Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
hoxo_m
190,996 views
機械学習のためのベイズ最適化入門
db analytics showcase Sapporo 2017 発表資料 http://www.db-tech-showcase.com/dbts/analytics
Data & Analytics
◦
Read more
161
Save
Share
Embed
Embed presentation
1
/ 67
2
/ 67
3
/ 67
4
/ 67
5
/ 67
6
/ 67
7
/ 67
8
/ 67
9
/ 67
10
/ 67
11
/ 67
12
/ 67
13
/ 67
14
/ 67
15
/ 67
16
/ 67
17
/ 67
18
/ 67
19
/ 67
20
/ 67
21
/ 67
22
/ 67
23
/ 67
24
/ 67
25
/ 67
26
/ 67
27
/ 67
28
/ 67
29
/ 67
30
/ 67
31
/ 67
32
/ 67
33
/ 67
34
/ 67
35
/ 67
36
/ 67
37
/ 67
38
/ 67
39
/ 67
40
/ 67
41
/ 67
42
/ 67
43
/ 67
44
/ 67
45
/ 67
46
/ 67
47
/ 67
48
/ 67
49
/ 67
50
/ 67
51
/ 67
52
/ 67
53
/ 67
54
/ 67
55
/ 67
56
/ 67
57
/ 67
58
/ 67
59
/ 67
60
/ 67
61
/ 67
62
/ 67
63
/ 67
64
/ 67
65
/ 67
Most read
66
/ 67
Most read
67
/ 67
Most read
More Related Content
PDF
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎
by
Preferred Networks
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PDF
PRML Chapter 14
by
Masahito Ohue
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎
by
Preferred Networks
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
変分ベイズ法の説明
by
Haruka Ozaki
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PRML Chapter 14
by
Masahito Ohue
What's hot
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
PDF
ベイズ最適化
by
MatsuiRyo
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
LDA入門
by
正志 坪坂
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
パターン認識と機械学習入門
by
Momoko Hayamizu
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
ベイズ最適化
by
MatsuiRyo
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
機械学習モデルのハイパパラメータ最適化
by
gree_tech
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
LDA入門
by
正志 坪坂
「世界モデル」と関連研究について
by
Masahiro Suzuki
劣モジュラ最適化と機械学習1章
by
Hakky St
多様な強化学習の概念と課題認識
by
佑 甲野
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
GAN(と強化学習との関係)
by
Masahiro Suzuki
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
報酬設計と逆強化学習
by
Yusuke Nakata
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
パターン認識と機械学習入門
by
Momoko Hayamizu
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
Viewers also liked
PDF
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
PDF
実践多クラス分類 Kaggle Ottoから学んだこと
by
nishio
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
PPTX
xtsパッケージで時系列解析
by
Nagi Teramo
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PPTX
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
PDF
岩波データサイエンス_Vol.5_勉強会資料02
by
goony0101
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
PPTX
Kaggle meetup #3 instacart 2nd place solution
by
Kazuki Onodera
PDF
Replica exchange MCMC
by
. .
PDF
Deep learning with C++ - an introduction to tiny-dnn
by
Taiga Nomi
PDF
ベアメタルクラウドの運用をJupyter NotebookとAnsibleで機械化してみた
by
Satoshi Yazawa
PDF
「深層学習」の本に出てきたデータセット達
by
Hiromasa Ohashi
PDF
Pycon2017
by
Yuta Kashino
PDF
D3.jsと学ぶVisualization(可視化)の世界
by
AdvancedTechNight
PDF
岩波データサイエンス_Vol.5_勉強会資料01
by
goony0101
PDF
岩波データサイエンス_Vol.5_勉強会資料00
by
goony0101
PDF
闇と向き合う
by
Nagi Teramo
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
実践多クラス分類 Kaggle Ottoから学んだこと
by
nishio
生成モデルの Deep Learning
by
Seiya Tokui
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
xtsパッケージで時系列解析
by
Nagi Teramo
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
岩波データサイエンス_Vol.5_勉強会資料02
by
goony0101
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
Kaggle meetup #3 instacart 2nd place solution
by
Kazuki Onodera
Replica exchange MCMC
by
. .
