Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TA
Uploaded by
Takeru Abe
249 views
【輪読】Taking the Human Out of the Loop, section 8
Taking the Human Out of the Loop, section 8を輪読した時の資料になります。
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PDF
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
PDF
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
プログラミングコンテストでの動的計画法
by
Takuya Akiba
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
ブラックボックス最適化とその応用
by
gree_tech
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
プログラミングコンテストでの動的計画法
by
Takuya Akiba
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
What's hot
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
正準相関分析
by
Akisato Kimura
PDF
深層学習とベイズ統計
by
Yuta Kashino
PDF
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PPTX
馬に蹴られるモデリング
by
Shushi Namba
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PDF
指数分布とポアソン分布のいけない関係
by
Nagi Teramo
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
双対性
by
Yoichi Iwata
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
最適輸送の解き方
by
joisino
PDF
AlphaGoのしくみ
by
Hiroyuki Yoshida
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
正準相関分析
by
Akisato Kimura
深層学習とベイズ統計
by
Yuta Kashino
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
ノンパラベイズ入門の入門
by
Shuyo Nakatani
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
馬に蹴られるモデリング
by
Shushi Namba
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
数学で解き明かす深層学習の原理
by
Taiji Suzuki
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
指数分布とポアソン分布のいけない関係
by
Nagi Teramo
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
双対性
by
Yoichi Iwata
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
最適輸送の解き方
by
joisino
AlphaGoのしくみ
by
Hiroyuki Yoshida
PRML第6章「カーネル法」
by
Keisuke Sugawara
Similar to 【輪読】Taking the Human Out of the Loop, section 8
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PPTX
第9回 KAIM 金沢人工知能勉強会 進化的計算と最適化 / Evolutionary computation and optimization(移行済)
by
tomitomi3 tomitomi3
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PPTX
PRML Chapter 5
by
Masahito Ohue
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PDF
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
PRML Chapter 5 (5.0-5.4)
by
Shogo Nakamura
PDF
【輪読】Bayesian Optimization of Combinatorial Structures
by
Takeru Abe
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
PRML輪読#3
by
matsuolab
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML 第14章
by
Akira Miyazawa
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
第9回 KAIM 金沢人工知能勉強会 進化的計算と最適化 / Evolutionary computation and optimization(移行済)
by
tomitomi3 tomitomi3
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
機械学習のためのベイズ最適化入門
