More Related Content

PDF

PDF

PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法 
PDF

PDF
時系列予測にTransformerを使うのは有効か? 
PDF

PDF
機械学習による統計的実験計画(ベイズ最適化を中心に) 
PDF
What's hot

PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2 
PPT

PDF
Sparse Codingをなるべく数式を使わず理解する(PCAやICAとの関係) 
PDF

PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本 ![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法 
PDF

PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由 ![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎 
PPTX

PDF
混合整数ブラックボックス最適化に向けたCMA-ESの改良 / Optuna Meetup #2 
PDF

PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2 
PPTX

PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks - 
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか- 
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2 ![[DL輪読会]Deep Learning 第17章 モンテカルロ法](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning17-180601024803-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第17章 モンテカルロ法 Similar to ベイズ最適化

PPTX

PDF
【輪読】Taking the Human Out of the Loop, section 8 
PPTX

PPTX

PDF
20210427 grass roots_ml_design_patterns_hyperparameter_tuning 
PDF
Casual learning machine learning with_excel_no3 
PDF

PDF

PDF

PDF
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】 
PPTX

PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification) 
PDF

PDF
20170630 Cognitive Interaction Design @ Kyoto Institute of Technology 
PPTX
数理最適化と機械学習の�融合アプローチ�-分類と新しい枠組み- 
PDF
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム 
PDF

PPTX

PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2) 
PDF
More from MatsuiRyo

