もっとベイズ最適化を学びたい⼈向け
ガウス過程とベイズ最適化について
Ø 持橋⼤地, ⼤⽻成征,“ガウス過程と機械学習”. 機械学習プロフェッショナル
シリーズ. 講談社 (2019)
Ø Shahriari, et al. “Taking the human out of the loop: A review of Bayesian
optimization”. In proceedings of the IEEE 104.1 (2015)
ガウス過程以外の最適化⼿法について
Ø James Bergstra, et al. “Algorithms for Hyper-parameter Optimization”. In
NIPS. 2546–2554. (2011)
Ø Hutter, et al. “Sequential Model-based Optimization for General
Algorithm Configuration”. In LION. 507– 523. (2011)
50
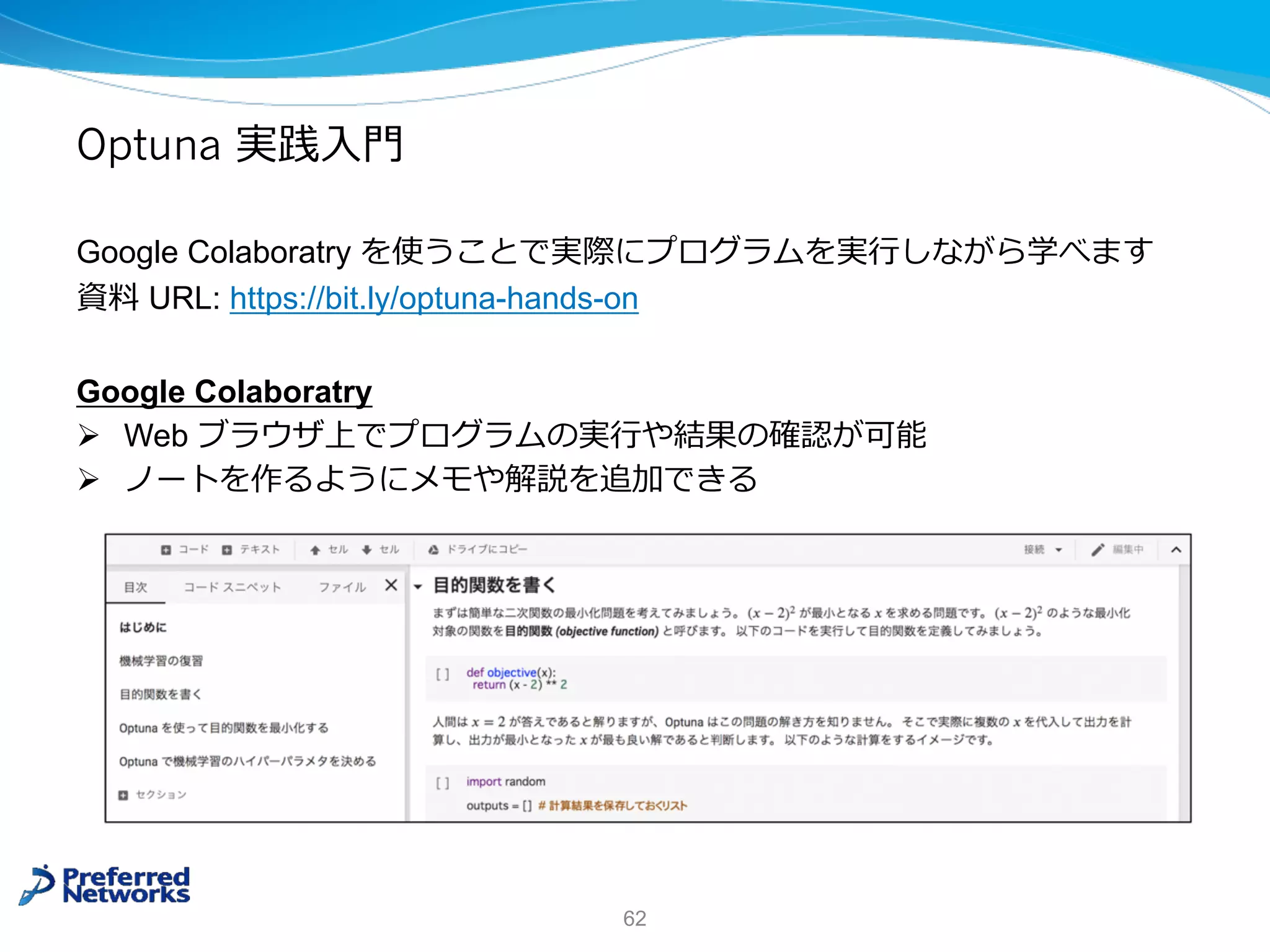
Optuna 実践⼊⾨
