Download as PDF, PPTX







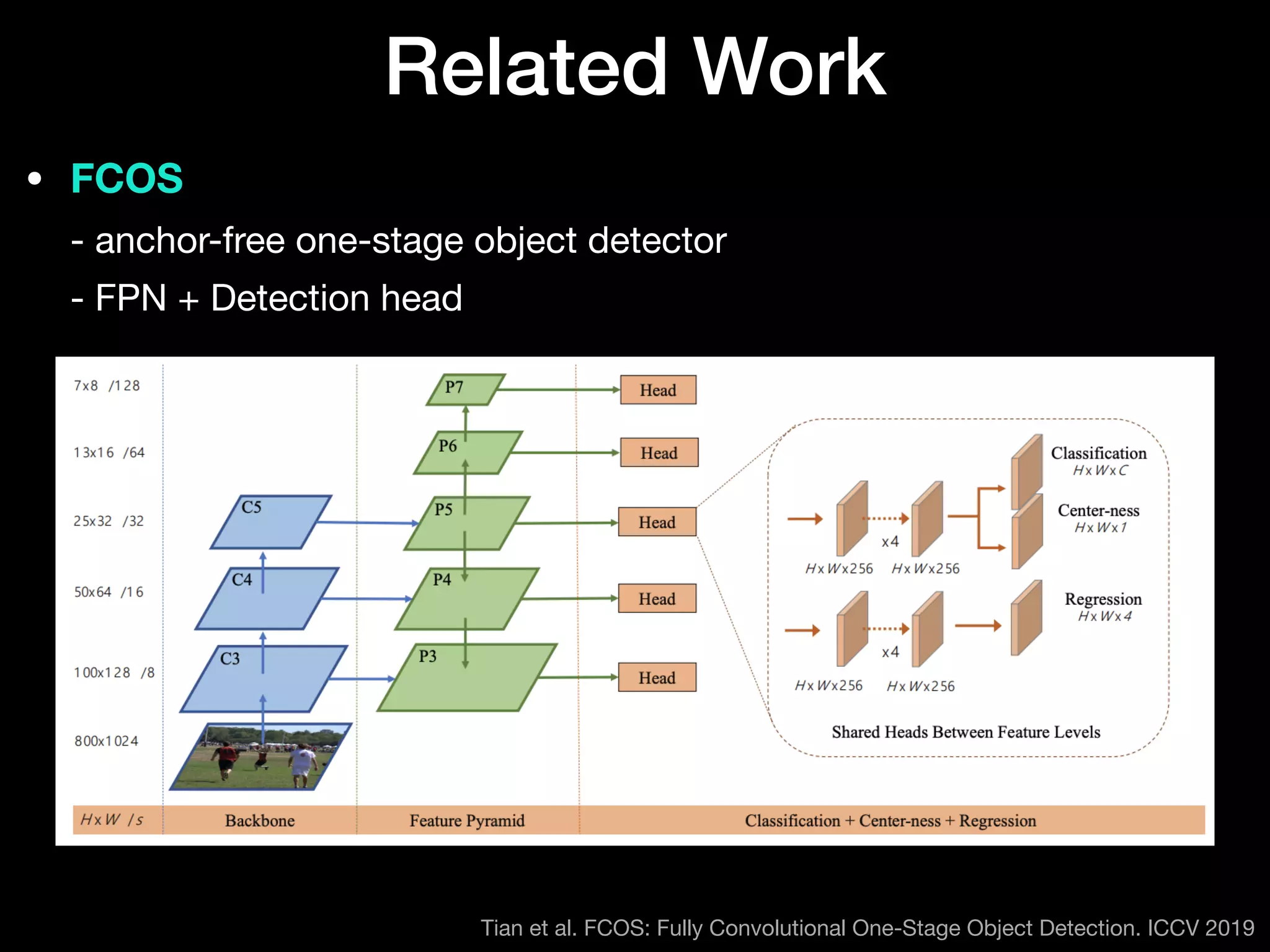
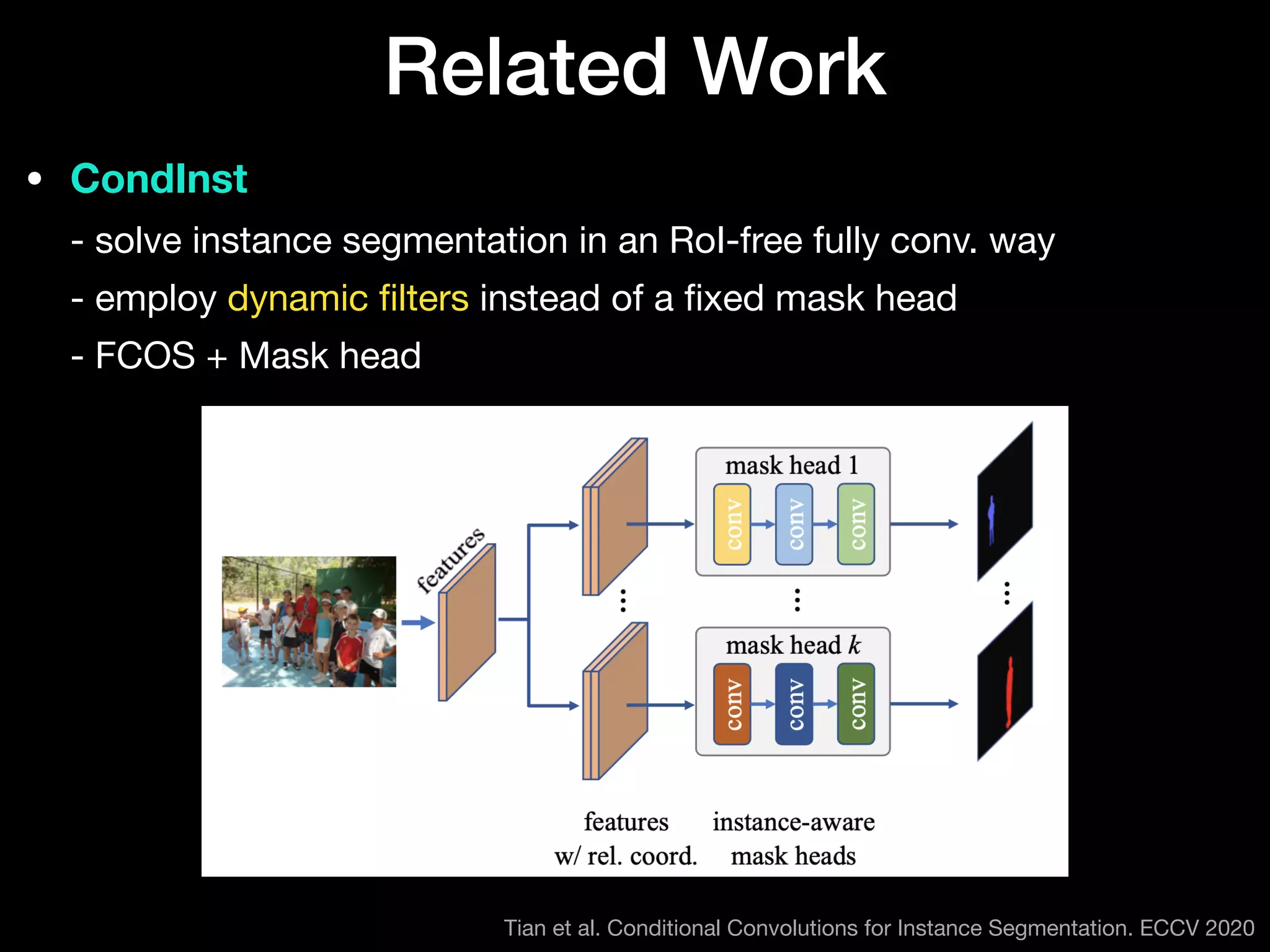