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX
Recently uploaded

PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ 
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1 
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2 
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと... 
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup 
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool ベイズ最適化
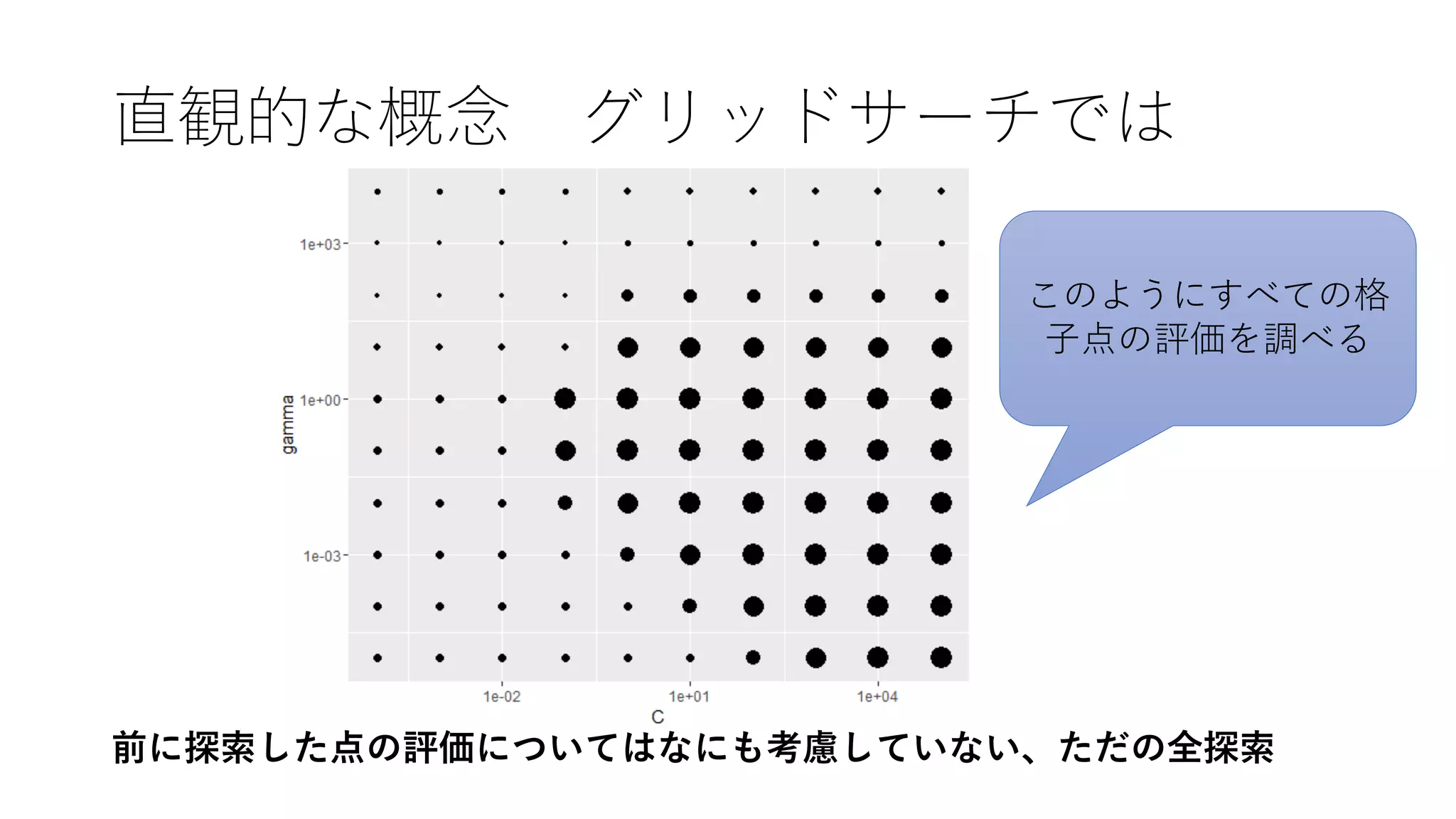
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
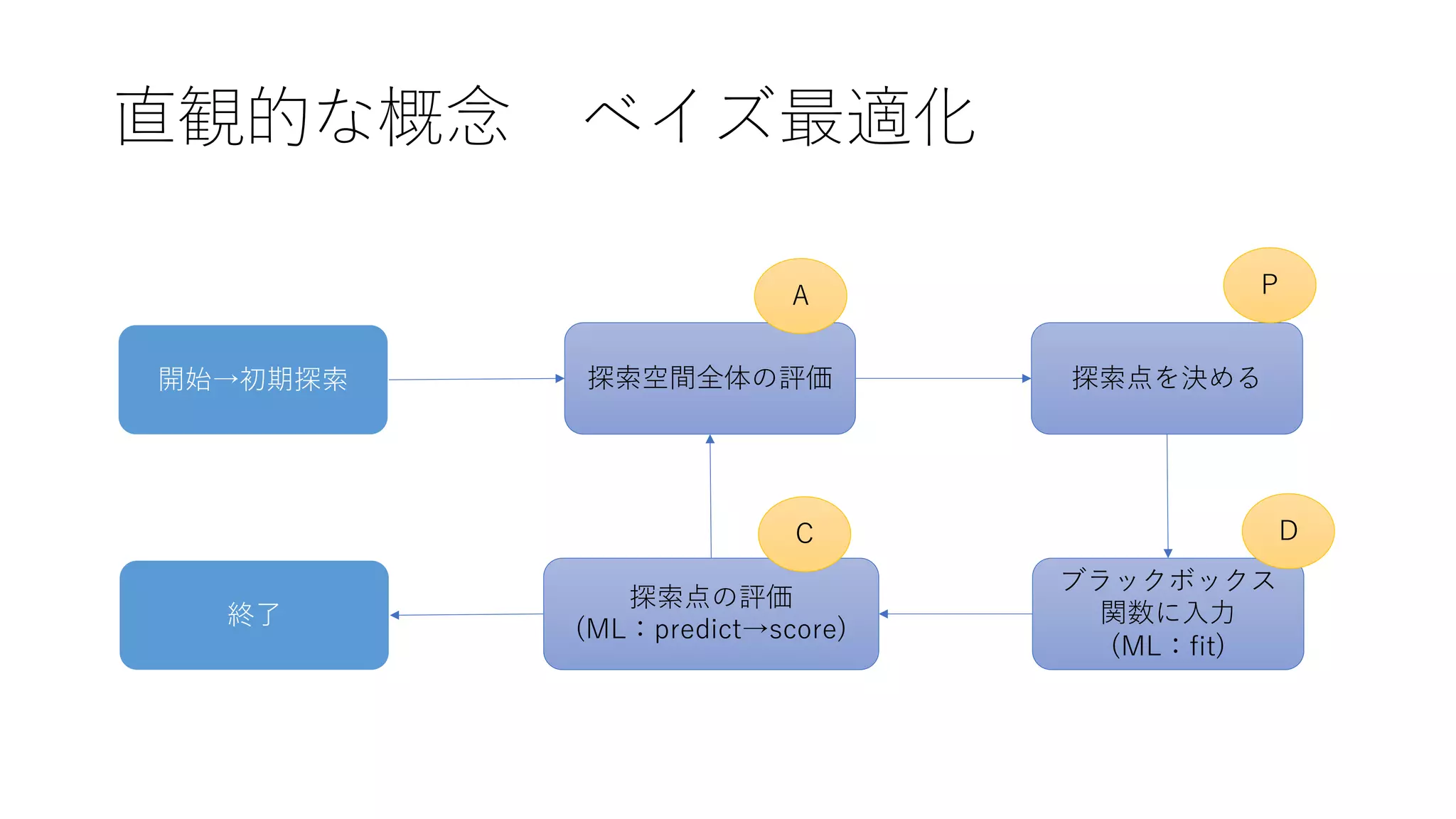
Action:探索空間全体の評価
⼊⼒と出⼒の関係
𝒙!
∶ ( 𝑥!
!
,𝑥"
!
, ⋯ , 𝑥#
!
)$
−−→ 𝑦!
−−→ 𝑡!
𝒙" ∶ ( 𝑥!
"
, 𝑥"
"
, ⋯ , 𝑥#
" )$ −−→ 𝑦" −−→ 𝑡"
⋮
𝒙%
: ( 𝑥!
%
, 𝑥"
%
, ⋯ , 𝑥#
%
)$
−−→ 𝑦%
−−→ 𝑡%
⼊⼒ 真の関数値 実現値(観測値)
ブ
ラ
ッ
ク
ボ
ッ
ク
ス
関
数
ノ
イ
ズ
- 13.
- 14.
諸々の定義𝒙 𝟏
~ 𝒙𝑵
: ⼊⼒(ハイパーパラメータ群)
𝒚 𝑵
: ( 𝑦#
, 𝑦$
, ⋯ , 𝑦%
)&
N点の真の関数値ベクトル
𝒕 𝑵
: ( 𝑡#
, 𝑡$
, ⋯ , 𝑡%
)&
N点の実現値ベクトル
𝜙# ~ 𝜙': 基底関数群
𝜱 =
𝜙#(𝒙 𝟏
) 𝜙$(𝒙 𝟏
)
𝜙#(𝒙 𝟐
) 𝜙$(𝒙 𝟐
)
… 𝜙'(𝒙 𝟏
)
… 𝜙'(𝒙 𝟐
)
⋮ ⋮
𝜙#(𝒙 𝑵
) 𝜙$(𝒙 𝑵
)
⋱ ⋮
… 𝜙'(𝒙 𝑵
)
𝒌 = (𝑘 𝒙 𝟏
, 𝒙 𝑵)𝟏
, 𝑘 𝒙 𝟐
, 𝒙 𝑵)𝟏
, ⋯ , 𝑘 𝒙 𝑵
, 𝒙 𝑵)𝟏
)&
i⾏⽬をベクトル化
𝜙(𝒙𝒊
)
𝑘 𝒙𝒊
, 𝒙𝒋
= 𝛼*!
𝜙(𝒙𝒊
)$
𝜙(𝒙𝒋
)
Φのカーネル関数
- 15.
𝒙 𝟏
~𝒙 𝑵
,𝒕 𝑵
(𝑡#
~𝑡%
)を知ったうえで、次に追加する未知な点𝒙 𝑵)𝟏
の評価値の実現値が 𝑡 となる確率 𝑃 𝑡 𝒕 𝑵
)の分布は正規分布となり、
その平均と分散は以下のように𝒙 𝑵)𝟏
