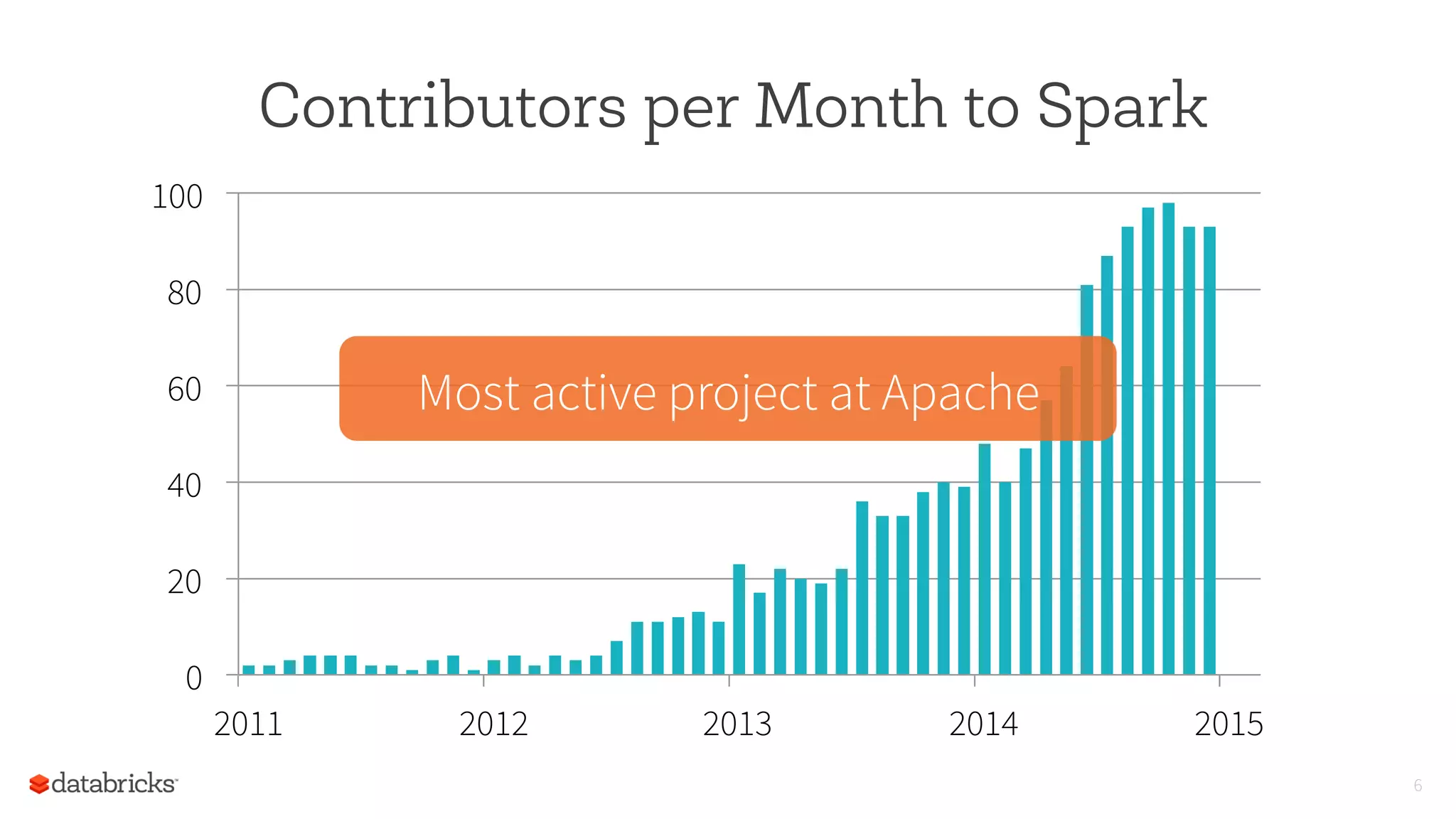
Downloaded 385 times








![10
DataFrames
Similar API to data frames
in R and Pandas
Automatically optimized
via Spark SQL
Coming in Spark 1.3
df = jsonFile(“tweets.json”)
df[df[“user”] == “matei”]
.groupBy(“date”)
.sum(“retweets”)
0
5
10
Python Scala DataFrame
RunningTime](https://image.slidesharecdn.com/zaharia-150223111033-conversion-gate01/75/New-directions-for-Apache-Spark-in-2015-10-2048.jpg)
![11
R Interface (SparkR)
Arrives in Spark 1.4 (June)
Exposes DataFrames,
RDDs, and ML library in R
df = jsonFile(“tweets.json”)
summarize(