by
hoxo_m
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PRML Chapter 5
by
Masahito Ohue
W8PRML5.1-5.3
by
Masahito Ohue
パターン認識モデル初歩の初歩
by
t_ichioka_sg
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PRML Chapter 5 (5.0-5.4)
by
Shogo Nakamura
【輪読】Bayesian Optimization of Combinatorial Structures
by
Takeru Abe
PRML10-draft1002
by
Toshiyuki Shimono
PRML輪読#3
by
matsuolab
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PRML_from5.1to5.3.1
by
禎晃 山崎
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PRML 第14章
by
Akira Miyazawa
【輪読】Taking the Human Out of the Loop, section 8
1.
阿部 武, 2022/7/29 Taking
Human Out of the Loop
2.
制約条件下でのベイズ最適化 1. 制約条件がわかっている場合 低カロリーだが美味しいクッキーを作りたい場合などが該当する。クッキーのカロリーを最小化 する一方で、95%の人は美味しいと答えるという条件下で最適解を見つける。制約条件を獲得 関数に組み込んで最適化を行う。 2. 制約条件も不明の場合 IECI(Integrated
Expected Constraint Improvement)を代表とする制約条件が不明でも使える 獲得関数を用いる
3.
制約条件下でのベイズ最適化 低カロリーだが美味しいクッキーを作りたい • 問題設定 • クッキーのカロリーはなるべく低くする •
n人に試食してもらい好きか嫌いかを評価してもらう • 制約条件 • 最低でも95パーセントの人が美味しいと回答する
4.
制約条件下でのベイズ最適化 低カロリーだが美味しいクッキーを作りたい argmin x C(x) s.t. q(x)
≥ 1 − ϵ : レシピ x : 試食者が美味しいと答える割合 q(x) : クッキーのカロリー C(x) レシピ カロリー 砂糖 20 g 100 kcal 薄力粉 40 g 50 kcal バター 20 g 80 kcal 卵 50 g 40 kcal : 美味しくなさを許容できる割合 ϵ
5.
制約条件下でのベイズ最適化 ある人がクッキーを好きかどうかは確率論的な事象 argmin x 𝔼 [f(x)] s.t. ∀kPr(Ck(x))
≥ 1 − ϵk 1.目的関数の期待値の最小化を目指す 2.高確率で制約条件を満たす を解とする x argmin x C(x) s.t. q(x) ≥ 1 − ϵ 制約条件がK個あるとして一般化 : 目的関数 f(x)
6.
制約条件下でのベイズ最適化 制約条件をモデルに組み込むために潜在制約関数 を定義 g(x) 制約条件 が満たされる Ck(x)
⇔ gk(x) ≥ 0 を推定する代理関数にGPを使えば累積分布関数を計算することで gk(x) Pr(Ck(x)) = Pr(gk(x) ≥ 0) = 1 − Pr(gk(x) < 0) = 1 − Φ(0) gk(x) ∼ GP(u, Σ)
7.
制約条件下でのベイズ最適化 制約条件の分布がガウス分布ではないとき f ∼ GP(0,
K) = p(f) y ∼ ℕ(f, σ2 I) = n ∏ i=1 p(yi ∣ fi) p(f ∣ y) ∝ ℕ(y ∣ f, σ2 I)ℕ(f ∣ 0, K) 事前分布 尤度 事後分布 のとき尤度にはベルヌーイ分布を用いるのが適切 y ∈ (0,1) p(yi ∣ λ(fi)) = { λ(fi) yi = 1 1 − λ(fi) yi = 0 λ(fi) = Φ(fi)
8.
制約条件下でのベイズ最適化 事前分布を二項分布や他の分布に設定することも可能 テスターがクッキーを好きか嫌いか ⇒ Bi(n,
q(x)) , であるから潜在制約関数 は q(x) ∈ (0,1) g(x) ∈ ℝ g(x) g(x) = s−1 (q(x)) s(x) = log x 1 − x
9.
制約条件下でのベイズ最適化 獲得関数に制約条件を組み込む a(x) = a(x)EIPr(C(x)) =
a(x)EI K ∏ k=1 Pr(Ck(x)) 探索点が制約条件を満たさないときは a(x) = K ∏ k=1 Pr(gk(x) ≥ 0)
10.
制約条件下でのベイズ最適化 制約条件が不明な場合の獲得関数も存在する I(x) = max{0,
fmin n − f(x)} fn min = min{f(x1), …, f(xn)} f ∼ GP(μ(x), k(x, x′  )) EI(x) = (fn min − μn(x)) Φ ( fn min − μn(x) σn(x) ) + σn(x) ϕ ( fn min − μn(x) σn(x) ) 期待改善度(Expected Improvement) EI(x) ≈ 1 T T ∑ t=1 max{0, fn min − y(t) } EI(x) = 𝔼 {I(x) ∣ Dn}
11.
制約条件下でのベイズ最適化 制約条件が不明な場合の獲得関数も存在する I(x ∣ xn+1)