の関数としてあらわされる。
𝝁 𝒙 𝑵)𝟏
= 𝛼*#
𝒌𝚽𝚽 𝑻
𝒕 𝑵
𝝈 𝒙 𝑵)𝟏
= 𝑘 𝒙 𝑵)𝟏
, 𝒙 𝑵)𝟏
+ 𝛽*#
− 𝒌 𝑻
𝑪 𝑵
*𝟏
𝒌
Action:探索空間全体の評価
これによって、空間全体の評価値(実現値)の分布が特定できた。
- 16.
Plan : 探索点の決定
全点の評価値の分布が分かった→ ではどの点を次に選ぶか?
• PI戦略(Probability of Improvement)
• EI戦略(Expected Improvement)
• UCB戦略(Upper Confidence Band)
(LCB戦略(Lower Confidence Band))
これらに基づいた評価関数を獲得関数と呼ぶ
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
カーネルの種類
• Squared ExponentialKernel
𝑘!" 𝑥#
, 𝑥$
= exp −
𝑥# − 𝑥$ %
2𝑙%
• Matern Kernel
𝑘&'()*+ 𝑥#
, 𝑥$
=
2,-.
Γ(𝜈)
(
2𝜈 𝑥#
− 𝑥$
𝑙
).
𝐾.(
2𝜈 𝑥#
− 𝑥$
𝑙
)
など
カーネル法全般の解説:http://enakai00.hatenablog.com/entry/2017/10/13/145337
- 23.
実装:
GPyOptでXgboostのハイパーパラメータ最適化
def blackbox(x):
learning_rate =float(x[:,0])
subsample = float(x[:,1])
colsample_bytree = float(x[:,2])
gamma = float(x[:,3])
reg_lambda = float(x[:,4])
max_depth = int(x[:,5])
n_estimators = int(x[:,6])
XGB_instance = xgb.XGBRegressor(learning_rate = learning_rate,
subsample = subsample,
colsample_bytree = colsample_bytree,
gamma = gamma,
reg_lambda = reg_lambda,
max_depth = max_depth,
n_estimators = n_estimators,
objective = "reg:linear")
scores = cross_val_score(XGB_instance,X_train,y_train,cv=4,scoring='mean_squared_errorʻ)
return -scores.mean()
xは1×nの⼆次元リス
トで渡されるので、各
パラメータを型変換