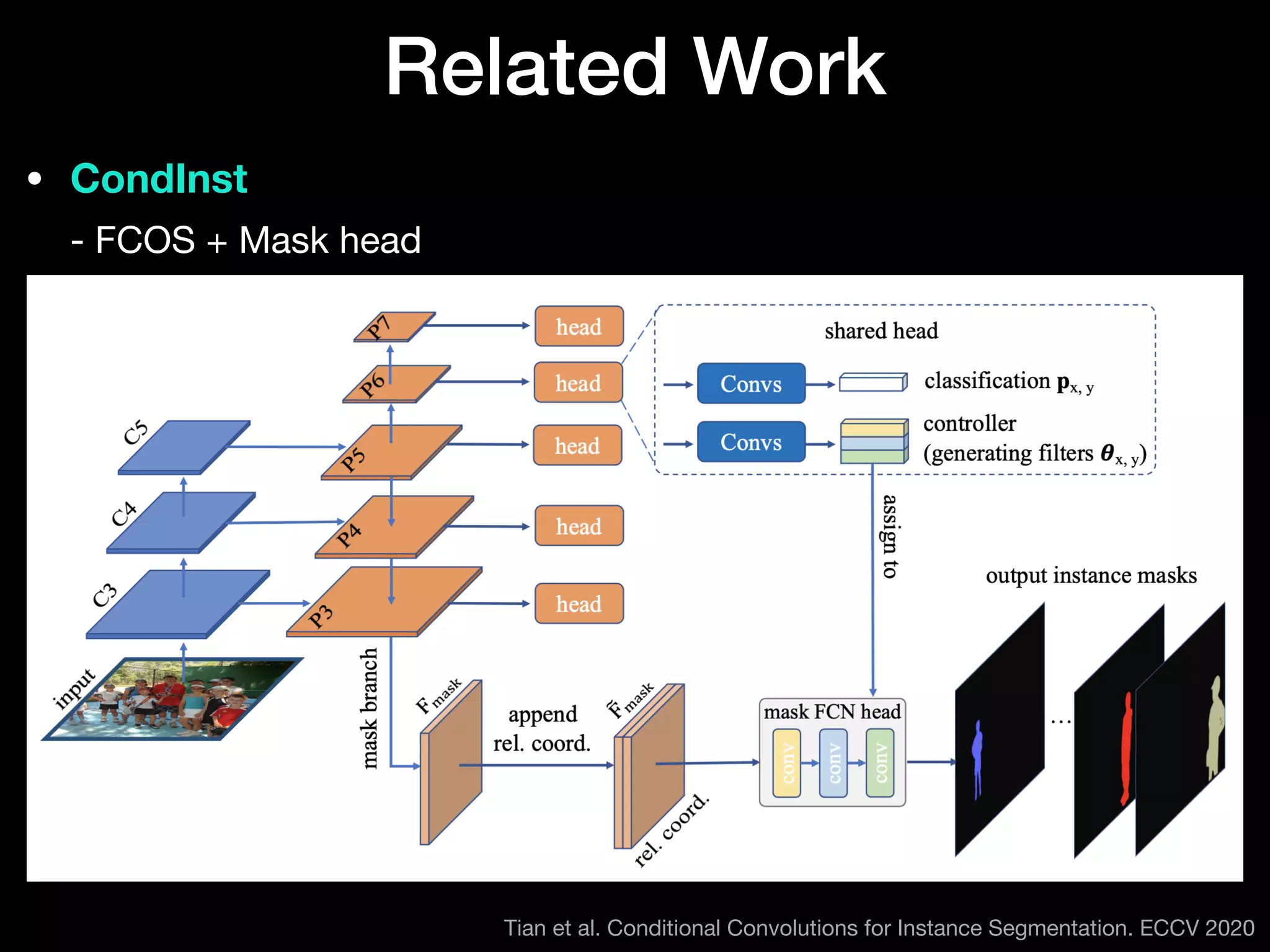
