Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
KazuhiroSato8
150 views
Casual learning machine learning with_excel_no3
エクテックカジュアル勉強会 『Excelで機械学習入門(第3回)』 の投影資料となります。
Education
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 17 times
1
/ 107
2
/ 107
3
/ 107
4
/ 107
5
/ 107
6
/ 107
7
/ 107
8
/ 107
9
/ 107
10
/ 107
11
/ 107
12
/ 107
13
/ 107
14
/ 107
15
/ 107
16
/ 107
17
/ 107
18
/ 107
19
/ 107
20
/ 107
21
/ 107
22
/ 107
23
/ 107
24
/ 107
25
/ 107
26
/ 107
27
/ 107
28
/ 107
29
/ 107
30
/ 107
31
/ 107
32
/ 107
33
/ 107
34
/ 107
35
/ 107
36
/ 107
37
/ 107
38
/ 107
39
/ 107
40
/ 107
41
/ 107
42
/ 107
43
/ 107
44
/ 107
45
/ 107
46
/ 107
47
/ 107
48
/ 107
49
/ 107
50
/ 107
51
/ 107
52
/ 107
53
/ 107
54
/ 107
55
/ 107
56
/ 107
57
/ 107
58
/ 107
59
/ 107
60
/ 107
61
/ 107
62
/ 107
63
/ 107
64
/ 107
65
/ 107
66
/ 107
67
/ 107
68
/ 107
69
/ 107
70
/ 107
71
/ 107
72
/ 107
73
/ 107
74
/ 107
75
/ 107
76
/ 107
77
/ 107
78
/ 107
79
/ 107
80
/ 107
81
/ 107
82
/ 107
83
/ 107
84
/ 107
85
/ 107
86
/ 107
87
/ 107
88
/ 107
89
/ 107
90
/ 107
91
/ 107
92
/ 107
93
/ 107
94
/ 107
95
/ 107
96
/ 107
97
/ 107
98
/ 107
99
/ 107
100
/ 107
101
/ 107
102
/ 107
103
/ 107
104
/ 107
105
/ 107
106
/ 107
107
/ 107
More Related Content
PDF
Casual learning machine learning with_excel_no2
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
PDF
Casual learning machine_learning_with_excel_no7
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
PDF
Casual learning-machinelearningwithexcelno8
by
KazuhiroSato8
PDF
130604 fpgax kibayos
by
Mikio Yoshida
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
Casual learning machine learning with_excel_no2
by
KazuhiroSato8
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
Casual learning machine_learning_with_excel_no7
by
KazuhiroSato8
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
Casual learning-machinelearningwithexcelno8
by
KazuhiroSato8
130604 fpgax kibayos
by
Mikio Yoshida
はじめてのパターン認識輪読会 10章後半
by
koba cky
What's hot
PDF
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
Introduction to Persistence Theory
by
Tatsuki SHIMIZU
PDF
Oshasta em
by
Naotaka Yamada
PDF
20170408cvsaisentan6 2 4.3-4.5
by
Takuya Minagawa
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
PDF
Sparse pca via bipartite matching
by
Kimikazu Kato
PDF
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
詳説word2vec
by
Haruka Oikawa
PDF
13.2 隠れマルコフモデル
by
show you
PPTX
2SAT(充足可能性問題)の解き方
by
Tsuneo Yoshioka
PDF
Processingによるプログラミング入門 第2回
by
Ryo Suzuki
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
20170422 数学カフェ Part1
by
Kenta Oono
Introduction to Persistence Theory
by
Tatsuki SHIMIZU
Oshasta em
by
Naotaka Yamada
20170408cvsaisentan6 2 4.3-4.5
by
Takuya Minagawa
Rで学ぶロバスト推定
by
Shintaro Fukushima
Sparse pca via bipartite matching
by
Kimikazu Kato
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
グラフニューラルネットワーク入門
by
ryosuke-kojima
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
詳説word2vec
by
Haruka Oikawa
13.2 隠れマルコフモデル
by
show you
2SAT(充足可能性問題)の解き方
by
Tsuneo Yoshioka
Processingによるプログラミング入門 第2回
by
Ryo Suzuki
Similar to Casual learning machine learning with_excel_no3
