Downloaded 30 times





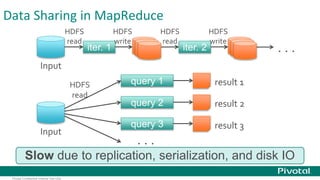
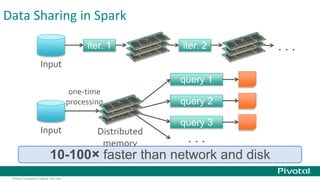







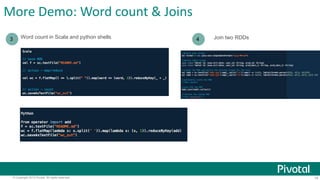




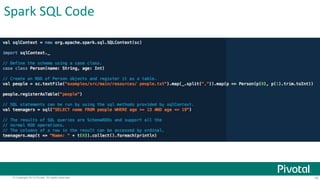

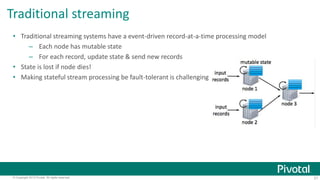
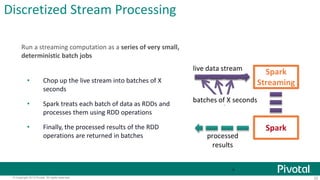
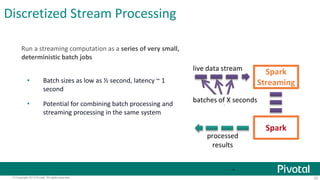













This document provides an overview of Apache Spark, including: - Spark allows for fast iterative processing by keeping data in memory across parallel jobs for faster sharing than MapReduce. - The core of Spark is the resilient distributed dataset (RDD) which allows parallel operations on distributed data. - Spark comes with libraries for SQL queries, streaming, machine learning, and graph processing.































![Apache Spark 101 [in 50 min]](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark101-in50min1-150227110033-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









