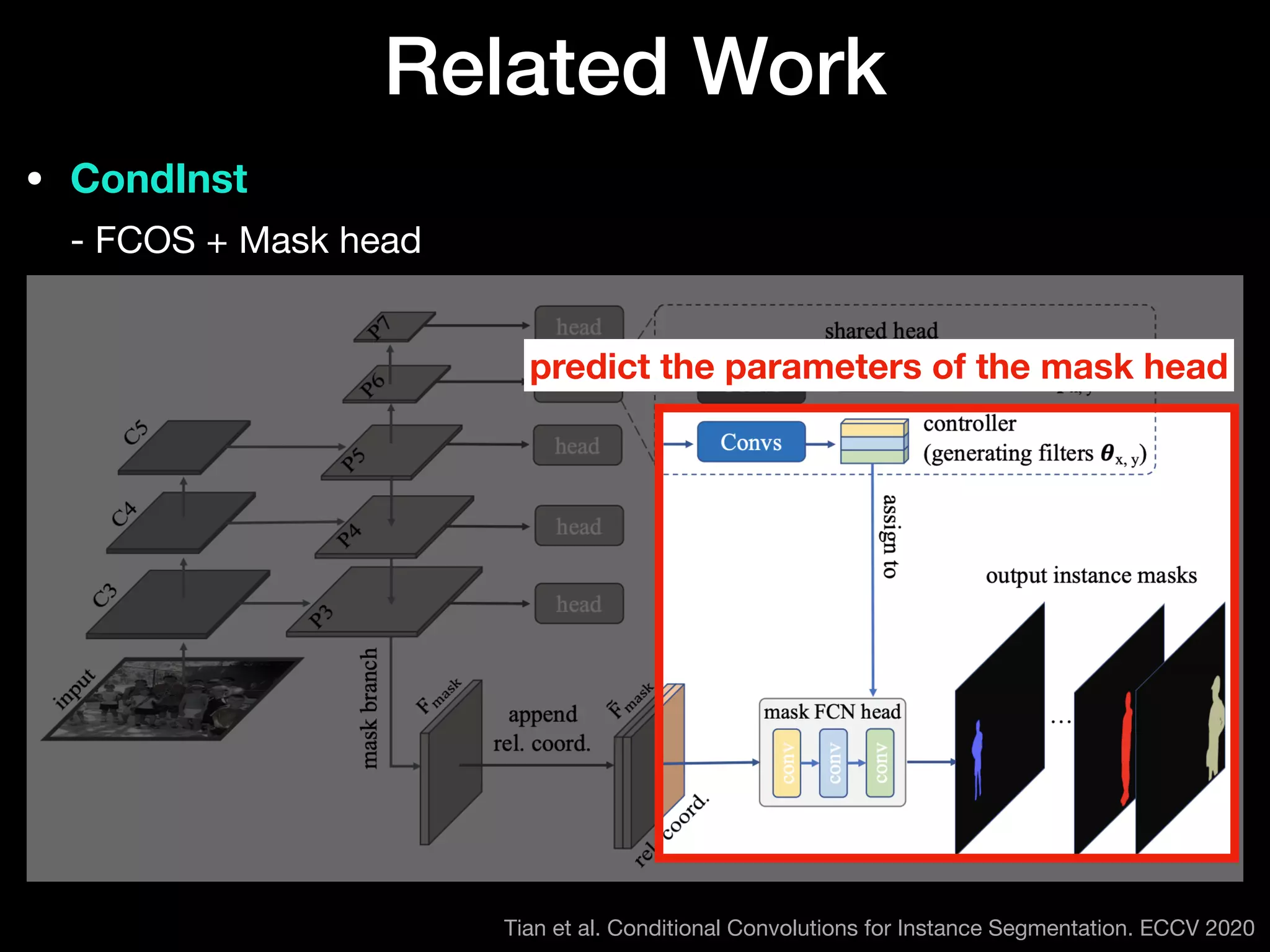
