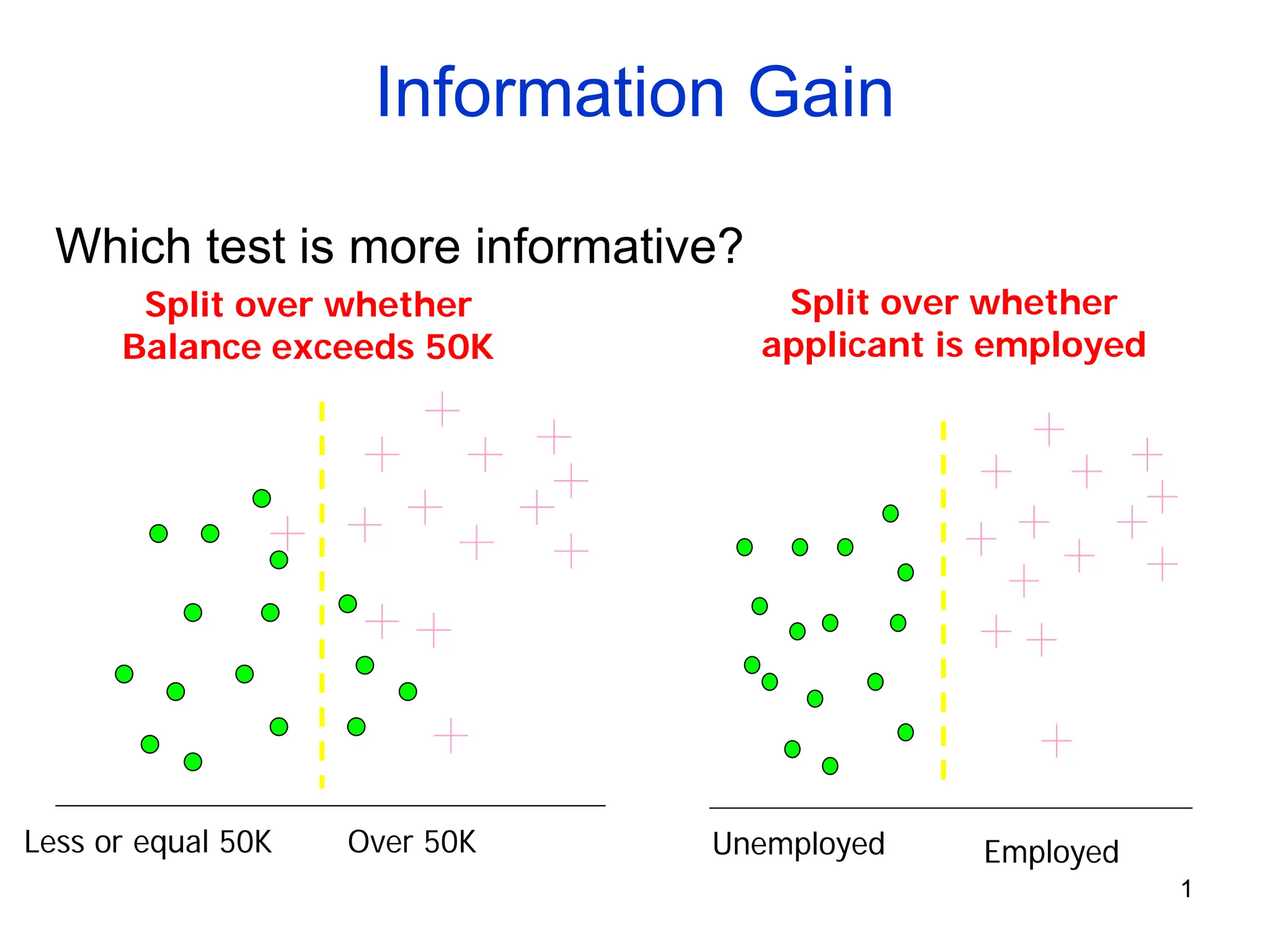
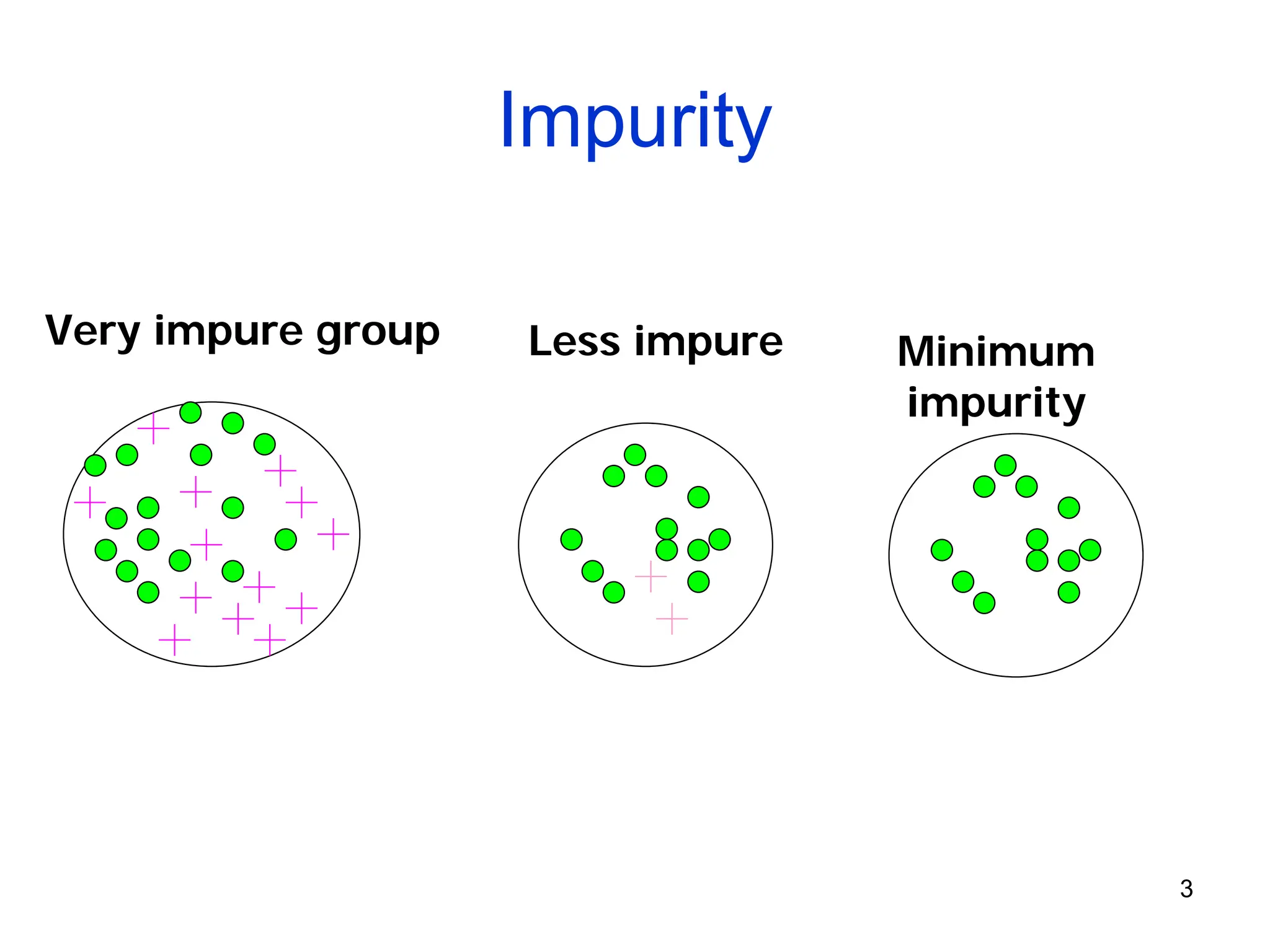
The document explains the concepts of entropy and information gain in the context of decision tree construction for machine learning. It details how entropy measures impurity in data sets and discusses calculating information gain to determine the most informative attributes for classification. Additionally, the document outlines a method for using information gain to recursively build a decision tree based on the training dataset.




![7
Calculating Information Gain
996
.
0
30
16
log
30
16
30
14
log
30
14
2
2 =
⋅
−
⋅
−
787
.
0
17
4
log
17
4
17
13
log
17
13
2
2 =
⋅
−
⋅
−
Entire population (30 instances)
17 instances
13 instances
(Weighted) Average Entropy of Children = 615
.
0
391
.
0
30
13
787
.
0
30
17
=
⋅
+
⋅
Information Gain= 0.996 - 0.615 = 0.38 for this split
391
.
0
13
12
log
13
12
13
1
log
13
1
2
2 =
⋅
−
⋅
−
Information Gain = entropy(parent) – [average entropy(children)]
parent
entropy
child
entropy
child
entropy](https://image.slidesharecdn.com/infogain-250117223408-5649c44f/75/Machine-Learning-course-Lecture-number-5-InfoGain-pdf-7-2048.jpg)