group_by(
df[df$user == “matei”,],
“date”),
sum(“retweets”))](https://image.slidesharecdn.com/zaharia-150223111033-conversion-gate01/75/New-directions-for-Apache-Spark-in-2015-11-2048.jpg)
![12
Machine Learning Pipelines
High-level API inspired by
SciKit-Learn
Featurization, evaluation,
model tuning
tokenizer = Tokenizer()
tf = HashingTF(numFeatures=1000)
lr = LogisticRegression()
pipe = Pipeline([tokenizer, tf, lr])
model = pipe.fit(df)
tokenizer TF LR
modelDataFrame](https://image.slidesharecdn.com/zaharia-150223111033-conversion-gate01/75/New-directions-for-Apache-Spark-in-2015-12-2048.jpg)
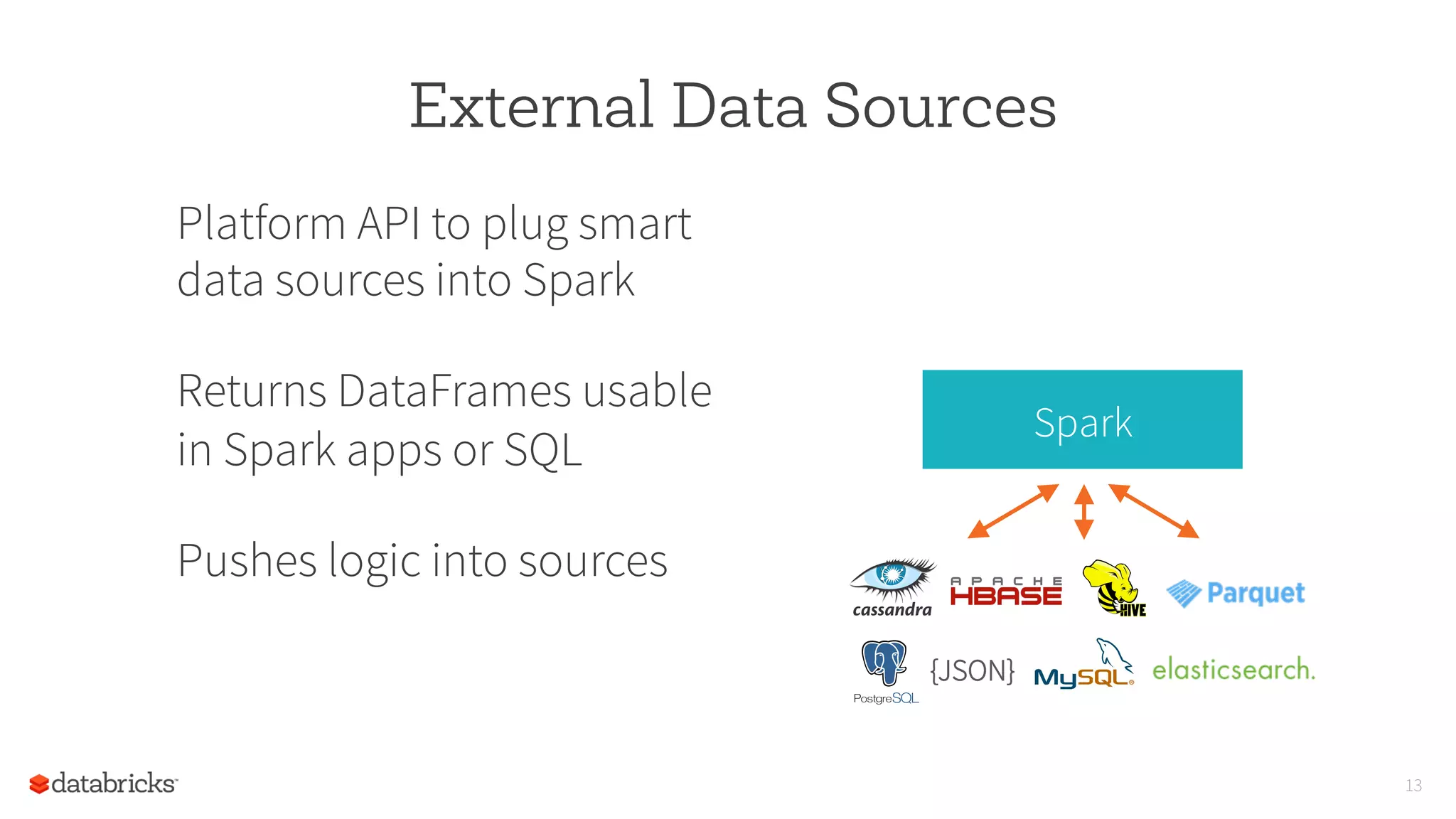
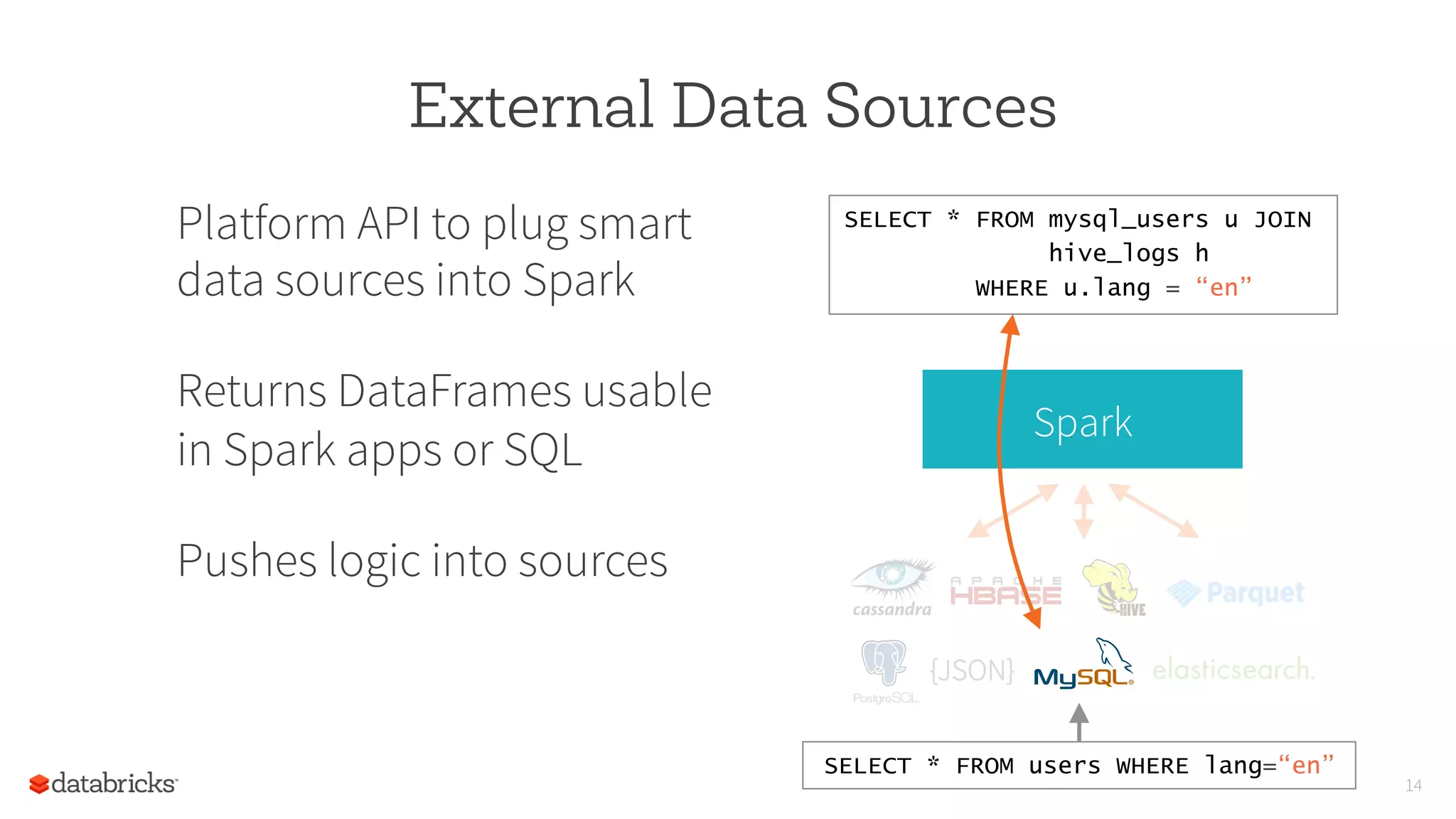



This document discusses new directions for Apache Spark in 2015, including improved interfaces for data science, external data sources, and machine learning pipelines. It also summarizes Spark's growth in 2014 with over 500 contributors, 370,000 lines of code, and 500 production deployments. The author proposes that Spark will become a unified engine for all data sources, workloads, and environments.




































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