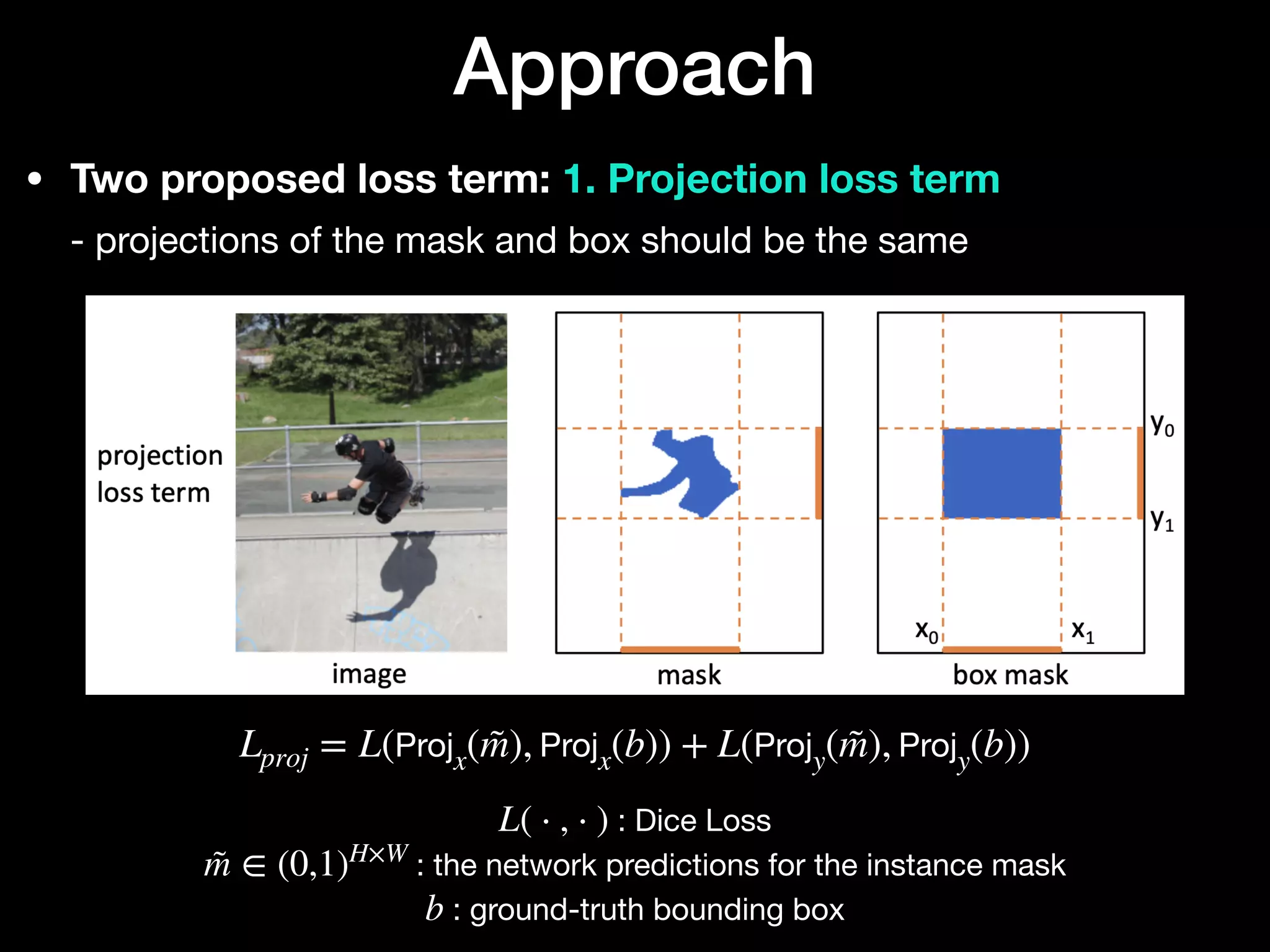