= max{0, fn min − f(x ∣ xn+1)} ある探索点 が に追加されたときの改善度を定義 (次の探索点は決めたけれど,探索はまだしていない状態) xn+1 Dn I(x) = max{0, fmin n − f(x)} の分布は次の計算によって求められる f(x ∣ xn+1) ∣ Dn は未観測であるため, の平均には変化がない. 𝔼 {f(x ∣ xn+1) ∣ Dn} = μ(x) f(xn+1) f(x|Dn) f ∼ GP(μ(x), k(x, x′  )) ガウス過程の公式より Σ[Y(x ∣ xn+1) ∣ Dn] = σ2 n+1(x) σ2 n+1(x) = Σ(xn+1, xn+1) − Σ(xn+1, Xn)Σ−1 n Σ(Xn, xn1 ) ( f(x) ? ) ∼ N(μ(x), ( K k* kT * k**) ) が を加えた後でも改善度が高いなら は の改善 度可能性に影響が少ない. 逆に が の改善度に影響が あるなら, を加えた後の改善度は小さいはず x xn+1 xn+1 x xn+1 x xn+1
12.
制約条件下でのベイズ最適化 制約条件が不明な場合の獲得関数も存在する ある探索点 が に追加されたときの改善度の期待値(Expected
Conditional Improvement) xn+1 Dn fn min = min{f(x1), …, f(xn)} f ∼ GP(μ(x), k(x, x′  )) I(x ∣ xn+1) = max{0, fn min − f(x ∣ xn+1)} 𝔼 {I(x ∣ xn+1) ∣ Dn} = ( fn min − μn(x)) Φ ( fn min−μn(x) σn+1(x) ) + σn+1(x) ϕ ( fn min−μn(x) σn+1(x) ) σ2 n+1(x) = Σ(xn+1, xn+1) − Σ(xn+1, Xn)Σ−1 n Σ(Xn, xn1 )
13.
制約条件下でのベイズ最適化 制約条件が不明な場合の獲得関数も存在する 解空間 全体におけるECIをIECI(Integrated Expected
Conditional Improvement)と呼ぶ x ∈ 𝒳 IECI(xn+1) = − ∫x∈ 𝒳 𝔼 {I(x ∣ xn+1) ∣ Dn}w(x) dx U ∼ (0,1) 𝔼 {I(x ∣ xn+1) ∣ Dn} = ( fn min − μn(x)) Φ ( fn min−μn(x) σn+1(x) ) + σn+1(x) ϕ ( fn min−μn(x) σn+1(x) ) IECI(xn+1) ≈ − 1 T T ∑ t=1 𝔼 {I(x(t) ∣ xn+1)}w(x(t) ) where x(t) ∼ p( 𝒳 ), for t = 1,…, T,
14.
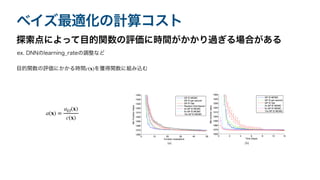
ベイズ最適化の計算コスト 探索点によって目的関数の評価に時間がかかり過ぎる場合がある ex. DNNのlearning_rateの調整など 目的関数の評価にかかる時間 を獲得関数に組み込む c(x) a(x)
= aEI(x) c(x)
15.
高次元空間におけるベイズ最適化 高次元空間では大抵のパラメータは目的関数の振る舞いに大きな影響 を与えない x⊤ ∈ τ
⊂ ℝD f(x) = f(x⊤ + x⊥) = f(x⊤) 目的関数 がもつ 次元のE ff ective Dimensionalityにおいて最適化を行う f : ℝD → ℝ de(de < D) x⊥ ∈ τ⊥ ⊂ ℝD を満たすような 次元の部分空間 において de τ が成り立つとき、 はE ff ective Dimensionalityを持つ f : ℝD → ℝ 有効次元
16.
高次元空間におけるベイズ最適化 ランダム行列を用いて高次元空間を低次元空間に埋め込む 目的関数 が という縮退した線型空間を持ち,ある方向に動かしても
の値が変わら ない場合に効果を発揮する.(REMBO, Random EMbeded Bayesian Optimization) f : ℝD → ℝ f(x) = f(x⊤ + x⊥) = f(x⊤) f(x) 定理1 が 次元の有効な次元(E ff ective Dimensionality)を 持ち,ランダム行列 の各要素 が から サンプリングされたとき, に対して, を満たすような が存在する. f : ℝD → ℝ de A ∈ ℝD×d (d ≥ de) ai,j ℕ(0,1) x ∈ ℝD f(x) = f(Ay) y
17.
高次元空間におけるベイズ最適化 g(x1, x2) =
(x2 − 5.1 4π2 x2 1 + 5 π − 6)2 + 10(1 − 1 8π )cos(x1) + 10 Branin関数に対して,関数に全く影響しないD-2次元を加えた合計D次元の の最小値を見つける実験で, 高パフォーマンスを発揮した. f(x)
18.
高次元空間におけるベイズ最適化 高次元空間では獲得関数が平坦になって探索が難しい 50次元のStyblinski-Tang関数から 500点観測した後のGPの出力で計算したEI
19.
高次元空間におけるベイズ最適化 獲得関数を1次元に制限することで効果的に探索を行う 𝕃 (x, l) =
{x + αl : α ∈ ℝ} ∩ X x ∈ X l ∈ ℝd X ⊂ ℝd argmin x∈x f(x) s.t. g(x) ≤ 0 問題設定 アフィン変換 が動かす方向、 が動かす大きさに対応する l α の選び方は, 1. 軸に沿った選び方(CoordinateLineBO) 2. 回目のGPの出力点 における勾配(DescentLineBO) l i xi
20.
高次元空間におけるベイズ最適化 ランダムに方向 を選んだとき大域的な収束は保証される l 命題 が有効次元について仮定1を満たし、カーネル が2回微分 可能であるとき、一様分布により選ばれたアフィン変換の方 向
で Algorithm1をK回繰り返すと、確率 で次式を 満たす f k l 1 − δ 仮定1 目的関数 と制約関数 は、カーネルを とし制約ノル ムを としたときたとき、再生核ヒルベルト空 間 の要素である。 f g k1, k2 ∥f∥H1 ,∥g∥H2 ≤ B H(k1), H(k2) f( ̂ xk) − f⋆ ≤ O(( 1 K log( 1 δ )) 2 de − 1 + ϵ) δ ∈ (0,1) ϵ : Accuracy
21.
高次元空間におけるベイズ最適化 ベンチマークとなる問題で他の提案手法より高性能を発揮した
22.