Google Colaboratryを使うことで実際にプログラムを実⾏しながら学べます
資料 URL: https://bit.ly/optuna-hands-on
Google Colaboratry
Ø Web ブラウザ上でプログラムの実⾏や結果の確認が可能
Ø ノートを作るようにメモや解説を追加できる
62
参考⽂献リスト
• [1] Akibaet al., “Optuna: A Next-generation Hyperparameter
Optimization Framework”, In KDD, (2019), (to appear)
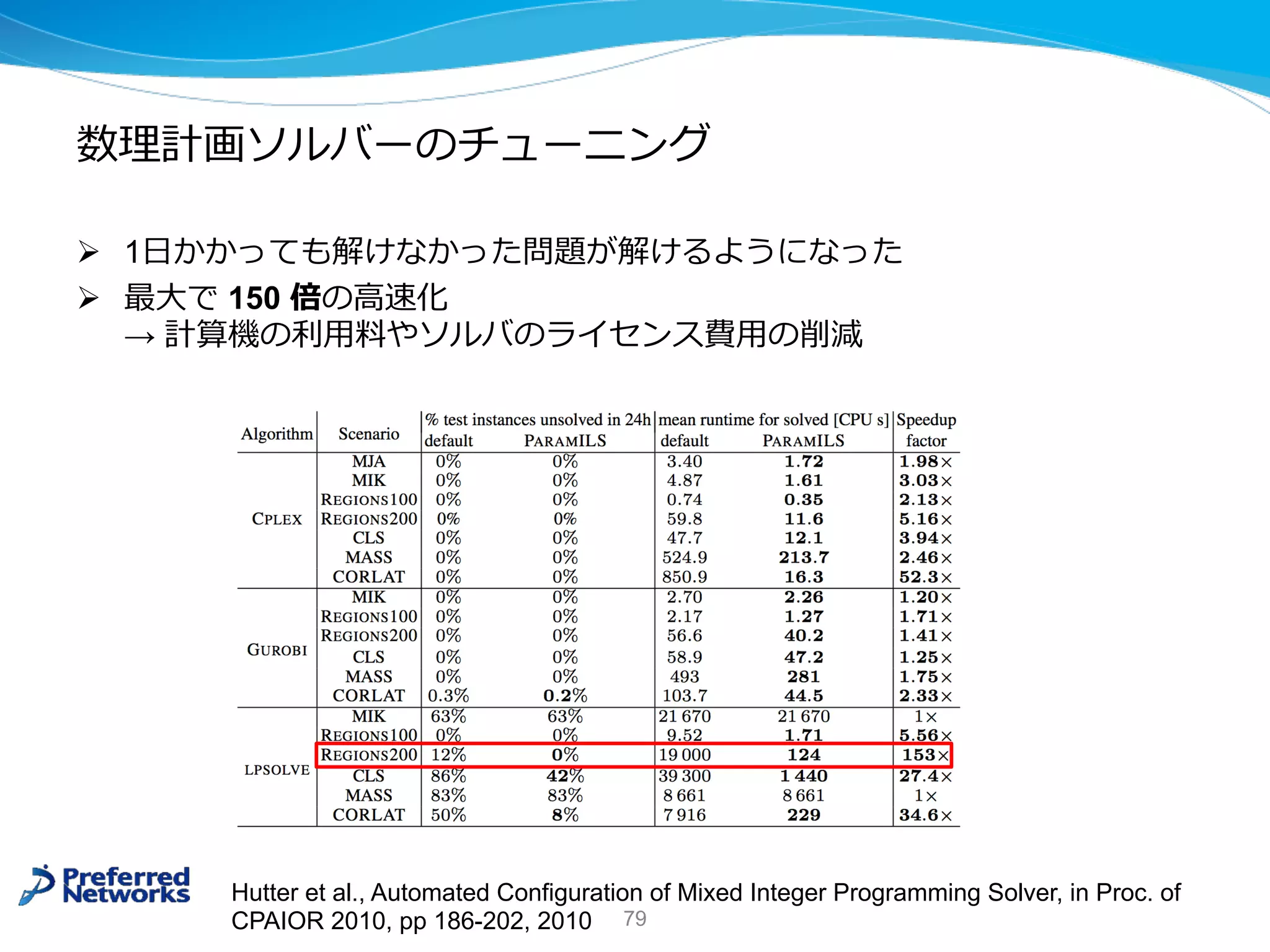
• [2] Hutter et al., “Automated Configuration of Mixed Integer
Programming Solver”, in Proceedings of CPAIOR 2010, pp 186-202,
(2010)
• [3] Solnik et al., “Bayesian Optimization for a Better Dessert”, in