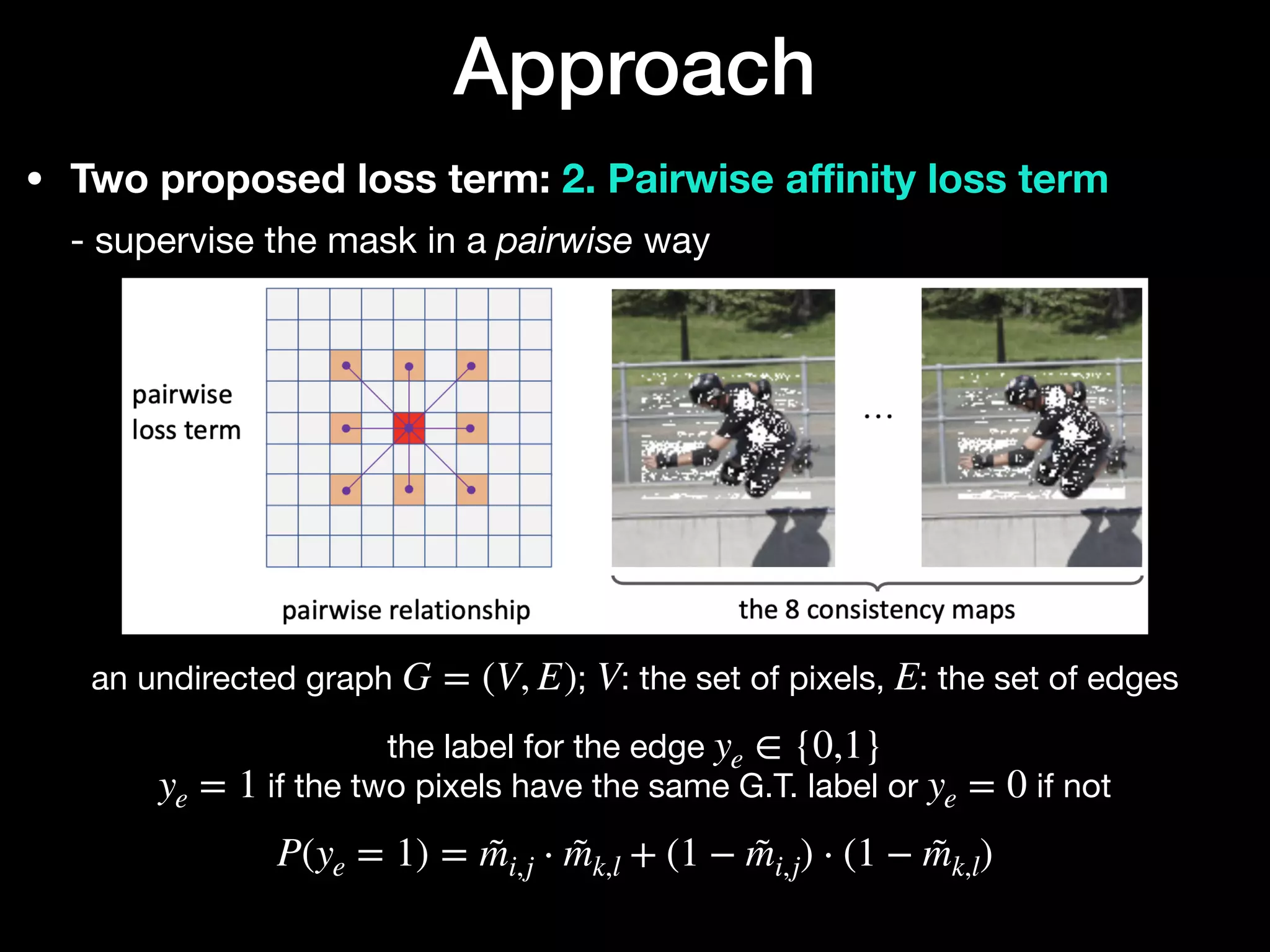