Multi-Tasks 関連のある複数の事象を同時にモデリングしたい Covid-19の感染者数は時間的・空間的な変化があり(non-stationary)互いに関連した指標である 出典 : The
New York Times
23.
Multi-Tasks 二つ以上のGPの出力を同時に計算する f1 ∼ GP(0,
k1(x, x′  )) f2 ∼ GP(0, k2(x, x′  )) D1 = {(x1 1, y1 1), (x1 2, y1 2), (x1 3, y1 3)} D2 = {(x2 1, y2 1), (x2 2, y2 2)} y1 i = f1(x1 i ) + ϵi ϵi ∼ ℕ(0,σ2 1) y2 i = f2(x2 i ) + ϵi ϵi ∼ ℕ(0,σ2 2) ( y1 y2) ∼ N( ( 0 0) , ( K1 0 0 K2) + ( σ2 1I 0 0 σ2 2I) )
24.
Multi-Tasks 二つの関数が一つの潜在関数から生成されたと考える f1(x) = w1u(x) u(x)
∼ GP(0, k(x, x′  )) f2(x) = w2u(x) ( y1 y2) ∼ N( ( 0 0) , K + ( σ2 1I 0 0 σ2 2I) ) K = Bk(x, x′  ) = wwT k(x, x′  ) w = [w1, w2]T Bが と の相関度に対応する f1 f2
25.
Multi-Tasks 多次元の出力を行う最も基本的なモデルをICMと呼ぶ 関数の集合 があったとき, それぞれの潜在関数
がガウス過程 に従うとす ると, P個の関数の出力 とすると {f1(x), f2(x), …, fP(x)} ui (x) ui ∼ GP(0, k(x, x′  )) f(x) = [f1(x), f2(x), …, fP(x)]T fp(x) ∼ R ∑ i=1 wi pui (x) Cov(f(x), f(x′  )) = Bk(x, x′  ) f ∼ (0, Bk(x, x′  ))
26.
Multi-Tasks 関数同士の相関を捉え少ない計算コストで出力を計算する f1(x) = 4
cos( x 5 ) − 0.4 * x − 35 + 2ϵ1 ϵ1 ∼ U(0,1) f2(x) = 6 cos( x 5 ) + 0.2 * x + 35 + 8ϵ2 ϵ2 ∼ U(0,1)
27.
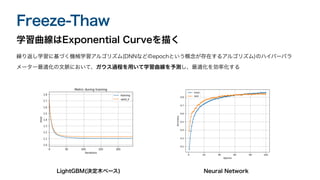
Freeze-Thaw 学習曲線はExponential Curveを描く 繰り返し学習に基づく機械学習アルゴリズム(DNNなどのepochという概念が存在するアルゴリズム)のハイパーパラ メーター最適化の文脈において、ガウス過程を用いて学習曲線を予測し、最適化を効率化する LightGBM(決定木ベース) Neural
Network
28.
Freeze-Thaw Exponential Curveをカーネルで表現する k(t, t′  )
= ∫ ∞ 0 e−λt e−λt′  ψ(dλ) = int∞ 0 e−λ(t+t′  ) βα Γ(α) λα−1 e−λβ dλ = βα (t + t′  + β)α ψ(λ) = βα Γ(α) λα−1 e−λβ k(t, t′  ) = exp(− |t − t′  | θ ) 提案カーネル ガンマ関数 Ornstein-Uhlenbeck カーネル
29.
Freeze-Thaw どのモデルの学習を停止、再開させるかを自動で選択する <- 5epochづつ進める <- 5epoch学習する ↓
5回分のデータでガウス過程により終点を予測する <- 5個のデータをまとめた獲得関数の値を1つ計算する <- 次のモデルを決定する
30.
Freeze-Thaw 非常に早い段階で最適解に り着く
31.
Appendix
32.
Random EMbedded BO 定理1 が
次元のE ff ective Dimensionalityを持ち,ランダム行列 の各要素 が からサンプリ ングされたならば, に対して を満たすような が存在する. f : ℝD → ℝ de A ∈ ℝD×d (d ≥ de) ai,j ℕ(0,1) x ∈ ℝD f(x) = f(Ay) y 必要性 が 次元のE ff ective Dimensionalityを持つ ので, となるような部分空間 が存在する. このとき, と によって, とすることができるから, を満たすような が存在する. f : ℝD → ℝ de rank(τ) = de τ x⊤ ∈ τ ⊂ ℝD x⊥ ∈ τ⊥ ⊂ ℝD f(x) = f(x⊤ + x⊥) = f(x⊤) f(x) = f(Ay) y ∈ ℝd 十分性 の正規直交基底によって構成された に対して, で となるような が存在する. と仮定すると, となるような が存在し, の への垂直射影は で与えられる. 従って,ある について が成り立つ. τ Φ ∈ ℝD×de x⊥ ∈ τ x⊤ = Φc c ∈ ℝde rank(ΦT A) = de (ΦT A)y = c y Ay τ ΦΦT Ay = Φc = x⊤ x′  ∈ τ⊤ Ay = x⊤ + x′  次ページで証明
33.
高次元空間におけるベイズ最適化 の正規直交基底によって構成された に対して,ランダム行列 の各要素
が から サンプリングされたならば, である τ Φ ∈ ℝD×de A ∈ ℝD×d (d ≥ de) ai,j ℕ(0,1) rank(ΦT A) = de Proof の部分行列を とする. 例えば, の 番目の列ベクトル とすると, であるから, 同様に計算すると となる. はルベーグ測度0で,正規分布はルベーグ測度に対して絶対連続であるから, は確率1で正則であ る. ゆえに, であるから, が成り立つ. A Ae ∈ ℝD×de Ae i ai ΦT ai ∼ ℕ(0, ΦT Φ) = ℕ(0de , Ide×de ) ΦT Ae ∼ ℕ(0d2 e , Id2 e ×d2 e ) ℝd2 e ΦT Ae ∼ ℕ(0d2 e , Id2 e ×d2 e ) rank(ΦT Ae) = de rank(ΦT A) = de ??????????
Download