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
3.4
by
show you
PPTX
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
PPTX
ベイズ基本0425
by
asato kuno
PPTX
ベイズ基本0425
by
asato kuno
PDF
20170630 Cognitive Interaction Design @ Kyoto Institute of Technology
by
Kazushi Ikeda
PPT
ma92007id395
by
matsushimalab
PDF
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PDF
PRML セミナー
by
sakaguchi050403
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PPTX
ベイズ基本0425
by
asato kuno
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PDF
How to study stat
by
Ak Ok
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
ベイズ入門
by
Zansa
PDF
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PRML第3章_3.3-3.4
by
Takashi Tamura
ベイズ統計入門
by
Miyoshi Yuya
3.4
by
show you
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
ベイズ基本0425
by
asato kuno
ベイズ基本0425
by
asato kuno
20170630 Cognitive Interaction Design @ Kyoto Institute of Technology
by
Kazushi Ikeda
ma92007id395
by
matsushimalab
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PRML セミナー
by
sakaguchi050403
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
ベイズ基本0425
by
asato kuno
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
How to study stat
by
Ak Ok
PRML読み会第一章
by
Takushi Miki
ベイズ入門
by
Zansa
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
機械学習のためのベイズ最適化入門
by
hoxo_m
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
20190512 bayes hands-on
by
Yoichi Tokita
More from KazuhiroSato8
PDF
Casual learning anomaly_detection_with_machine_learning_no1
by
KazuhiroSato8
PDF
Casual data analysis_with_python_vol2
by
KazuhiroSato8
PDF
Casual datascience vol5
by
KazuhiroSato8
PDF
Basic deep learning_framework
by
KazuhiroSato8
PDF
Casual learning machine_learning_with_excel_no1
by
KazuhiroSato8
PDF
エクテック カジュアル勉強会 データサイエンスを学ぶ第2回
by
KazuhiroSato8
PDF
エクテック カジュアル勉強会 データサイエンスを学ぶ第1回
by
KazuhiroSato8
PDF
Casual data analysis_with_python_vol1
by
KazuhiroSato8
PDF
Casual datascience vol4
by
KazuhiroSato8
PDF
Casual datascience vol3
by
KazuhiroSato8
PDF
Casual datascience vol2
by
KazuhiroSato8
PDF
Casual datascience vol1
by
KazuhiroSato8
Casual learning anomaly_detection_with_machine_learning_no1
by
KazuhiroSato8
Casual data analysis_with_python_vol2
by
KazuhiroSato8
Casual datascience vol5
by
KazuhiroSato8
Basic deep learning_framework
by
KazuhiroSato8
Casual learning machine_learning_with_excel_no1
by
KazuhiroSato8
エクテック カジュアル勉強会 データサイエンスを学ぶ第2回
by
KazuhiroSato8
エクテック カジュアル勉強会 データサイエンスを学ぶ第1回
by
KazuhiroSato8
Casual data analysis_with_python_vol1
by
KazuhiroSato8
Casual datascience vol4
by
KazuhiroSato8
Casual datascience vol3
by
KazuhiroSato8
Casual datascience vol2
by
KazuhiroSato8
Casual datascience vol1
by
KazuhiroSato8
Casual learning machine learning with_excel_no3
1.
カジュアル勉強会 @仙台 Excelで機械学習入門 第3回 株式会社
エクテック データサイエンティスト
2.
第10回までの流れ 1回~3回 4回~10回 AI周辺の 基本知識 最適化の基本 推論の基本 重回帰分析 機械学習 サポートベクタマシン ナイーブベイズ ニューラルネットワーク RNN/BPTT 強化学習/Q学習
3.
前段
4.
勉強会に参加する以上...
5.
『なにか』を 持って帰って欲しい
6.
『すべて』は難しいけれど 気になった、興味をもった キーワードでも良いので ⼿元に持って帰って いただけると幸いです
7.
環境について (Surroundings)
8.
Excel 2013, 2016 Google
Spreadsheets
9.
