Download to read offline

![Introduction
He et al. Rethinking ImageNet Pre-training. ICCV 2019
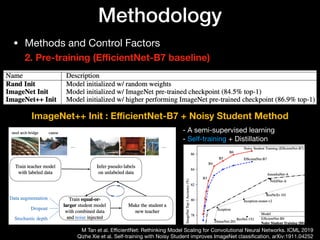
• Pre-training
- a dominant paradigm in computer vision (ex. ImageNet pre-training)
- However, ImageNet pre-training does not improve accuracy on COCO
[Kaiming He, ICCV 2019]](https://image.slidesharecdn.com/rethinkingpre-trainingandself-training-reviewcdm-200809112201/85/Review-Rethinking-Pre-training-and-Self-training-2-320.jpg)
![Introduction
He et al. Rethinking ImageNet Pre-training. ICCV 2019
• Pre-training
- a dominant paradigm in computer vision (ex. ImageNet pre-training)
- However, ImageNet pre-training does not improve accuracy on COCO
[Kaiming He, ICCV 2019]
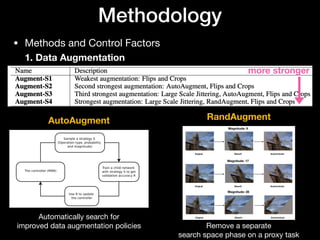
• Self-training
- Steps (ex. Use ImageNet to help COCO object detection)
1) Discard the labels on ImageNet
2) Train an object detection on COCO, and use it to generate pseudo labels
on ImageNet
3) A new model is trained on the combined pseudo-labeled ImageNet and
labeled COCO data](https://image.slidesharecdn.com/rethinkingpre-trainingandself-training-reviewcdm-200809112201/85/Review-Rethinking-Pre-training-and-Self-training-3-320.jpg)





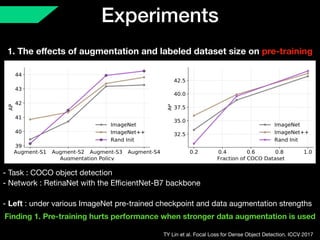
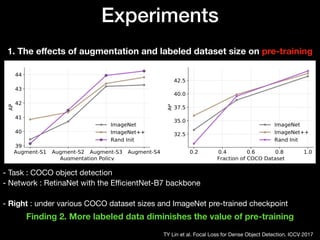

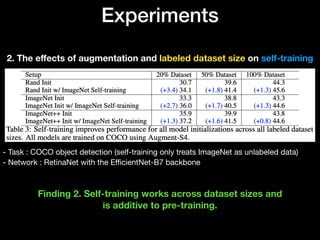













The document discusses the limitations of traditional pre-training methods in computer vision, particularly in relation to the COCO dataset, and highlights the advantages of self-training approaches. It presents findings that self-training improves performance across various conditions, especially when combined with strong data augmentation and larger labeled datasets. Overall, self-training is deemed more adaptable and beneficial compared to pre-training, though it requires more computational resources.
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]医用画像解析におけるセグメンテーション](https://cdn.slidesharecdn.com/ss_thumbnails/20190301fujino4-190322072121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]物理学による帰納バイアスを組み込んだダイナミクスモデル作成に関する論文まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/physicsinductivebias1-200703042625-thumbnail.jpg?width=640&height=640&fit=bounds)

![[論文紹介] DPSNet: End-to-end Deep Plane Sweep Stereo](https://cdn.slidesharecdn.com/ss_thumbnails/20190212dpsnet-190830151623-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


























![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)
![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)


![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)

![Review: Incremental Few-shot Instance Segmentation [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/incrementalfew-shotinstancesegmentation-reviewcdm-210619132753-thumbnail.jpg?width=640&height=640&fit=bounds)
![Pyradiomics Customization [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/pyradiomicscustomization20200708cdm-200715042837-thumbnail.jpg?width=640&height=640&fit=bounds)
![Review : Multi-Domain Image Completion for Random Missing Input Data [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/multi-domainimagecompletionforrandommissinginputdata-reviewcdm-200821161134-thumbnail.jpg?width=640&height=640&fit=bounds)

![Augmix review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/augmixreviewcdm-200315063029-thumbnail.jpg?width=640&height=640&fit=bounds)
![YolactEdge Review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/yolactedgereviewcdm-210109174625-thumbnail.jpg?width=640&height=640&fit=bounds)


![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)
![Seeing What a GAN Cannot Generate [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/seeingwhatagancannotgeneratecdm-200712084415-thumbnail.jpg?width=640&height=640&fit=bounds)



















