Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
hoxo_m
4,536 views
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択
Data & Analytics
◦
Read more
8
Save
Share
Embed
Embed presentation
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PRML学習者から入る深層生成モデル入門
by
tmtm otm
機械学習のためのベイズ最適化入門
by
hoxo_m
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
What's hot
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
Graph Neural Networks
by
tm1966
PDF
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
【DL輪読会】Scaling laws for single-agent reinforcement learning
by
Deep Learning JP
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
PDF
ウィナーフィルタと適応フィルタ
by
Toshihisa Tanaka
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PPTX
K shapes zemiyomi
by
kenyanonaka
PDF
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PDF
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
PDF
ナレッジグラフとオントロジー
by
University of Tsukuba
PDF
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Graph Neural Networks
by
tm1966
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
【DL輪読会】Scaling laws for single-agent reinforcement learning
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
ウィナーフィルタと適応フィルタ
by
Toshihisa Tanaka
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
K shapes zemiyomi
by
kenyanonaka
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
ナレッジグラフとオントロジー
by
University of Tsukuba
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
Similar to トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
PDF
論文紹介:ProbVLM: Probabilistic Adapter for Frozen Vison-Language Models
by
Toru Tamaki
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
Probabilistic Graphical Models 輪読会 #1
by
Takuma Yagi
PDF
E-SOINN
by
SOINN Inc.
PDF
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con...
by
Akira Taniguchi
PDF
機械学習
by
Hikaru Takemura
PDF
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
PPTX
データマイニングにおける属性構築、事例選択
by
無職
PDF
KDD2014 勉強会
by
Ichigaku Takigawa
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PDF
実践・最強最速のアルゴリズム勉強会 第三回講義資料(ワークスアプリケーションズ & AtCoder)
by
AtCoder Inc.
論文紹介:ProbVLM: Probabilistic Adapter for Frozen Vison-Language Models
by
Toru Tamaki
ノンパラベイズ入門の入門
by
Shuyo Nakatani
Probabilistic Graphical Models 輪読会 #1
by
Takuma Yagi
E-SOINN
by
SOINN Inc.
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con...
by
Akira Taniguchi
機械学習
by
Hikaru Takemura
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
データマイニングにおける属性構築、事例選択
by
無職
KDD2014 勉強会
by
Ichigaku Takigawa
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
実践・最強最速のアルゴリズム勉強会 第三回講義資料(ワークスアプリケーションズ & AtCoder)
by
AtCoder Inc.
More from hoxo_m
PDF
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PDF
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
PDF
学習係数
by
hoxo_m
PDF
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
PDF
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
PPTX
高速なガンマ分布の最尤推定法について
by
hoxo_m
PDF
経験過程
by
hoxo_m
PDF
確率論基礎
by
hoxo_m
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
協調フィルタリング入門
by
hoxo_m
PDF
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
PDF
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
PDF
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
PDF
チェビシェフの不等式
by
hoxo_m
PDF
swirl パッケージでインタラクティブ学習
by
hoxo_m
PPTX
RPubs とその Bot たち
by
hoxo_m
PPTX
5分でわかるベイズ確率
by
hoxo_m
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
学習係数
by
hoxo_m
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
高速なガンマ分布の最尤推定法について
by
hoxo_m
経験過程
by
hoxo_m
確率論基礎
by
hoxo_m
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
階層モデルの分散パラメータの事前分布について
by
hoxo_m
協調フィルタリング入門
by
hoxo_m
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
チェビシェフの不等式
by
hoxo_m
swirl パッケージでインタラクティブ学習
by
hoxo_m
RPubs とその Bot たち
by
hoxo_m
5分でわかるベイズ確率
by
hoxo_m
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
1.
『トピックモデルによる統計的潜在意味解析』読書会 3.7 評価⽅方法 〜~
3.9 モデル選択 @hoxo_m 2016/01/28 1
2.
⾃自⼰己紹介 • hoxo_m •
所属:匿匿名知的集団ホクソエム
3.
本⽇日の内容 • 3.7 評価⽅方法 – 3.7.1
Perplexity – 3.7.2 アルゴリズム別 Perplexity の計算⽅方法 – 3.7.3 新規⽂文書における Perplexity – 3.7.4 Coherence • 3.8 各種学習アルゴリズムの⽐比較 • 3.9 モデル選択 3
4.
3.7 評価⽅方法 • トピックモデルの評価指標として Perplexity
と Coherence の 2 つが広く 使われている。 • Perplexity:予測性能 • Coherence:トピックの品質 • 拡張モデルに対しては⽬目的に応じた評価 指標が使われる 4
5.