本日のアジェンダ 1. 遺伝的アルゴリズム 2. ベイズの定理
10.
前回のやり残し
11.
『数式ばかりで、わかりづらい』
12.
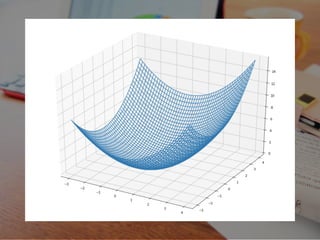
m(λ, μ) ≦
m0 ≦ 1 2 (x + y ) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2
13.
これの意味するものは...
14.
m(λ, μ) ≦
m0 ≦ 1 2 (x + y ) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2
16.
m(λ, μ) ≦
m0 ≦ 1 2 (x + y ) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2
17.
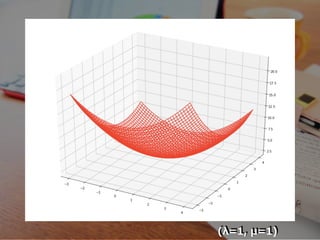
(λ=1, μ=1)
18.
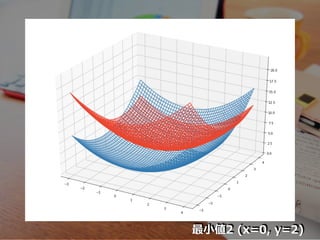
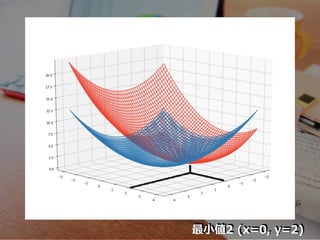
m(λ, μ) ≦
m0 ≦ 1 2 (x + y ) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2
19.
最⼩値2 (x=0, y=2)
20.
最⼩値2 (x=0, y=2)
21.
遺伝的アルゴリズム
22.
ηと勾配降下法の注意点
23.
ηが⼤きすぎると
24.
ηが⼩さすぎると
25.
明確な、確実な⽅法はない
26.
地道に 試⾏錯誤で⾒つけ出す
27.
η(ステップ幅) 試⾏錯誤以外にないか??
28.
極⼩値 最⼩値 最適化問題の難しいところ
29.
最⼩の値を求めたいのに 実は極⼩の値を求めてしまう
30.
最⼩の値を求めたいのに 実は極⼩の値を求めてしまう 『局所解問題』
31.
遺伝的アルゴリズムで 最⼩値問題を解く
32.
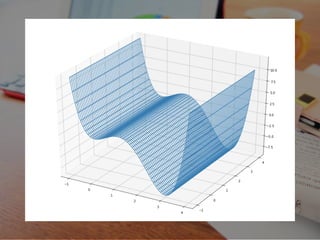
16 3 x 3 f(x) = x
- 4 + 6x 2 この関数の、最⼩値とそのときの x を求めたいとします
34.
極⼩値 最⼩値
35.
答えを先に⾔ってしまうと 最⼩値 -9 (x=3のとき)
36.
これを 遺伝的アルゴリズムで解いてみる
37.
遺伝的アルゴリズムとは?
38.
『選択』『交叉』 『突然変異』
39.
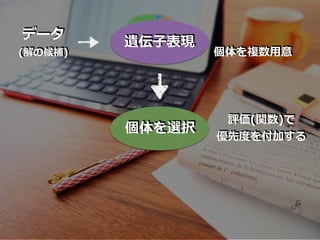
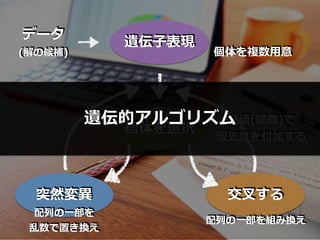
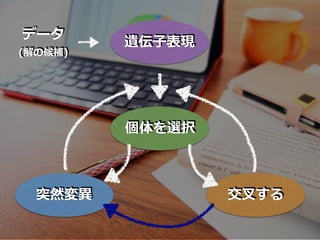
遺伝⼦表現 データ (解の候補) 個体を複数⽤意
40.