渡されたハイパーパ
ラメータでインスタ
ンス化
sklearnの
cross_val_scoreで
評価値を計算
・機械学習の⼀連の流れを関数として定義
- 24.
実装:
GPyOptでXgboostのハイパーパラメータ最適化
・探索してほしいハイパーパラメータの名前と値の範囲、連続or離散を以下のように定義
bounds = [{'name':'learning_rate','type': 'continuous', 'domain': (0.0005,0.3)},
{'name': 'sub_sample','type': 'continuous', 'domain': (0.5,1)},
{'name': 'colsample_bytree','type': 'continuous', 'domain': (0.5,1)},
{'name': 'gamma','type': 'continuous', 'domain': (0,1)},
{'name': 'reg_lambda','type': 'continuous', 'domain': (0,1)},
{'name': 'max_depth','type': 'discrete', 'domain': tuple(list(range(3,8)))},
{'name': 'n_estimator','type': 'discrete', 'domain': tuple(list(range(30,210,10)))}]
continuous:連続 discrete:離散 (continuous→discreteの順でないとエラーになる)
- 25.
実装:
GPyOptでXgboostのハイパーパラメータ最適化
・最適化を⾏うクラスをインスタンス化し、run_optimizeメソッドで最適化を実⾏
initial_design_numdata:初期探索の回数
acquisition_type:獲得関数の設定
max_iter:最⼤探索回数
XGB_Bopt = GPyOpt.methods.BayesianOptimization(f=blackbox,
domain=bounds,
initial_design_numdata=5,
acquisition_type='LCB')
XGB_Bopt.run_optimization(max_iter=15)
・最適化終了後、x_opt,fx_optメソッドで最適解、最適値を出⼒
print(XGB_Bopt.x_opt,XGB_Bopt.fx_opt)
→ array([ 0.20040502, 0.68832784, 0.66486351, 0.81031615, 0.66657359, 5, 140. ]),array([ 0.50715448])
- 26.




















