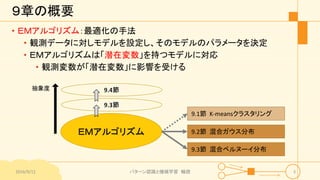
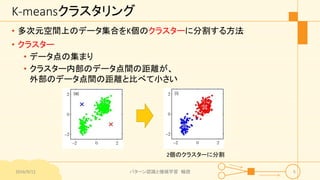
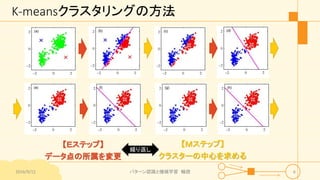
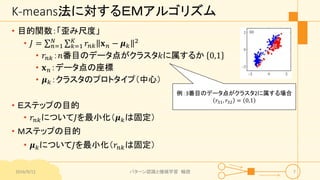
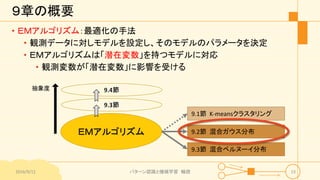
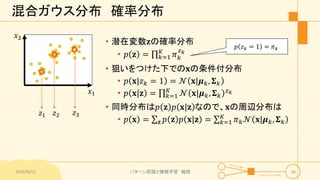
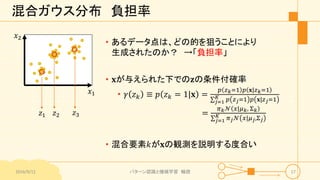
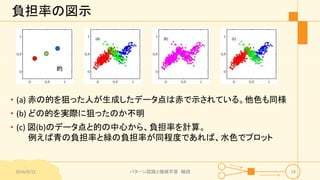
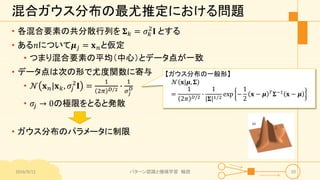
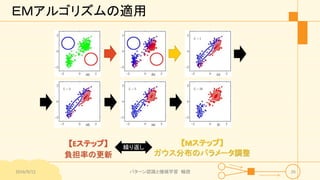
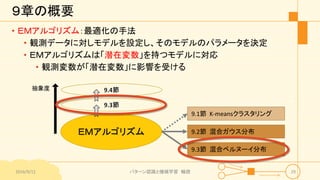
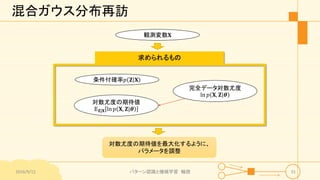
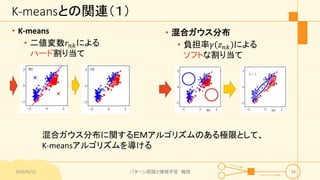
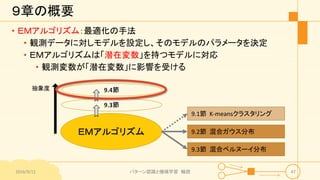
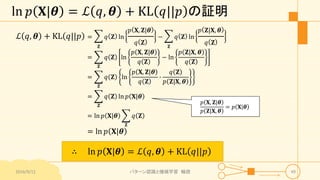
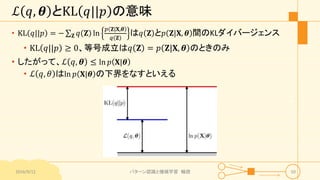
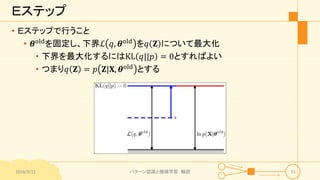
パターン認識と機械学習(PRML)の第9章「混合モデルとEM」について説明したスライドです。文字多め。 潜在変数を持つモデルの最適化を行うことができるEMアルゴリズムについて、最初は具体的でイメージしやすいk-meansクラスタリングから説明し、最後は数式を詳細に見ていきその意味を考察します 9.1 K-meansクラスタリング 9.2 混合ガウス分布 9.3 EMアルゴリズムのもう1つの解釈 9.4 一般のEMアルゴリズム




































































![[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlp-150228215621-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)










![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)

