Proceedings of the 2017 NIPS Workshop on Bayesian Optimization, (2017)
• [4] James Bergstra, et al. “Algorithms for Hyper-parameter
Optimization”. In NIPS. 2546–2554. (2011)
• [5] 持橋⼤地, ⼤⽻成征, “ガウス過程と機械学習”. 機械学習プロフェッショ
ナルシリーズ. 講談社 (2019)
• [6] Shahriari, et al. “Taking the human out of the loop: A review of
Bayesian optimization”. In proceedings of the IEEE 104.1 (2015)
• [7] Hutter, et al. “Sequential Model-based Optimization for General
Algorithm Configuration”. In LION. 507– 523. (2011)
80




























![ランダムサーチ
36
⼊⼒
Ø ハイパーパラメタ毎の値の範囲または候補, e.g.,
– x は浮動⼩数点数で [0, 1] の範囲内にある
– y は浮動⼩数点数で {0.0, 0.5, 1.0} のどれか
Ø 探索バジェット
– e.g., 探索回数や制限時間
出⼒
Ø 最適なハイパーパラメタの組み合わせ
– e.g., x: 0.25, y: 0.0
アルゴリズム
1. ハイパーパラメタ毎に指定範囲・候補からランダムに値を選ぶ
2. 選ばれた値の組み合わせでモデルを学習して評価する
3. 1, 2 を探索バジェットが尽きるまで繰り返す
4. 最も評価スコアが良い組み合わせを出⼒する](https://image.slidesharecdn.com/20190628maijihpolecturesano-190628084348/75/slide-36-2048.jpg)




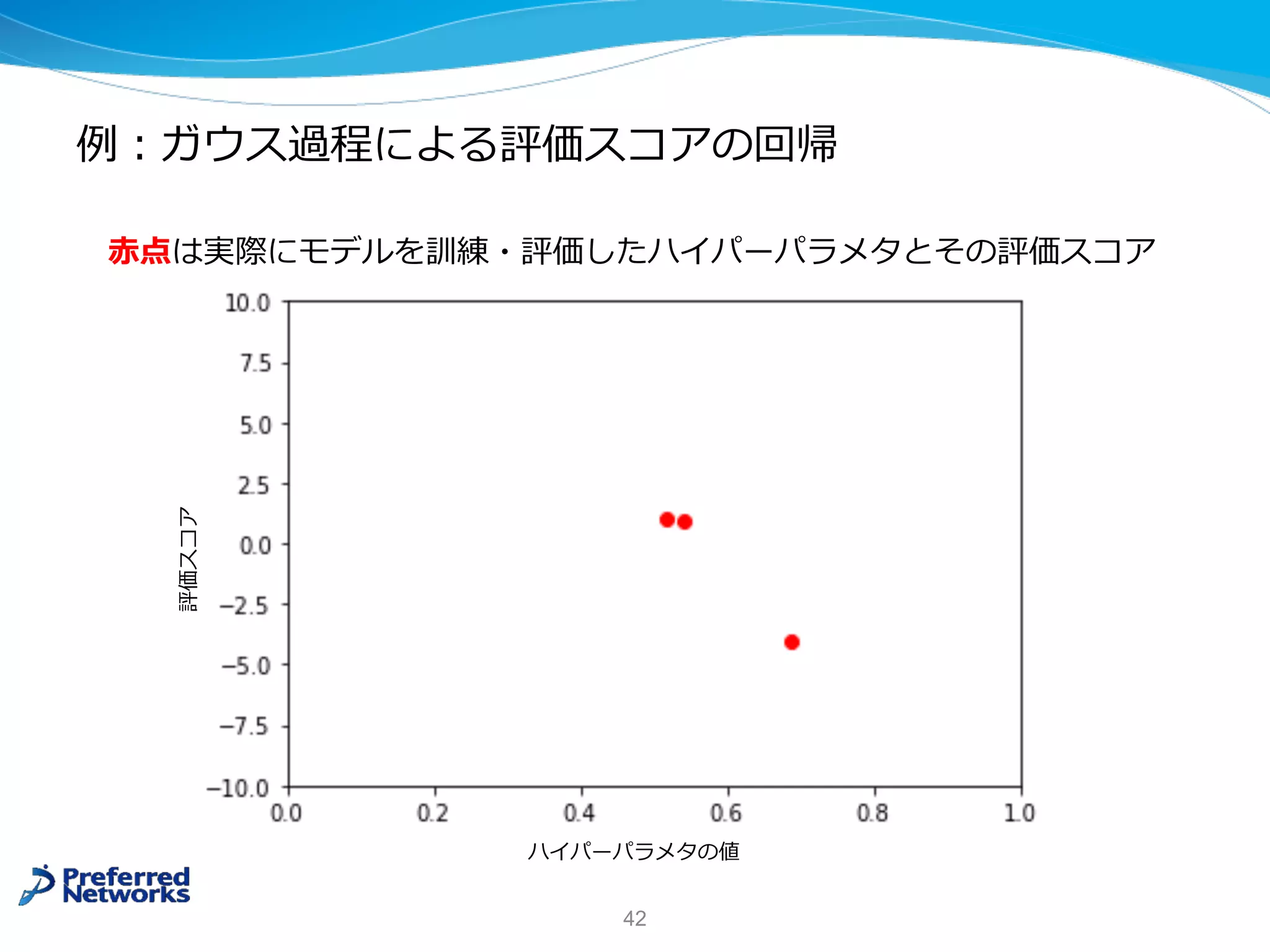
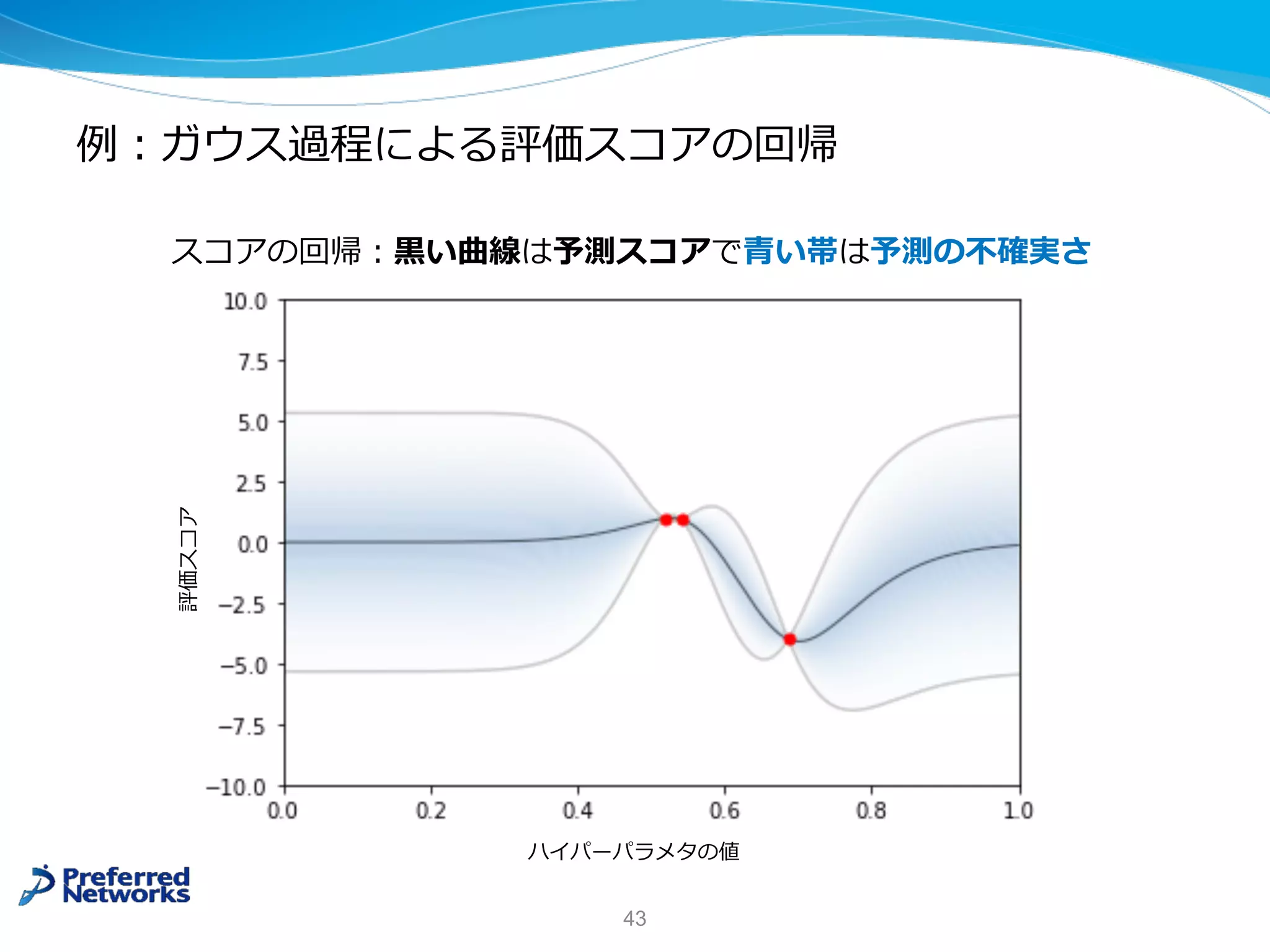
