Downloaded 37 times


![Contents
1. Transformer
2. DETR[1]
3. ViT[2]
[1] Carion et al. End-to-End Object Detection with Transformers. ECCV 2020
[2] Dosovitskiy et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-3-320.jpg)
![Transformer
[1] Vaswani et al. Attention is All You Need. NIPS 2017
[2] Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019
[3] Radford et al. Improving Language Understanding by Generative Pre-Training. Technical Report 2019
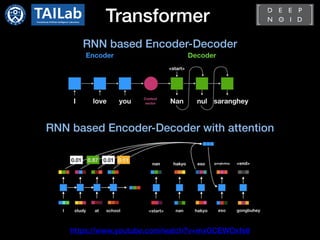
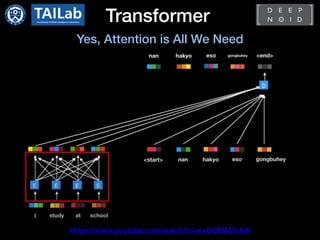
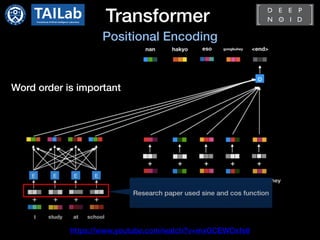
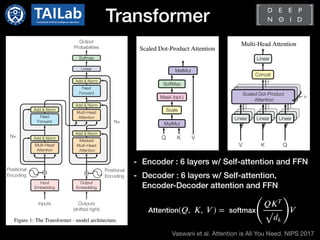
- Transformer[1]
- Standard architecture for NLP tasks
- Only consist of attention modules not
using RNN
- Encoder-decoder
- Requires large scale dataset and high
computational cost
- Pre-training and fine-tuning approach is
dominant
: BERT[2] and GPT[3]](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-4-320.jpg)


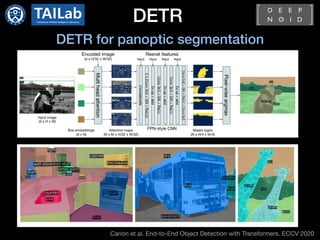


![DETR
[1] Carion et al. End-to-End Object Detection with Transformers. ECCV 2020
[2] Zhu et al. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv:2010.04159
DETR (DEtection TRansformer)[1]
Pros
- Eliminate the need for many hand-crafted components
(e.g., anchor generation, rule-based training target assignment, NMS)
- The first fully end-to-end object detector
- A simple architecture (CNN + Transformer encoder-decoder)
Cons[2]
- Requires long training epochs
- Limited feature spatial resolution
: high resolution leads to unacceptable complexities](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-15-320.jpg)
![Deformable DETR[1]
[1] Zhu et al. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv:2010.04159
[2] Dai et al. Deformable Convolutional Networks. ICCV 2017
- Apply the concept of deformable convolution[2] to mitigate the problems of DETR
- Deformable attention module, which is an efficient attention mechanism in
processing feature maps
- Requires only 50 epochs for training (1/10 of original DETR)
- Achieved S.O.T.A using two-stage variant as R-CNN models](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-16-320.jpg)
![Deformable DETR[1]
[1] Lin et al. Feature Pyramid Networks for Object Detection. CVPR 2017
[2] Dai et al. Deformable Convolutional Networks. ICCV 2017
- Most of modern object detectors follow the shape of FPN[1]
- It was impossible to apply such concept to DETR because
of computational complexity
- Deformable convolution[2] is a powerful and efficient
mechanism to attend to sparse spatial locations
- By apply the idea of deformable convolution, Deformable DETR can benefit from
multi-scale feature maps with relatively small model complexity](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-17-320.jpg)
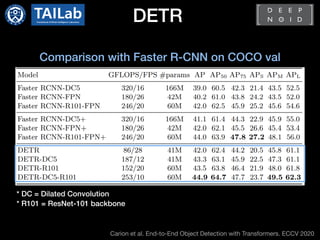
![Deformable DETR[1]
Comparison with Faster R-CNN and DETR on COCO val](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-18-320.jpg)
![Deformable DETR[1]
Comparison with S.O.T.A on COCO test-dev](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-19-320.jpg)
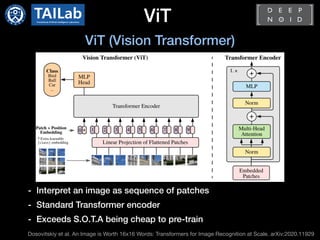
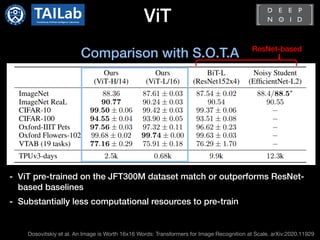
![Conclusion
- Transformer is being actively applied to computer vision
- DETR[1] and ViT[2] showed promising results
- Many challenges still remain
1) a lot of parameters for attention (too heavy…)
2) other computer vision tasks (e.g., segmentation, localization, depth estimation,
image generation, video)
[1] Carion et al. End-to-End Object Detection with Transformers. ECCV 2020
[2] Dosovitskiy et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929](https://image.slidesharecdn.com/transformerincomputervisioncdm-210413065055/85/Transformer-in-Computer-Vision-23-320.jpg)


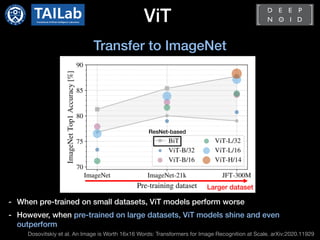
The document discusses the application of transformers to computer vision tasks. It first introduces the standard transformer architecture and its use in natural language processing. It then summarizes recent works on applying transformers to object detection (DETR) and image classification (ViT). DETR proposes an end-to-end object detection method using a CNN-Transformer encoder-decoder architecture. Deformable DETR improves on DETR by incorporating deformable attention mechanisms. ViT represents images as sequences of patches and applies a standard Transformer encoder for image recognition, exceeding state-of-the-art models with less pre-training computation. While promising results have been achieved, challenges remain regarding model parameters and expanding transformer applications to other computer vision tasks.








![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 23] Ivan Biliskov - Seeing Through the Lens of Transformers: A Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/ivanbiliskov-cvvisiontransformers-231129094209-d32f1292-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)
![Review: Incremental Few-shot Instance Segmentation [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/incrementalfew-shotinstancesegmentation-reviewcdm-210619132753-thumbnail.jpg?width=640&height=640&fit=bounds)


![YolactEdge Review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/yolactedgereviewcdm-210109174625-thumbnail.jpg?width=640&height=640&fit=bounds)



![Review : Multi-Domain Image Completion for Random Missing Input Data [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/multi-domainimagecompletionforrandommissinginputdata-reviewcdm-200821161134-thumbnail.jpg?width=640&height=640&fit=bounds)


![Pyradiomics Customization [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/pyradiomicscustomization20200708cdm-200715042837-thumbnail.jpg?width=640&height=640&fit=bounds)
![Seeing What a GAN Cannot Generate [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/seeingwhatagancannotgeneratecdm-200712084415-thumbnail.jpg?width=640&height=640&fit=bounds)
![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)
![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)

![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)
![Augmix review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/augmixreviewcdm-200315063029-thumbnail.jpg?width=640&height=640&fit=bounds)

![ICCV 2019 REVIEW [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/iccv2019cdm-191119024322-thumbnail.jpg?width=640&height=640&fit=bounds)



