![制約条件下でのベイズ最適化
ある人がクッキーを好きかどうかは確率論的な事象
argmin
x
𝔼
[f(x)] s.t. ∀kPr(Ck(x)) ≥ 1 − ϵk
1.目的関数の期待値の最小化を目指す
2.高確率で制約条件を満たす を解とする
x
argmin
x
C(x) s.t. q(x) ≥ 1 − ϵ
制約条件がK個あるとして一般化
: 目的関数
f(x)](https://image.slidesharecdn.com/bayesopt-220825050513-cce2cd08/85/Taking-the-Human-Out-of-the-Loop-section-8-5-320.jpg)





![制約条件下でのベイズ最適化
制約条件が不明な場合の獲得関数も存在する
I(x ∣ xn+1) = max{0, fn
min − f(x ∣ xn+1)}
ある探索点 が に追加されたときの改善度を定義
(次の探索点は決めたけれど,探索はまだしていない状態)
xn+1 Dn
I(x) = max{0, fmin
n − f(x)}
の分布は次の計算によって求められる
f(x ∣ xn+1) ∣ Dn
は未観測であるため, の平均には変化がない.
𝔼
{f(x ∣ xn+1) ∣ Dn} = μ(x)
f(xn+1) f(x|Dn)
f ∼ GP(μ(x), k(x, x′