Deep learning with C++ - an introduction to tiny-dnn
by
Taiga Nomi
ベアメタルクラウドの運用をJupyter NotebookとAnsibleで機械化してみた
by
Satoshi Yazawa
「深層学習」の本に出てきたデータセット達
by
Hiromasa Ohashi
Pycon2017
by
Yuta Kashino
D3.jsと学ぶVisualization(可視化)の世界
by
AdvancedTechNight
岩波データサイエンス_Vol.5_勉強会資料01
by
goony0101
岩波データサイエンス_Vol.5_勉強会資料00
by
goony0101
闇と向き合う
by
Nagi Teramo
Similar to 機械学習のためのベイズ最適化入門
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PPTX
PRML読み会第一章
by
Takushi Miki
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PDF
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
PPTX
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
PDF
いいからベイズ推定してみる
by
Makoto Hirakawa
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
【輪読】Taking the Human Out of the Loop, section 8
by
Takeru Abe
PPTX
第9回 KAIM 金沢人工知能勉強会 進化的計算と最適化 / Evolutionary computation and optimization(移行済)
by
tomitomi3 tomitomi3
PDF
ベイズ入門
by
Zansa
PDF
bayesian inference
by
Asako Yanuki
PPTX
ベイズ統計学
by
Monta Yashi
PDF
20190526 bayes ml
by
Yoichi Tokita
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PDF
ITエンジニアのための機械学習理論入門8.1ベイズ推定
by
Daisuke Shimada
PDF
20190609 bayes ml ch3
by
Yoichi Tokita
PDF
20191006 bayesian dl_1_pub
by
Yoichi Tokita
PDF
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PRML読み会第一章
by
Takushi Miki
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
いいからベイズ推定してみる
by
Makoto Hirakawa
PRML第3章_3.3-3.4
by
Takashi Tamura
【輪読】Taking the Human Out of the Loop, section 8
by
Takeru Abe
第9回 KAIM 金沢人工知能勉強会 進化的計算と最適化 / Evolutionary computation and optimization(移行済)
by
tomitomi3 tomitomi3
ベイズ入門
by
Zansa
bayesian inference
by
Asako Yanuki
ベイズ統計学
by
Monta Yashi
20190526 bayes ml
by
Yoichi Tokita
20190512 bayes hands-on
by
Yoichi Tokita
ITエンジニアのための機械学習理論入門8.1ベイズ推定
by
Daisuke Shimada
20190609 bayes ml ch3
by
Yoichi Tokita
20191006 bayesian dl_1_pub
by
Yoichi Tokita
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
More from hoxo_m
PPTX
5分でわかるベイズ確率
by
hoxo_m
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
PDF
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
協調フィルタリング入門
by
hoxo_m
PDF
経験過程
by
hoxo_m
PDF
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
PDF
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
PDF
確率論基礎
by
hoxo_m
PPTX
高速なガンマ分布の最尤推定法について
by
hoxo_m
PDF
学習係数
by
hoxo_m
PDF
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
PDF
チェビシェフの不等式
by
hoxo_m
PDF
swirl パッケージでインタラクティブ学習
by
hoxo_m
PDF
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
PPTX
RPubs とその Bot たち
by
hoxo_m
PDF
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
PDF
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
5分でわかるベイズ確率
by
hoxo_m
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
階層モデルの分散パラメータの事前分布について
by
hoxo_m
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
協調フィルタリング入門
by
hoxo_m
経験過程
by
hoxo_m
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
確率論基礎
by
hoxo_m
高速なガンマ分布の最尤推定法について
by
hoxo_m
学習係数
by
hoxo_m
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
チェビシェフの不等式
by
hoxo_m
swirl パッケージでインタラクティブ学習
by
hoxo_m
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
RPubs とその Bot たち
by
hoxo_m
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
機械学習のためのベイズ最適化入門
1.
機械学習のための ベイズ最適化⼊⾨ 2017/07/01 牧⼭ 幸史 db analytic
showcase 2017 1
2.
⾃⼰紹介 • ヤフー株式会社 データサイエンティスト • SBイノベンチャー
(株) AI エンジニア • 株式会社ホクソエム 代表取締役 CEO 2
3.
本⽇の内容 • ベイズ最適化 (Bayesian
Optimization) を機械学習のハイパーパラメータ探索に 利⽤ • 効率的な探索を実現 • 実⾏⽅法まで • 詳しくはこの本で → 3
4.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 4
5.
1. はじめに • ベイズ最適化が注⽬を集めている •
ベイズ最適化: 形状の分からない関数(ブラックボックス関数)の 最⼤値または最⼩値を求める⼿法 • 機械学習のハイパーパラメータ探索に利⽤ • 効率的に精度の良い学習モデルを発⾒ 5
6.
