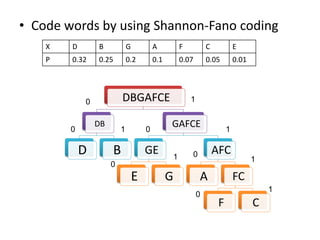
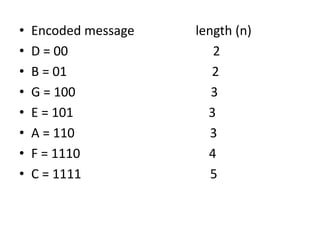
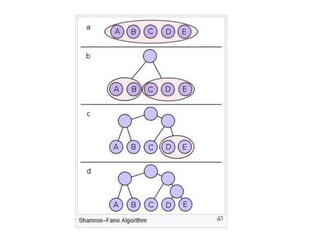
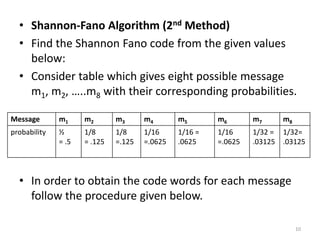
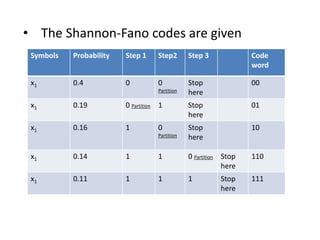
The document provides a detailed explanation of Shannon-Fano coding, a method for constructing prefix codes based on symbols and their probabilities, aimed at data compression. It outlines the algorithm for generating codes, including the process of sorting symbols, partitioning sets, and assigning binary digits. Additionally, it discusses calculating average codeword lengths and code efficiency, using various examples to illustrate the application of the Shannon-Fano method.










![Average codeword length (L)
Average codeword length L is given by,
L =
Where Pk = probability of kth message
mk = kth message
In the example discussed so far.
L = (1/2 X 1) + [(1/8 X 3)X 2] + [(1/16 X 4) X
3] + [(1/32 X 5) X2]
L = 2.3125 bits/message
13](https://image.slidesharecdn.com/11lecture11shanonfanocoding-170828063840/85/Data-Communication-Computer-network-Shanon-fano-coding-13-320.jpg)













![• H =
= - [0.1 log 0.1 + 0.25 log 0.25 + 0.05 log 0.05 +
0.32 log 0.32 + 0.01 log 0.01 + 0.07 log 0.07 +
0.2 log 0.2]
= 0.714 bits/message
7
1
kPlog
k
kP](https://image.slidesharecdn.com/11lecture11shanonfanocoding-170828063840/85/Data-Communication-Computer-network-Shanon-fano-coding-28-320.jpg)