))
ガウス過程の公式より
Σ[Y(x ∣ xn+1) ∣ Dn] = σ2
n+1(x)
σ2
n+1(x) = Σ(xn+1, xn+1) − Σ(xn+1, Xn)Σ−1
n Σ(Xn, xn1
)
(
f(x)
? )
∼ N(μ(x),
(
K k*
kT
* k**)
)
が を加えた後でも改善度が高いなら は の改善
度可能性に影響が少ない. 逆に が の改善度に影響が
あるなら, を加えた後の改善度は小さいはず
x xn+1 xn+1 x
xn+1 x
xn+1](https://image.slidesharecdn.com/bayesopt-220825050513-cce2cd08/85/Taking-the-Human-Out-of-the-Loop-section-8-11-320.jpg)











![Multi-Tasks
二つの関数が一つの潜在関数から生成されたと考える
f1(x) = w1u(x)
u(x) ∼ GP(0, k(x, x′

))
f2(x) = w2u(x)
(
y1
y2)
∼ N(
(
0
0)
, K +
(
σ2
1I 0
0 σ2
2I)
)
K = Bk(x, x′

) = wwT
k(x, x′

) w = [w1, w2]T
Bが と の相関度に対応する
f1 f2](https://image.slidesharecdn.com/bayesopt-220825050513-cce2cd08/85/Taking-the-Human-Out-of-the-Loop-section-8-24-320.jpg)
![Multi-Tasks
多次元の出力を行う最も基本的なモデルをICMと呼ぶ
関数の集合 があったとき, それぞれの潜在関数 がガウス過程 に従うとす
ると, P個の関数の出力 とすると
{f1(x), f2(x), …, fP(x)} ui
(x) ui
∼ GP(0, k(x, x′

))
f(x) = [f1(x), f2(x), …, fP(x)]T
fp(x) ∼
R
∑
i=1
wi
pui
(x)
Cov(f(x), f(x′

)) = Bk(x, x′

)
f ∼ (0, Bk(x, x′

))](https://image.slidesharecdn.com/bayesopt-220825050513-cce2cd08/85/Taking-the-Human-Out-of-the-Loop-section-8-25-320.jpg)














![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)


