![ガウス過程による評価スコアの回帰
⼀般的な回帰モデル
Ø x に対して予測出⼒ f(x) を出⼒する
*ガウス過程による回帰
Ø x に対して予測出⼒ (平均) μ(x) と予測の不確実さ (分散) σ(x) を出⼒する
* 今回の講義に合わせた直感的な説明となります. より詳しい定義は参考⽂献 [5] などを参照.
41](https://image.slidesharecdn.com/20190628maijihpolecturesano-190628084348/75/slide-41-2048.jpg)








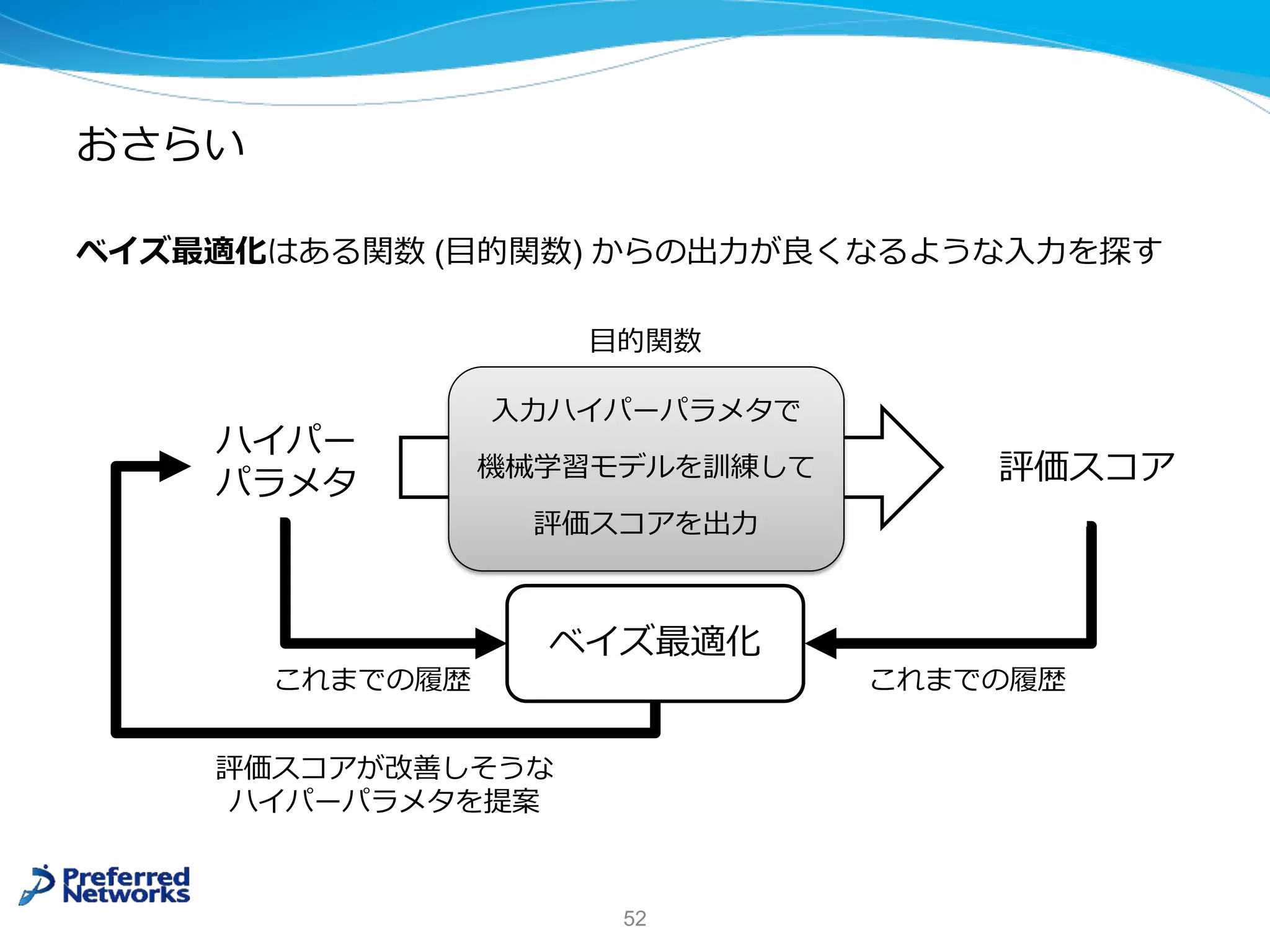

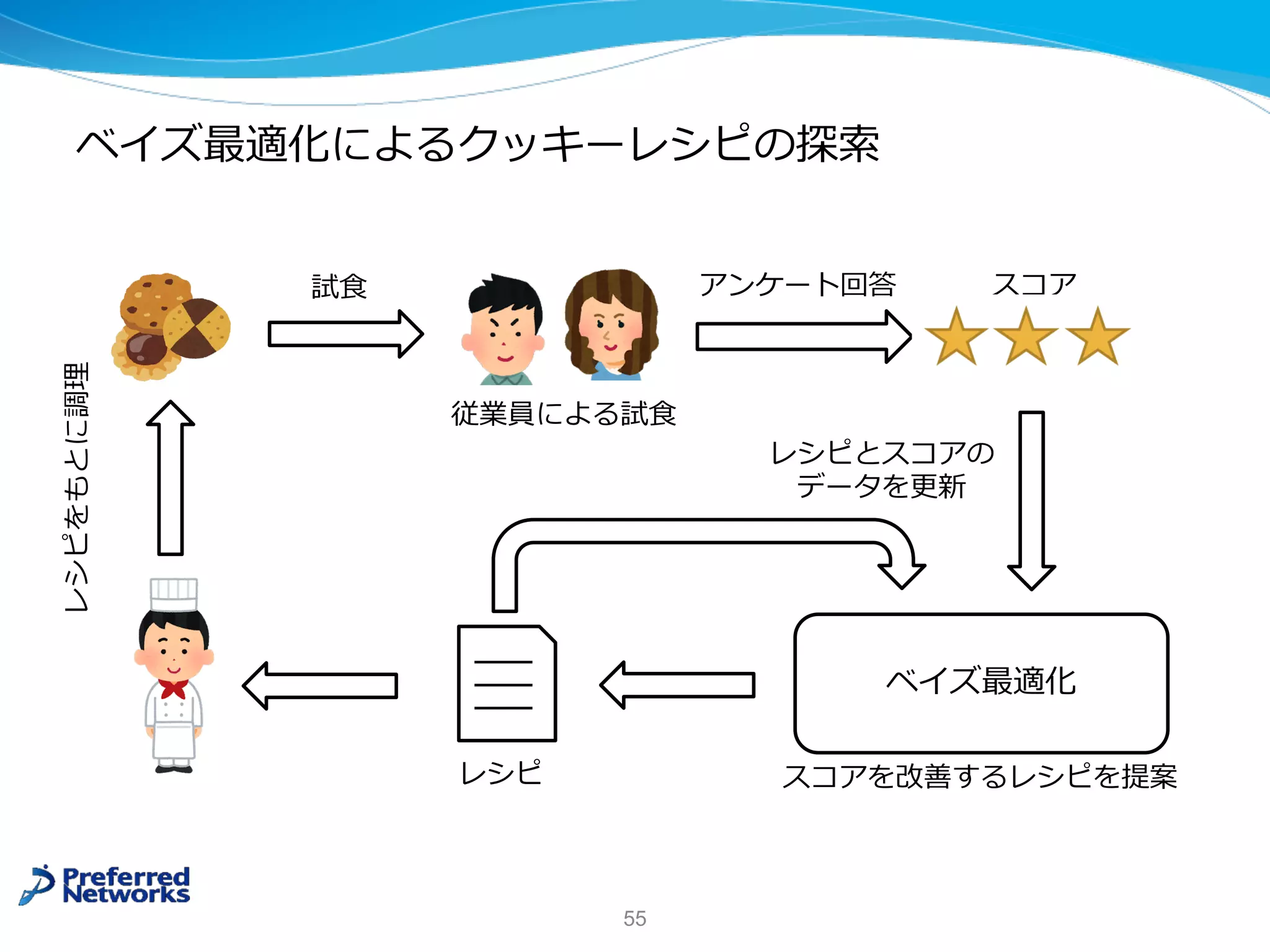




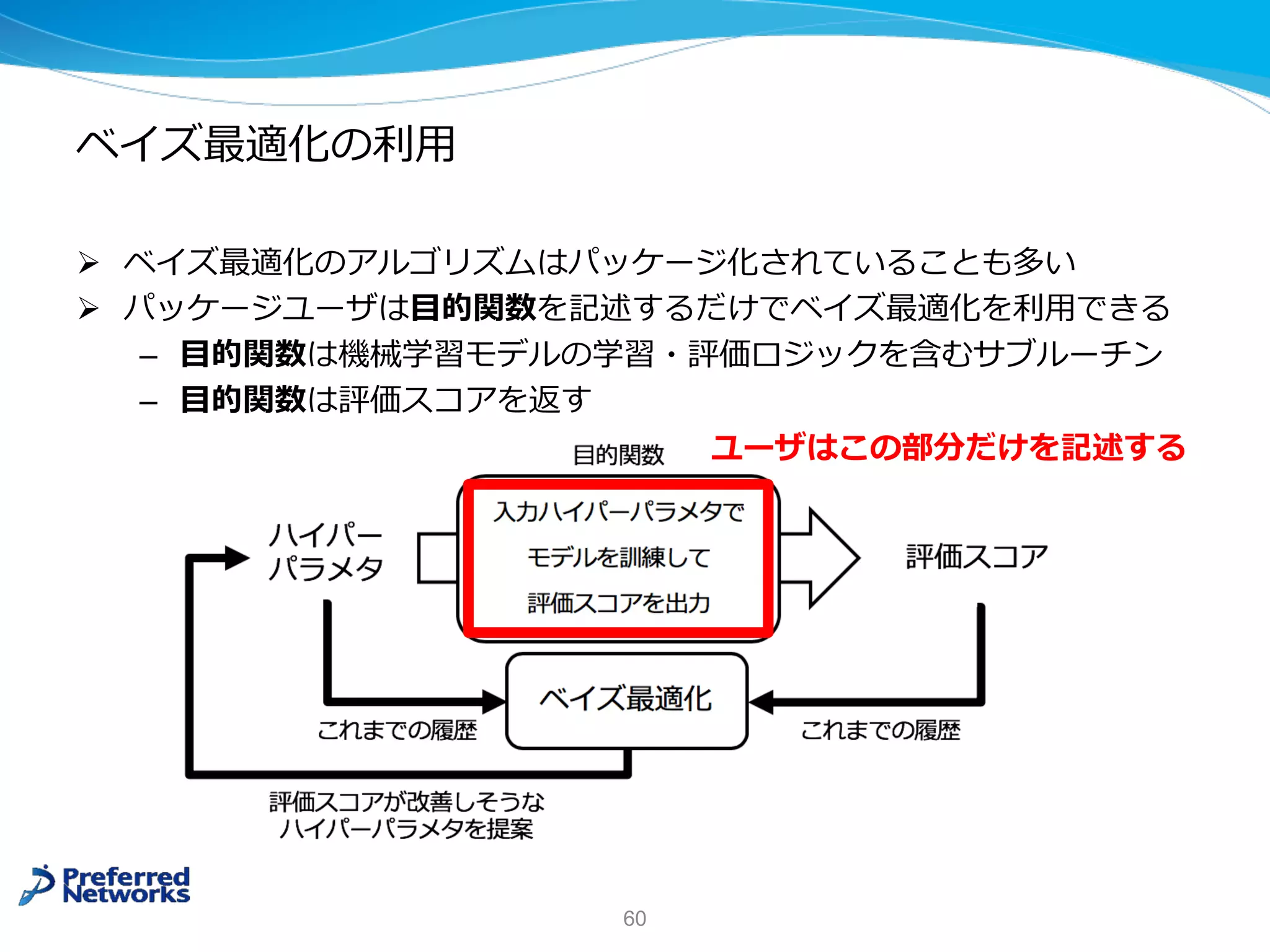
![Optuna
Ø ハイパーパラメタ最適化のための Python ライブラリ
Ø *ベイズ最適化や並列分散実⾏による効率的な⾃動探索
Ø ユーザは⽬的関数を記述するだけでよい
61