ベイズ最適化 • ベイズ最適化とは – ⼤域的最適化問題 (Global
Optimization) – 逐次最適化⼿法 (Sequential Optimization) • 適⽤対象 – ブラックボックス関数 (関数の形が不明) – 計算コストが⼤きい (時間、お⾦) • 要求: 少ない評価回数で最適値を求めたい 6
7.
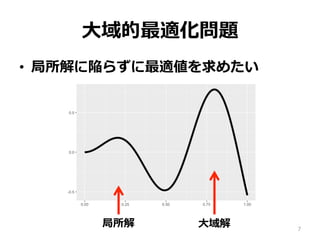
⼤域的最適化問題 • 局所解に陥らずに最適値を求めたい 7 局所解 ⼤域解
8.
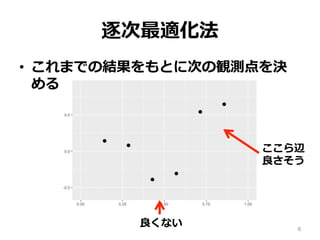
逐次最適化法 • これまでの結果をもとに次の観測点を決 める 8 ここら辺 良さそう 良くない
9.
逐次最適化の⾃動化 • これまでの結果を⾒て次にどこを観測し たらいいかは⼈間にはなんとなくわかる ➡︎ これを⾃動化したい •
ベイズ最適化 – ⼈間の直観的な判断を再現している 9
10.
1. まとめ • ベイズ最適化は⾼コストなブラックボッ クス関数の最適点を効率良く求める⼿法 •
何に使いたいか? ➡︎ 機械学習のハイパーパラメータ探索 10
11.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 11
12.
2. ハイパーパラメータ探索 • ほとんどの機械学習⼿法には、ハイパー パラメータが存在 •
ハイパーパラメータ: – データの学習では決定されないパラメータ – 学習の前にあらかじめ決めておく 12
13.
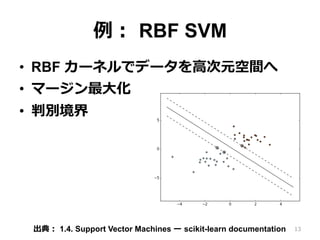
例: RBF SVM •
RBF カーネルでデータを⾼次元空間へ • マージン最⼤化 • 判別境界 13出典: 1.4. Support Vector Machines ー scikit-learn documentation
14.
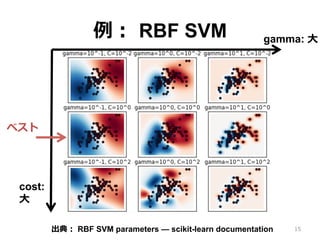
例: RBF SVM •
ハイパーパラメータ 2つ • gamma: – 1つのサポートベクタが影響を及ぼす範囲 – ⼤きいほど影響範囲が⼩さく過学習 • cost: – 判別境界の単純さと誤分類のトレードオフ – ⼤きいほど誤分類が少ないが過学習 14
15.
例: RBF SVM 15出典:
RBF SVM parameters — scikit-learn documentation cost: ⼤ gamma: ⼤ ベスト
16.
ハイパーパラメータ探索 • ハイパーパラメータの選び⽅によって 精度が劇的に変わる • 意味を考えて慎重に選択する必要 •
データと学習モデルに対する深い理解 • 職⼈芸 16
17.
2. まとめ • ハイパーパラメータは学習前に決める •
決め⽅で精度が劇的に変わる • チューニングは職⼈芸 • もっと簡単にできないか? ➡︎ グリッドサーチ 17
18.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 18
19.
3. グリッドサーチ • ハイパーパラメータの選択は職⼈芸 •
もっと簡単にやる⽅法としてグリッド サーチがある 19
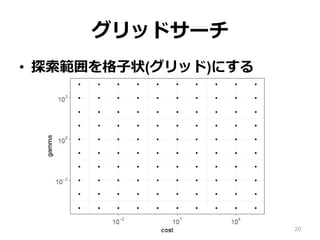
20.
グリッドサーチ • 探索範囲を格⼦状(グリッド)にする 20
21.
グリッドサーチ • ハイパーパラメータの格⼦を作る • gamma
= (10-5, 10-4, … , 102, 103) • cost = (10-4, 10-3, … , 103, 104) • それぞれの組み合わせでモデルを学習 • 例: • cost = 10-4, gamma = 10-5 ➡︎ 正答率 • cost = 10-4, gamma = 103 ➡︎ 正答率 21
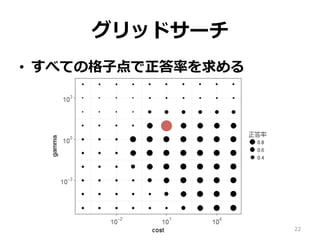
22.