Perplexity とは • 辞書で引くと・・ – the
feeling of being confused or worried by something you cannot understand (理理解できないものにより困惑する感覚) 5 http://www.ldoceonline.com/dictionary/perplexity ⇨ ⽇日本語で考えるのはやめよう
6.
Perplexity とは • ①〜~⑤の⽬目が出るスロットマシン •
予測モデル M を作成 • 次に出たスロットの⽬目 n • P(n | M) が⾼高いほど良良い予測モデル • 予測モデルに従って正解を当てるための 困難さ = Perplexity 6
7.
Perplexity とは • 予測モデルがない場合 ①1/5 ②1/5 ③1/5 ④1/5 ⑤1/5 •
それぞれの⽬目が出る確率率率は等しい • P(n) = 1/5 • 選択肢は 5 つ( = 1/P(n) ) • 5 つの中から 1 つを選ぶという困難さ 7
8.
Perplexity とは • 予測モデル
M がある場合 ①1/2 ②1/8 ③1/8 ④1/8 ⑤1/8 • 実際に出た⽬目が①だった ⇨ P(①|M) = 1/2 • ①が出る確率率率とその他が出る確率率率は等しい • ①を選ぶかその他を選ぶか、選択肢が 2 つ あったのと同じ ( = 2 つから 1 つを選ぶ困難さ) 8
9.
Perplexity とは • 予測モデル
M がある場合 ①1/2 ②1/8 ③1/8 ④1/8 ⑤1/8 • 実際に出た⽬目が②だった ⇨ P(②|M) = 1/8 • 正解するには他の選択肢の誘惑をすべて 振り切切る必要があった • 誘惑度度:①4 ②1 ③1 ④1 ⑤1 • 選択肢が 8 つあったのと同じ困難さ 9
10.
Perplexity とは • Perplexity
は、予測モデルに従って正解 を当てるためのある種の困難性である • Perplexity が低いほど、困難性は⼩小さい • Perplexity は、予測モデルにおける予測 確率率率の逆数である PPL = 1 / P(n | M) • 選択肢が PPL 個あったのと同じ困難さ 10
11.
Perplexity とは • 予測モデルに反して②ばかり出ると、 Perplexity
は予測なしより悪くなる • 予測モデルに従って ①①①①②③④⑤ と 出た場合 • Perplexity の平均値は 5 (予測なしと同じ) (2+2+2+2+8+8+8+8)/8 = 5 • この場合、幾何平均(相乗平均)を取るべき (2*2*2*2*8*8*8*8)^(1/8) = 4 11
12.
3.7.1 Perplexity • トピックモデルの
Perplexity • モデル M のもとで単語 w が得られる確率率率 の逆数 • PPL[w|M] = 1 / p(w | M) • テストデータ中の全ての単語に対してこ れを計算し、幾何平均(相乗平均)を取る 12
13.
13 ⇦ 相乗平均 ⇦ 対数尤度度
14.
Perplexity の計算 • LDA
において、単語の出現確率率率 p(w|M) は、各トピックにおいて w が出現する 確率率率の積分 • Φk,w : トピック k における単語 w の出現確率率率 • θd,k : ⽂文書 d におけるトピック k の出現確率率率 14
15.
3.7.2 Perplexity の計算⽅方法 •
学習アルゴリズムによっては、Φk や θd が 求まらない(ベイズなので分布している) ① ギブスサンプリング ② 周辺化ギブスサンプリング ③ 変分ベイズ ④ 周辺化変分ベイズ • 各種アルゴリズムにおける Perplexity の 計算⽅方法を⽰示す 15
16.
① ギブスサンプリング • 求まるのは
Φk および θd のサンプル • サンプル全体の平均確率率率を出す • S : サンプリング数 16
17.
② 周辺化ギブスサンプリング • 求まるのは単語に割り当てられたトピック
z の サンプル • ただし、nk,w および nd,k も同時にサンプリング されるので、これを使えば近似的に Φk および θd が求まる 17 ※事前分布の情報を⼊入れよう!
18.
③ 変分ベイズ • 求まるのは
p(Φ, θ) の近似事後分布 q(Φ)q(θ) 18
19.
④ 周辺化変分ベイズ • 求まるのは
p(z) の近似事後分布 q(z) • 同じ戦略略を取ると・・・ 19
20.
④ 周辺化変分ベイズ • この式は解析的には求まらない・・・ ⇨
q(z) からサンプリングして近似計算? • 細かいことは気にせず、変分ベイズとき の式をそのまま使う! 20
21.
