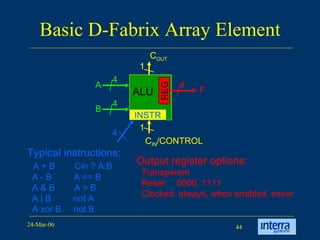
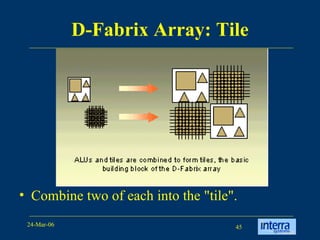
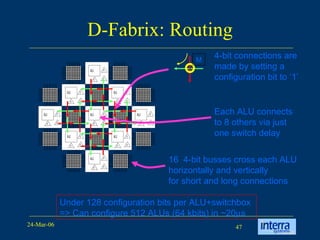
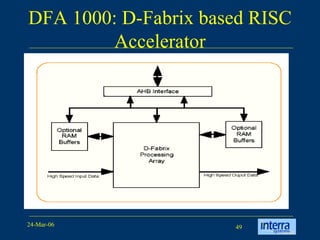
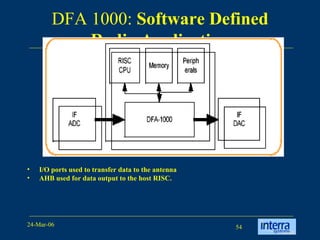
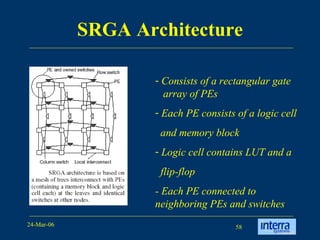
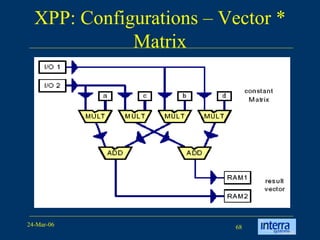
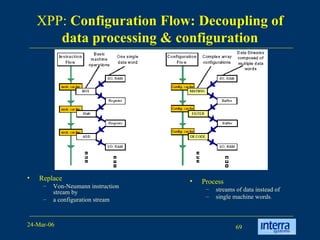
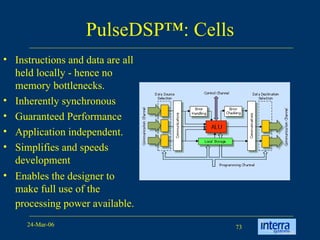
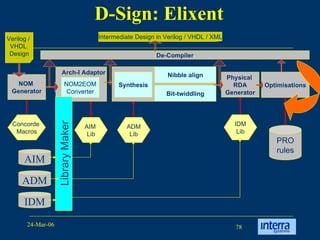
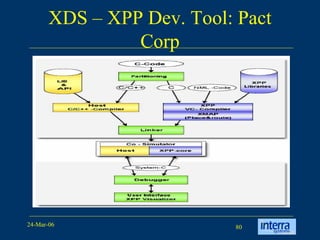
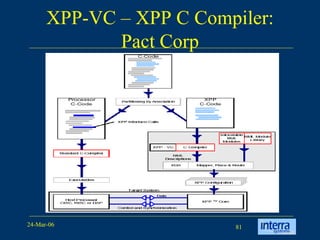
The document provides an overview of reconfigurable computing architectures. It discusses several leading companies in the field including Elixent, QuickSilver, Pact Corp, and Systolix. It then summarizes key reconfigurable computing architectures including D-Fabrix array, Adaptive Computing Machine (ACM), eXtreme Processing Platform (XPP), and PulseDSPTM. The ACM is based on QuickSilver's Self-Reconfigurable Gate Array (SRGA) architecture, which allows fast context switching and random access of the configuration memory.























































































































































![Handling Exceptions In C & C++ [Part B] Ver 2](https://cdn.slidesharecdn.com/ss_thumbnails/handlingexceptionsinccpartbver2-12659964132745-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![Handling Exceptions In C & C++[Part A]](https://cdn.slidesharecdn.com/ss_thumbnails/handlingexceptionsinccparta-1265996349797-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