グリッドサーチ • すべての格⼦点で正答率を求める 22
23.
グリッドサーチ • すべての組み合わせに対して正答率を求 め、最も良いものを選択する ※正答率はクロスバリデーションで求めた • シンプルでわかりやすい •
しかし、グリッドのすべての組み合わせ (今回は10 ✖ 10 = 100) に対して正答率を 計算するのは時間がかかる 23
24.
3. まとめ • グリッドサーチはハイパーパラメータの すべての組み合わせに対して正答率を計 算し最良のものを選ぶ •
データが多い場合、1回のモデルの学習に 多⼤な時間がかかる • 効率的に探索したい ➡︎ ベイズ最適化 24
25.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 25
26.
4. ベイズ最適化 • グリッドサーチは、すべての組み合わせ についてモデルを学習 ➡︎
時間がかかる • ベイズ最適化により効率的な探索が可能 26
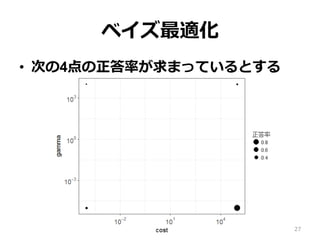
27.
ベイズ最適化 • 次の4点の正答率が求まっているとする 27
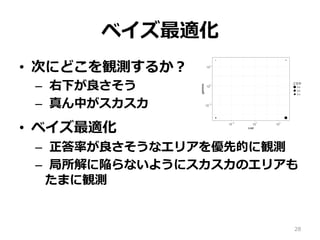
28.
ベイズ最適化 • 次にどこを観測するか? – 右下が良さそう –
真ん中がスカスカ • ベイズ最適化 – 正答率が良さそうなエリアを優先的に観測 – 局所解に陥らないようにスカスカのエリアも たまに観測 28
29.
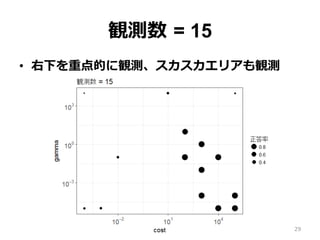
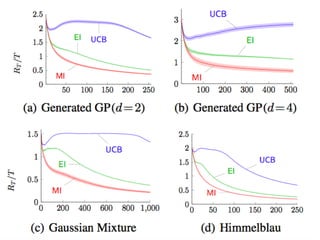
観測数 = 15 •
右下を重点的に観測、スカスカエリアも観測 29
30.
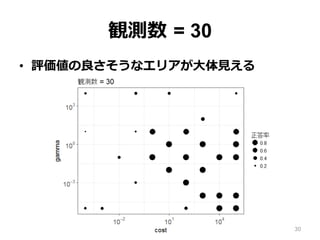
観測数 = 30 •
評価値の良さそうなエリアが⼤体⾒える 30
31.
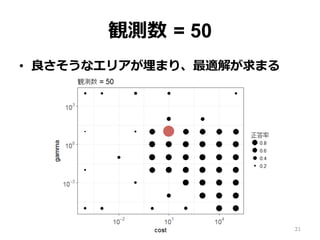
観測数 = 50 •
良さそうなエリアが埋まり、最適解が求まる 31
32.
4. まとめ • ベイズ最適化を使って、効率的に最適解 に到達 •
100個の格⼦点に対して 50回 • これまでの評価値に基づいて次の観測点 を⾃動的に判断 • どうやって判断しているか? ➡︎ 獲得関数 32
33.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 33
34.
5. 獲得関数 • ベイズ最適化は次の観測点を⾃動で判断 •
様々な戦略が提案されている ① PI 戦略 ② EI 戦略 ③ UCB 戦略 • 獲得関数は、それぞれの戦略で最⼤化さ れる関数 34
35.
① PI 戦略 •
PI 戦略 – Probability of Improvement (改善確率) – 現在の最⼤値 ybest – ybest を超える確率が最も⾼い点を次に観測 • シンプルで分かりやすいが局所解に陥る ことも 35
36.
② EI 戦略 •
PI 戦略は改善確率のみを考えた • 確率が⾼くても改善量が⼩さいと⾮効率 • EI 戦略 – Expected Improvement (期待改善量) – 評価値とベストの差 y – ybest の期待値が最も ⾼くなる点を次に観測 • 最も⼀般的に使われている 36
37.