*デフォルトでは講義資料と異なるベイズ最適化のアルゴリズムを採⽤しています. 詳しくは参考⽂献 [4] などを参照.](https://image.slidesharecdn.com/20190628maijihpolecturesano-190628084348/75/slide-61-2048.jpg)




![例題︓機械学習のハイパーパラメタ最適化
実験設定
Ø Lasso の alpha を [0.0, 2.0] の範囲で探索
Ø Optuna で 20 回にわたって学習・評価を繰り返した
*結果
Ø エラーを 6.431 ポイント改善するハイパーパラメタを発⾒
Ø 今回のタスクでは alpha を⼤きくしない⽅がよいとわかる
69
alpha Error
Default Setting 1.000 36.631
Optuna Best Setting 0.013 30.200
*具体的な改善値は乱数シードの影響で変化します](https://image.slidesharecdn.com/20190628maijihpolecturesano-190628084348/75/slide-69-2048.jpg)









![参考⽂献リスト
• [1] Akiba et al., “Optuna: A Next-generation Hyperparameter
Optimization Framework”, In KDD, (2019), (to appear)
• [2] Hutter et al., “Automated Configuration of Mixed Integer
Programming Solver”, in Proceedings of CPAIOR 2010, pp 186-202,
(2010)
• [3] Solnik et al., “Bayesian Optimization for a Better Dessert”, in
Proceedings of the 2017 NIPS Workshop on Bayesian Optimization, (2017)
• [4] James Bergstra, et al. “Algorithms for Hyper-parameter
Optimization”. In NIPS. 2546–2554. (2011)
• [5] 持橋⼤地, ⼤⽻成征, “ガウス過程と機械学習”. 機械学習プロフェッショ
ナルシリーズ. 講談社 (2019)
• [6] Shahriari, et al. “Taking the human out of the loop: A review of
Bayesian optimization”. In proceedings of the IEEE 104.1 (2015)
• [7] Hutter, et al. “Sequential Model-based Optimization for General
Algorithm Configuration”. In LION. 507– 523. (2011)
80](https://image.slidesharecdn.com/20190628maijihpolecturesano-190628084348/75/slide-80-2048.jpg)















![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)















