遺伝⼦表現 データ (解の候補) 個体を選択 個体を複数⽤意 評価(関数)で 優先度を付加する
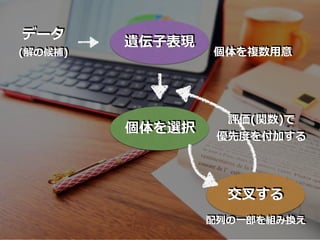
41.
遺伝⼦表現 データ (解の候補) 個体を選択 個体を複数⽤意 交叉する 配列の⼀部を組み換え 評価(関数)で 優先度を付加する
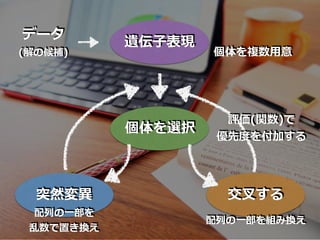
42.
遺伝⼦表現 データ (解の候補) 個体を選択 突然変異 個体を複数⽤意 交叉する 配列の⼀部を組み換え 配列の⼀部を 乱数で置き換え 評価(関数)で 優先度を付加する
43.
遺伝⼦表現 データ (解の候補) 個体を選択 突然変異 個体を複数⽤意 交叉する 配列の⼀部を組み換え 配列の⼀部を 乱数で置き換え 評価(関数)で 優先度を付加する 遺伝的アルゴリズム
44.
16 3 x 3 f(x) = x
- 4 + 6x 2 この関数の、最⼩値とそのときの x を求めたいとします
45.
遺伝⼦表現
46.
ランダムに、x を選択する 7, 9,
12, 13
47.
ランダムに、x を選択する 7, 9,
12, 13 “0111”, “1001”, “1100”, “1101” 2進数表記して「個体」とします
48.
個体を選択
49.
これらが、どれほど環境(関数f(x)) に適しているか f(0111) = 865.7 f(1001)
= 3159.0 f(1100) = 12384.0 f(1101) = 17857.7
50.
今回は、 「最⼩値を求める」= 「値が⼩さいほど環境に適している」
51.
これらが、どれほど環境(関数f(x)) に適しているか f(0111) = 865.7 f(1001)
= 3159.0 f(1100) = 12384.0 f(1101) = 17857.7
52.
”0111”, “1001”
53.
”0111”, “1001” これら以外は、捨てる(淘汰)
54.
交叉する
55.
優れた「個体」を作るために 『交叉』します
56.
優れた「個体」を作るために 『交叉』します 最も単純な、 『⼀点交叉』を⽤いる
57.
01 | 11
10 | 01 01 | 01 10 | 11 (親) (⼦) 交叉
58.
“0111”, “1001”, “1100”,
“1101” (現世代) “0111”, “1001”, “0101”, “1011” (次世代)
59.
突然変異
60.
01 11 01 10 その個体の ランダムな箇所 にランダムな値 に書き換える
61.
遺伝⼦表現 データ (解の候補) 個体を選択 突然変異 交叉する
62.
『選択』→『交叉』→『突然変異』 このサイクルを何度も繰り返す (今回の場合は、10回以内で最⼩が出てくる)
63.
遺伝的アルゴリズム AIの分野では、頻繁に利⽤される⼿法
64.
ベイズの定理
65.
ベイズ理論・ベイズ推論
66.
21世紀に⼊って ⾶躍的に発展した理論分野の⼀つ
67.
出発点は、「ベイズの定理」
68.
条件付き確率
69.
⽇本⼈の成⼈男⼥の割合は順に 49%, 51%です。 また、喫煙率は男性が
28%, ⼥性が 9%です。 成⼈⽇本⼈から無作為に1⼈を抽出したとき、 男性である事象を M, ⼥性である事象を F、 喫煙者である事象を Sとします。 (2018年総務省統計局及びJT調査)
70.
成⼈⽇本⼈の全体(P) M 49% F
51% M 28% F 9% S P(M) = 0.49, P(F) = 0.51, P(S|M) = 0.28, P(S|F) = 0.09
71.
さて、全体からみた男性喫煙率は? 全体からみた⼥性喫煙率は? はたまた、Sの割合は?