③ UCB 戦略 •
UCB 戦略 – Upper Confidence Bound (上側信頼限界) – 評価値の信頼区間の上限が最も⾼い点を次に 観測 • 最適解にたどり着く理論的保証がある 37
38.
獲得関数 • それぞれの戦略は何らかの関数を最⼤化 する点を次に観測する – PI(x)
: y が ybest を超える確率 – EI(x) : y – ybest の期待値 – UCB(x): y の信頼区間の上限 • このような関数を獲得関数と呼ぶ 38
39.
5. まとめ • ベイズ最適化では獲得関数を最⼤化する 点を次に選ぶ •
獲得関数は確率、期待値、信頼区間など を使⽤ • どうやって計算するか? ➡︎ ガウス過程 39
40.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 40
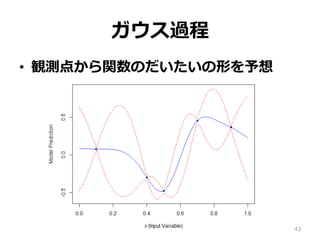
41.
6. ガウス過程 • ベイズ最適化では獲得関数を最⼤化する 点を次に観測 •
獲得関数には確率や期待値が使われる • これらを計算するために、最適化したい 関数がガウス過程に従うと仮定する 41
42.
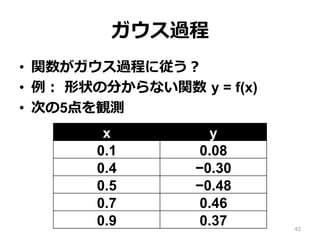
ガウス過程 • 関数がガウス過程に従う? • 例:
形状の分からない関数 y = f(x) • 次の5点を観測 42 x y 0.1 0.08 0.4 −0.30 0.5 −0.48 0.7 0.46 0.9 0.37
43.
ガウス過程 • 観測点から関数のだいたいの形を予想 43
44.
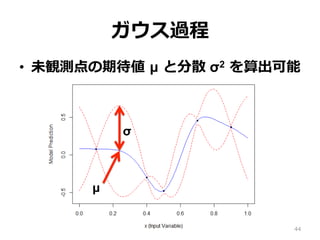
ガウス過程 • 未観測点の期待値 µ
と分散 σ2 を算出可能 44 σ µ
45.
ガウス過程 • 未観測点の期待値 µ
と分散 σ2 を算出可能 • µ が⼤きい: 周囲の観測点が⼤きい • σ が⼤きい: 周囲が観測されていない • µ が⼤きい点を次の観測点に選べば、⼤き い値が期待できる • しかし、そればかりでは局所解に陥る • 適度に σ の⼤きい点を探索する必要あり 45
46.
ガウス過程 • ガウス過程を仮定することで獲得関数が 計算可能に • カーネル関数の選択が必要 –
Squared Exponential: – Matern: 46
47.
カーネル関数 • 観測点同⼠がどれぐらい影響し合うか • 例:
Squared Exponential • 距離 d が遠いほど影響は⼩さくなる ➡︎「近い観測点は同じぐらいの値」を表現 47
48.
6. まとめ • 獲得関数を計算するためにガウス過程を 仮定する •
未評価点は近隣の評価点と近い値を取る • どれぐらい近くの評価点が影響するかは カーネル関数で決まる 48
49.
⽬次 1. はじめに 2. ハイパーパラメータ探索 3.
グリッドサーチ 4. ベイズ最適化 5. 獲得関数 6. ガウス過程 7. 実⾏ツール 49
50.
7. 実⾏ツール • ベイズ最適化を⾏うツールはたくさん –
SMAC – Spearmint (Python; ⾮商⽤) – COMBO (Python; 東京⼤学 津⽥研) – GPyOpt (Python) – bayesian-optimization (Python) – rBayesianOptimization (R) 50
51.
bayesian-optimization 51
52.
rBayesianOptimization 52
53.
7. まとめ • ベイズ最適化の実⾏ツールはたくさん •
特に Python ライブラリが多い • 簡単に実⾏できる – グリッド範囲の指定 – 獲得関数の指定 – カーネル関数の指定 • ぜひ実⾏してみて下さい! 53
54.
