Download to read offline





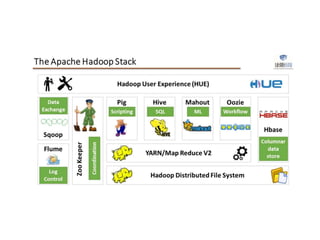


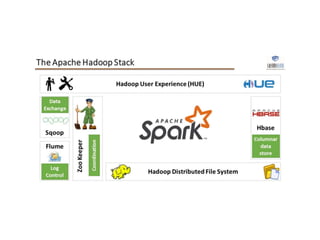



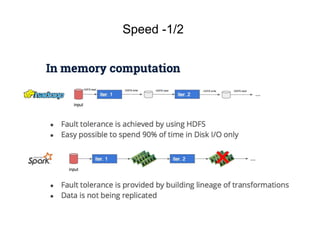
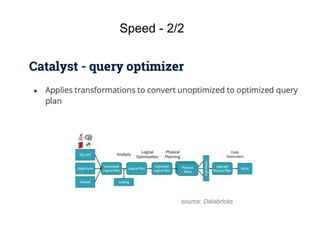


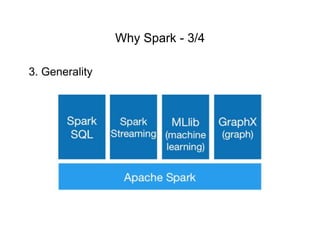









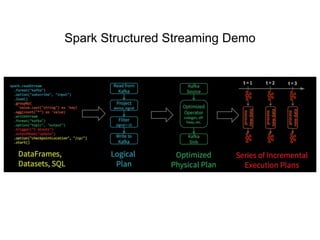




1. Apache Spark is an open source cluster computing framework for large-scale data processing. It is compatible with Hadoop and provides APIs for SQL, streaming, machine learning, and graph processing. 2. Over 3000 companies use Spark, including Microsoft, Uber, Pinterest, and Amazon. It can run on standalone clusters, EC2, YARN, and Mesos. 3. Spark SQL, Streaming, and MLlib allow for SQL queries, streaming analytics, and machine learning at scale using Spark's APIs which are inspired by Python/R data frames and scikit-learn.
























































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