72.
乗法定理 P(A∩B) = P(A)P(B|A) P(A∩B)
事象A, Bが同時に起こる確率 P(B|A) 条件付き確率
73.
P(M) = 0.49,
P(F) = 0.51, P(S|M) = 0.28, P(S|F) = 0.09 P(S∩M) = P(M∩S) = P(M)P(S|M) =0.49 ✖ 0.28 = 0.14, P(S∩F) = P(F∩S) = P(F)P(S|F) =0.51 ✖ 0.09 = 0.046, P(S) = P(S∩M) + P(S∩F) =0.14 + 0.046 = 0.186
74.
乗法定理から、ベイズの定理へ P(B|A)P(A) P(B) P(A|B) =
75.
ベイズの定理 証明してみましょう...!
76.
乗法定理 P(A∩B) = P(A)P(B|A) P(A∩B)
事象A, Bが同時に起こる確率 P(B|A) 条件付き確率 2つの事象A, Bについて 次の式が成⽴します
77.
P(A∩B) = P(A)P(B|A) P(B∩A)
= P(B)P(A|B) A∩B A∩B B A B A P(B∩A) = P(B)P(A|B)P(A∩B) = P(A)P(B|A)
78.
P(A∩B) = P(B∩A)なので P(B)P(A|B)
= P(A)P(B|A) P(B) ≠ 0を仮定すれば P(B|A)P(A) P(B) P(A|B) = 証明終
79.
ベイズの定理を データサイエンスの⽬線から⾒ると
80.
ある仮定H(Hypothesis)のもとで 事象D(Data)が得られるとき、次の関係が成り⽴つ P(D|H)P(H) P(D) P(H|D) = ある仮定Hが成⽴する → 結果として、データDが得られる と解釈してみる
81.
最初のお題を、 データサイエンスっぽいお題に
82.
⽇本⼈から無作為に抽出した1⼈が喫煙の習慣を 持つと答えました。この⼈が男性である確率は? (⽐率は、最初のお題と同じ)
83.
求めたい確率は、P(M|S) SをデータDとして、Mを仮説Hとすると ⽇本⼈から無作為に抽出した1⼈が喫煙の習慣を 持つ、という仮説H それが男性である、という結果D P(D|H)P(H) P(D) P(M|S) =
84.
P(D|H)P(H) P(D) P(M|S) = P(S) =
P(D) = 0.18, P(S|M)P(M) = P(D|H)P(H) = 0.14 0.14 0.18 P(M|S) = = 0.78
85.
原因の確率
86.
H D P(D|H) 仮定(原因) 結果(データ) ⼀般的には、「原因があって結果」である
87.
H D P(D|H) 仮定(原因) 結果(データ) D
H P(H|D) 結果(データ) 仮定(原因) ベイズの定理 結果であるデータから、 ”原因の確率”を得ることができる(ベイズ推論)
88.
現実問題に、即していきます
89.
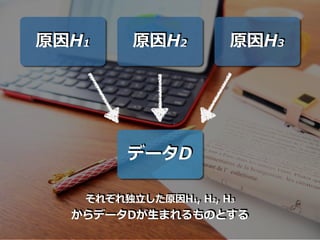
原因H1 原因H2 原因H3 データD それぞれ独⽴した原因H1,
H2, H3 からデータDが⽣まれるものとする
90.
D H1 H2 H3 D∩H1
D∩H2 D∩H3 P(D) = P(D∩H1) + P(D∩H2) + P(D∩H3)
91.
P(D) = P(D∩H1)
+ P(D∩H2) + P(D∩H3) P(D) = P(D|H1)P(H1) + P(D|H2)P(H2) + P(D|H3)P(H3) ※乗法定理 P(A∩B) = P(A)P(B|A)
92.
P(D) = P(D|H1)P(H1)
+ P(D|H2)P(H2) + P(D|H3)P(H3) P(D|H1)P(H1) P(D) P(H1|D) = ベイスの定理を使って、原因H1に注⽬してみる = P(D|H1)P(H1) P(D|H1)P(H1) + P(D|H2)P(H2) + P(D|H3)P(H3)
93.