本⽇のまとめ • ベイズ最適化は⾼コストなブラックボッ クス関数の最適点を効率良く求める⼿法 • ガウス過程を⽤いて⽬的関数を表現 •
獲得関数が最⼤となる点を次の観測点に 選ぶ • ツールがたくさんあり簡単に実⾏できる 54
55.
おまけ 55
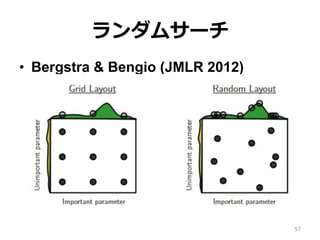
56.
ランダムサーチ • Bergstra &
Bengio (JMLR 2012) • ⼀部の機械学習⼿法において、ハイパー パラメータ探索はランダムサーチが有効 である • これは、機械学習の精度を左右するハイ パーパラメータは少数だからである 56
57.
ランダムサーチ • Bergstra &
Bengio (JMLR 2012) 57
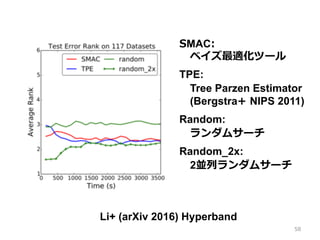
58.
58 SMAC: ベイズ最適化ツール TPE: Tree Parzen Estimator (Bergstra+
NIPS 2011) Random: ランダムサーチ Random_2x: 2並列ランダムサーチ Li+ (arXiv 2016) Hyperband
59.
獲得関数 MI (Contal+
2014) • Mutual Information (相互情報量) • 次の探索点として、獲得関数 MI(x) = µ(x) + K Φt(x) が最も⼤きい点 x を選ぶ • γt^ は f(xt) を観測したときに得られる 相互情報量の下限を表す 59
60.
相互情報量 • ガウス過程の相互情報量(f と観測値): •
γT を相互情報量の最⼤値と定義する 60 (Srinivas+2012)
61.
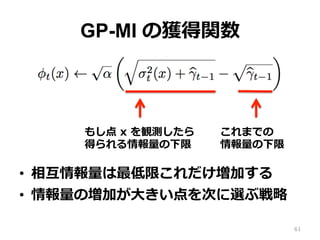
GP-MI の獲得関数 • 相互情報量は最低限これだけ増加する •
情報量の増加が⼤きい点を次に選ぶ戦略 61 これまでの 情報量の下限 もし点 x を観測したら 得られる情報量の下限
62.
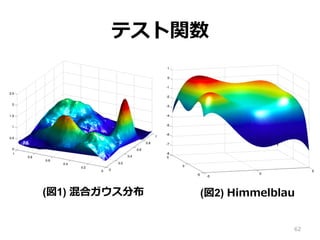
テスト関数 62 (図1) 混合ガウス分布 (図2)
Himmelblau
63.
63
64.
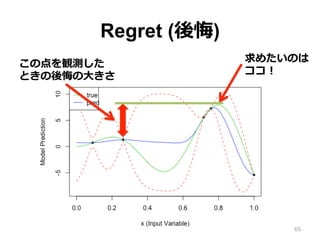
アルゴリズムの評価 • アルゴリズムの評価に Regret
(後悔) を使 う。 • Regret とは、探索点における f(xt) と最適 値 f(x★) の差 • 累積 Regret が⼩さいと良いアルゴリズム 64
65.
Regret (後悔) 65 求めたいのは ココ! この点を観測した ときの後悔の⼤きさ
66.
Regret 上限 「UCBは最適値へ収束する理論的保証あり」 正確には • 累積
Regret RT が Regret 上限 G(T)√α 以下になる確率が⼤きい Pr[RT ≦ G(T)√α] ≧ 1 – δ α = log(2/δ) • δ を⼩さくすると上限が緩くなる 66
67.
おしまい 67













































![Regret 上限
「UCBは最適値へ収束する理論的保証あり」
正確には
• 累積 Regret RT が Regret 上限 G(T)√α
以下になる確率が⼤きい
Pr[RT ≦ G(T)√α] ≧ 1 – δ
α = log(2/δ)
• δ を⼩さくすると上限が緩くなる
66](https://image.slidesharecdn.com/20170701-170701113402/85/slide-66-320.jpg)





























![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)



























































