Download as PDF, PPTX





























![54
© 2019 Intel Corporation
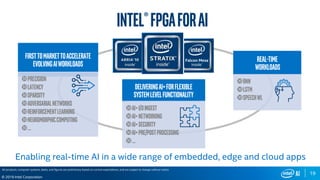
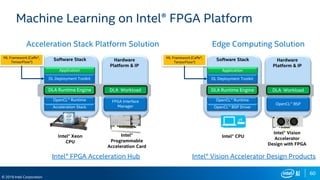
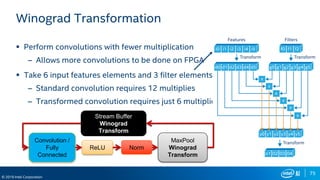
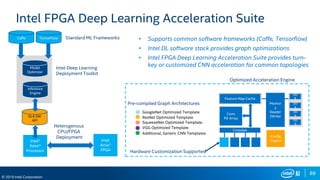
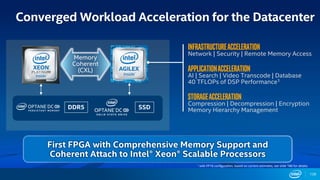
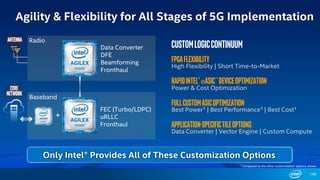
FPGA Flexibility Supports Arbitrary Architectures
Many efforts to improve efficiency
– Batching
– Reduce bit width
– Sparse weights
– Sparse activations
– Weight sharing
– Compact network
I W O
I
X
W
=
···
···
O
2
3
3 2
1 3
13
1
3
Shared Weights
SparseCNN
[CVPR’15]
Spatially SparseCNN
[CIFAR-10 winner ‘14]
Pruning
[NIPS’15]
TernaryConnect
[ICLR’16]
BinaryConnect
[NIPS’15]
DeepComp
[ICLR’16]
HashedNets
[ICML’15]
XNORNet
SqueezeNet
LeNet
[IEEE}
AlexNet
[ILSVRC’12}
VGG
[ILSVRC’14}
GoogleNet
[ILSVRC’14}
ResNet
[ILSVRC’15}](https://image.slidesharecdn.com/atpesc2019track-187-29330pmmoawadnash-fpgas-200116154051/85/FPGAs-and-Machine-Learning-53-320.jpg)


















![101
© 2019 Intel Corporation
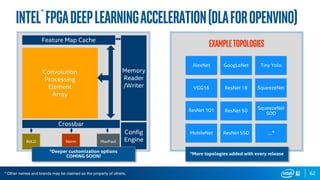
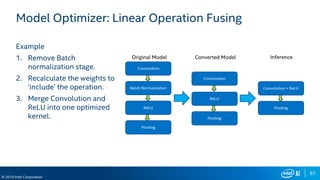
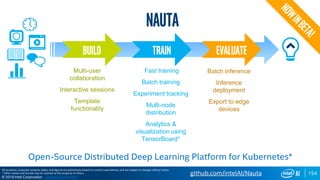
Run Model Optimizer
To generate IR .xml and .bin files for Inference Engine
$ source $MO_DIR/venv/bin/activate
$ cd $MO_DIR/
$ python mo.py
--input_model <model dir>/<weights>.caffemodel
--scale 1
--data_type FP16
--output_dir <output dir>
Model Optimizer arguments
Batch: 1
Precision of IR: FP16
Enable fusing: True
Enable gfusing: True
…
[ SUCCESS ] Generated IR model.
[ SUCCESS ] XML file: …
[ SUCCESS ] BIN file: …](https://image.slidesharecdn.com/atpesc2019track-187-29330pmmoawadnash-fpgas-200116154051/85/FPGAs-and-Machine-Learning-100-320.jpg)





















































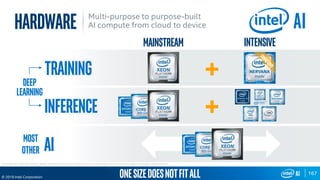














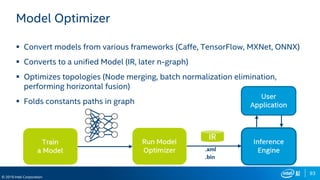
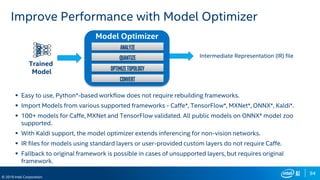
The document outlines Intel's advancements in AI, machine learning, and deep learning across various sectors, emphasizing the need for diverse hardware architectures to meet increasing computing demands. It discusses tools and frameworks like OpenVINO, Intel’s deep learning acceleration suite, and highlights the performance variances in systems contingent on configurations. Additionally, it notes that optimizations are primarily intended for Intel processors and may not guarantee results on other non-Intel microprocessors.























































