![実装:
GPyOptでXgboostのハイパーパラメータ最適化
def blackbox(x):
learning_rate = float(x[:,0])
subsample = float(x[:,1])
colsample_bytree = float(x[:,2])
gamma = float(x[:,3])
reg_lambda = float(x[:,4])
max_depth = int(x[:,5])
n_estimators = int(x[:,6])
XGB_instance = xgb.XGBRegressor(learning_rate = learning_rate,
subsample = subsample,
colsample_bytree = colsample_bytree,
gamma = gamma,
reg_lambda = reg_lambda,
max_depth = max_depth,
n_estimators = n_estimators,
objective = "reg:linear")
scores = cross_val_score(XGB_instance,X_train,y_train,cv=4,scoring='mean_squared_errorʻ)
return -scores.mean()
xは1×nの⼆次元リス
トで渡されるので、各
パラメータを型変換
渡されたハイパーパ
ラメータでインスタ
ンス化
sklearnの
cross_val_scoreで
評価値を計算
・機械学習の⼀連の流れを関数として定義](https://image.slidesharecdn.com/bayseopt-200303133246/75/slide-23-2048.jpg)
![実装:
GPyOptでXgboostのハイパーパラメータ最適化
・探索してほしいハイパーパラメータの名前と値の範囲、連続or離散を以下のように定義
bounds = [{'name': 'learning_rate','type': 'continuous', 'domain': (0.0005,0.3)},
{'name': 'sub_sample','type': 'continuous', 'domain': (0.5,1)},
{'name': 'colsample_bytree','type': 'continuous', 'domain': (0.5,1)},
{'name': 'gamma','type': 'continuous', 'domain': (0,1)},
{'name': 'reg_lambda','type': 'continuous', 'domain': (0,1)},
{'name': 'max_depth','type': 'discrete', 'domain': tuple(list(range(3,8)))},
{'name': 'n_estimator','type': 'discrete', 'domain': tuple(list(range(30,210,10)))}]
continuous:連続 discrete:離散 (continuous→discreteの順でないとエラーになる)](https://image.slidesharecdn.com/bayseopt-200303133246/75/slide-24-2048.jpg)
![実装:
GPyOptでXgboostのハイパーパラメータ最適化
・最適化を⾏うクラスをインスタンス化し、run_optimizeメソッドで最適化を実⾏
initial_design_numdata:初期探索の回数
acquisition_type:獲得関数の設定
max_iter:最⼤探索回数
XGB_Bopt = GPyOpt.methods.BayesianOptimization(f=blackbox,
domain=bounds,
initial_design_numdata=5,
acquisition_type='LCB')
XGB_Bopt.run_optimization(max_iter=15)
・最適化終了後、x_opt,fx_opt メソッドで最適解、最適値を出⼒
print(XGB_Bopt.x_opt,XGB_Bopt.fx_opt)
→ array([ 0.20040502, 0.68832784, 0.66486351, 0.81031615, 0.66657359, 5, 140. ]),array([ 0.50715448])](https://image.slidesharecdn.com/bayseopt-200303133246/75/slide-25-2048.jpg)