P(D|H1)P(H1) P(D|H1)P(H1) + P(D|H2)P(H2)
+ P(D|H3)P(H3) データD の原因として3つ考えた場合の、 “原因H1の確率”を表現している
94.
⼀般化して、データDがあり、 原因が {H1, H2,
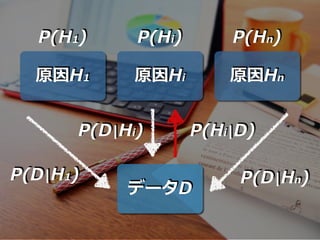
…, Hn}のn個あるとすれば、 データDが得られたとき、その原因が Hiである 確率は下記のように表現できる P(Hi|D) = P(D|Hi)P(Hi) P(D|H1)P(H1) + P(D|H2)P(H2) + … + P(D|Hn)P(Hn) 周辺尤度
95.
原因H1 原因Hi 原因Hn データD P(H1)
P(Hi) P(Hn) P(Hi|D)P(D|Hi) P(D|H1) P(D|Hn)
96.
原因H1 原因Hi 原因Hn データD P(H1) P(D|H1) P(Hn) P(D|Hn) P(Hi) P(D|Hi)
P(Hi|D) 事前確率 尤度 事後確率
97.
壺の問題
98.
外からは区別のつかない2つの壺 a, bがあります。 壺
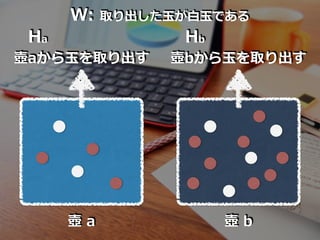
aには⽩⽟が2個、⾚⽟が3個、 壺 bには⽩⽟が4個、⾚⽟が8個⼊っています。 いま、壺 a, b のいずれか1つがあり、その壺から ⽟1個を取り出したら、⽩⽟だったと⾔います。 このとき、その壺が aである確率を求めましょう。 また bである確率も求めましょう。
99.
壺 a 壺
b Ha Hb 壺aから⽟を取り出す 壺bから⽟を取り出す W: 取り出した⽟が⽩⽟である
100.
求める確率は、 取り出された⽟が⽩のとき 壺aから取り出された確率 P(Ha|W) 壺bから取り出された確率 P(Hb|W)
101.
ベイズの定理から P(W|Ha)P(Ha) P(W|Ha)P(Ha) + P(W|Hb)P(Hb) P(Ha|W)
= P(W|Hb)P(Hb) P(W|Ha)P(Ha) + P(W|Hb)P(Hb) P(Hb|W) =
102.
尤度 P(W|Ha), P(W|Hb) P(W|Ha)
= 「壺aから取り出された⽟が⽩であ る確率」 = 2 / (2 + 3) = 2 / 5 P(W|Hb) = 「壺bから取り出された⽟が⽩であ る確率」 = 4 / (4 + 8) = 1 / 3
103.
事前確率 P(Ha), P(Hb) 問題⽂の中には、壺a,
壺bがどのような 割合で選ばれるかの情報はない 『等確率』として考えてみる (理由不⼗分の原則) P(Ha) = P(Hb) = 1/2
104.
2/5 ✖ 1/2 2/5
✖ 1/2 + 1/3 ✖ 1/2 P(Ha|W) = 1/3 ✖ 1/2 2/5 ✖ 1/2 + 1/3 ✖ 1/2 P(Hb|W) = 以上の値を代⼊すればOK = 6/11 = 5/11
105.
新しいデータを追加することで より正確な確率が導き出されていく
106.
AIの根幹である ディープラーニングや機械学習の基礎
107.
EoF
Download

















































































































![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)








