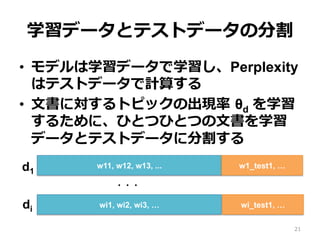
学習データとテストデータの分割 • モデルは学習データで学習し、Perplexity はテストデータで計算する •
⽂文書に対するトピックの出現率率率 θd を学習 するために、ひとつひとつの⽂文書を学習 データとテストデータに分割する 21 w11, w12, w13, ... wi1, wi2, wi3, … d1 di ・・・ w1_test1, … wi_test1, …
22.
3.7.3 新規⽂文書における Perplexity •
新規⽂文書に対しても、学習⽤用とテスト⽤用 に分ける 22 w11, w12, w13, ... wi1, wi2, wi3, … d1 di ・・・ wj1, wj2, wj3, …dj wj_test1, … ・・・ 学 習 ⽤用 テスト⽤用
23.
3.7.4 Coherence • Coherence:
抽出されたトピックの品質 • 意味の近い単語が集まっているトピック をより多く抽出できる⼿手法が良良いモデル • 詳しくは LT で! 23
24.
本⽇日の内容 • 3.7 評価⽅方法 – 3.7.1
Perplexity – 3.7.2 アルゴリズム別 Perplexity の計算⽅方法 – 3.7.3 新規⽂文書における Perplexity – 3.7.4 Coherence • 3.8 各種学習アルゴリズムの⽐比較 • 3.9 モデル選択 24
25.
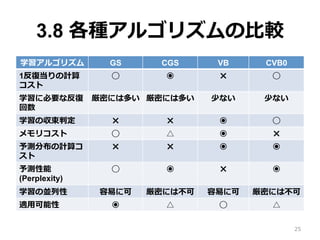
3.8 各種アルゴリズムの⽐比較 学習アルゴリズム GS
CGS VB CVB0 1反復復当りの計算 コスト ◯ ◉ ✖ ◯ 学習に必要な反復復 回数 厳密には多い 厳密には多い 少ない 少ない 学習の収束判定 ✖ ✖ ◉ ◯ メモリコスト ◯ △ ◉ ✖ 予測分布の計算コ スト ✖ ✖ ◉ ◉ 予測性能 (Perplexity) ◯ ◉ ✖ ◉ 学習の並列列性 容易易に可 厳密には不不可 容易易に可 厳密には不不可 適⽤用可能性 ◉ △ ◯ △ 25
26.
本⽇日の内容 • 3.7 評価⽅方法 – 3.7.1
Perplexity – 3.7.2 アルゴリズム別 Perplexity の計算⽅方法 – 3.7.3 新規⽂文書における Perplexity – 3.7.4 Coherence • 3.8 各種学習アルゴリズムの⽐比較 • 3.9 モデル選択 26
27.
3.9 モデル選択 • LDA
におけるトピック数の決定法 1. データを学習⽤用、テスト⽤用に分ける 2. 特定のトピック数を⽤用いて LDA を学習し、 テストデータで Perplexity を求める 3. LDA 学習時に必要な初期値を変えて学習を 繰り返し、Perplexity の平均を求める 4. トピック数で⽐比較し、最も良良いものを選ぶ 27
28.
3.9 モデル選択 • 変分ベイズ法の場合、変分下限がモデル 選択の基準になる 1.
特定のトピック数に対して LDA を学習し、 変分下限の値を求める 2. 初期値を変えて学習を繰り返し、変分下限の 値の平均を求める 3. トピック数で⽐比較し、最も良良いものを選ぶ • 変分下限は学習データのみから求められ るため、テストデータは必要無い 28
29.
3.9 モデル選択 • Perplexity
の値は結構ばらつくので平均 値を求めているのかなぁと思いました。 • 参照: LDA のパープレキシティを使うとき 29
30.
まとめ • 主要な LDA
ライブラリは Perplexity を 計算してくれるので安⼼心してください! • gensim: log_perplexity() • scikit-learn: perplexity() • MLlib: logPerplexity() 30











![3.7.1 Perplexity
• トピックモデルの Perplexity
• モデル M のもとで単語 w が得られる確率率率
の逆数
• PPL[w|M] = 1 / p(w | M)
• テストデータ中の全ての単語に対してこ
れを計算し、幾何平均(相乗平均)を取る
12](https://image.slidesharecdn.com/20160128-160128103031/85/3-7-3-9-12-320.jpg)
























![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)












