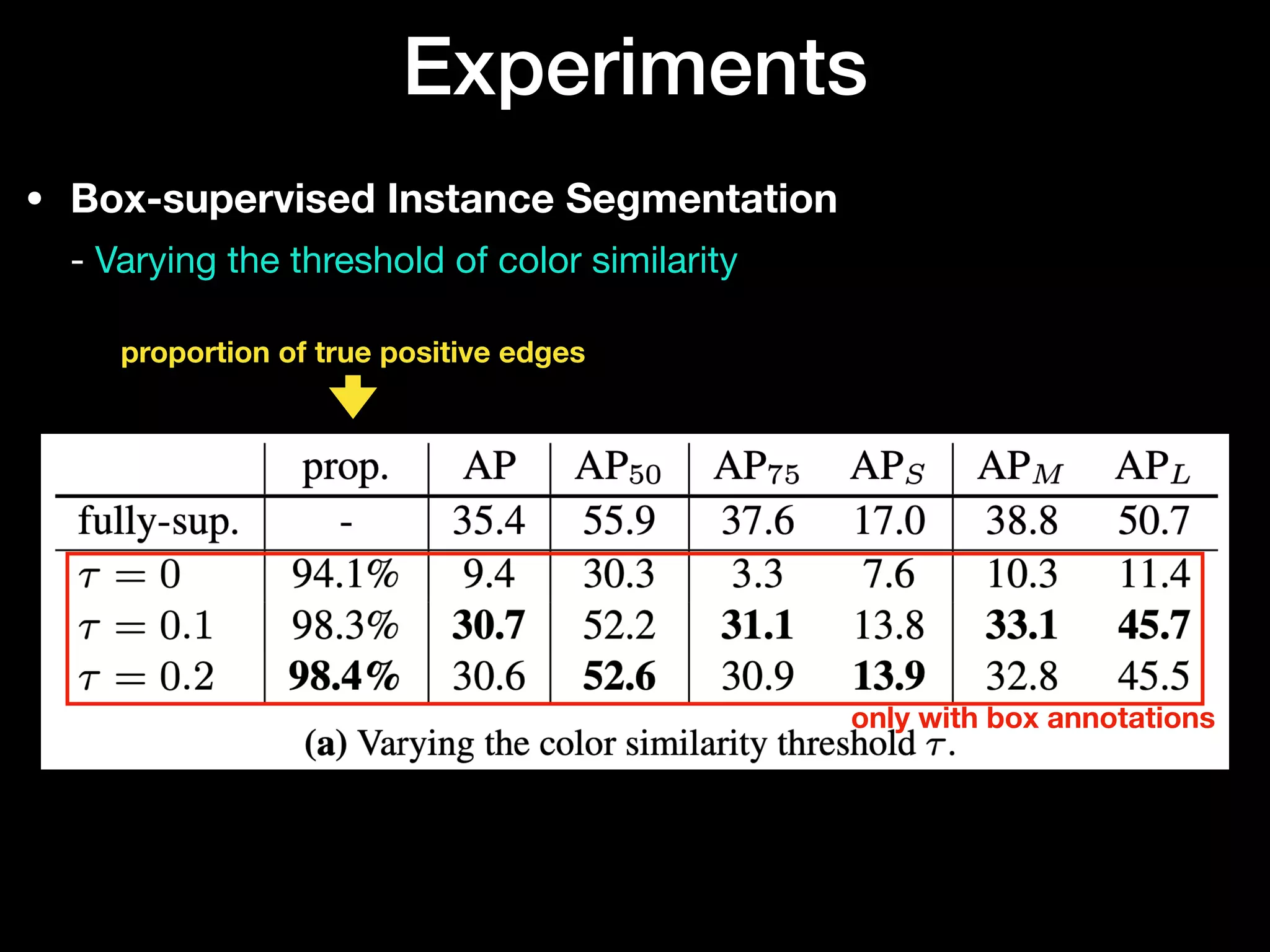
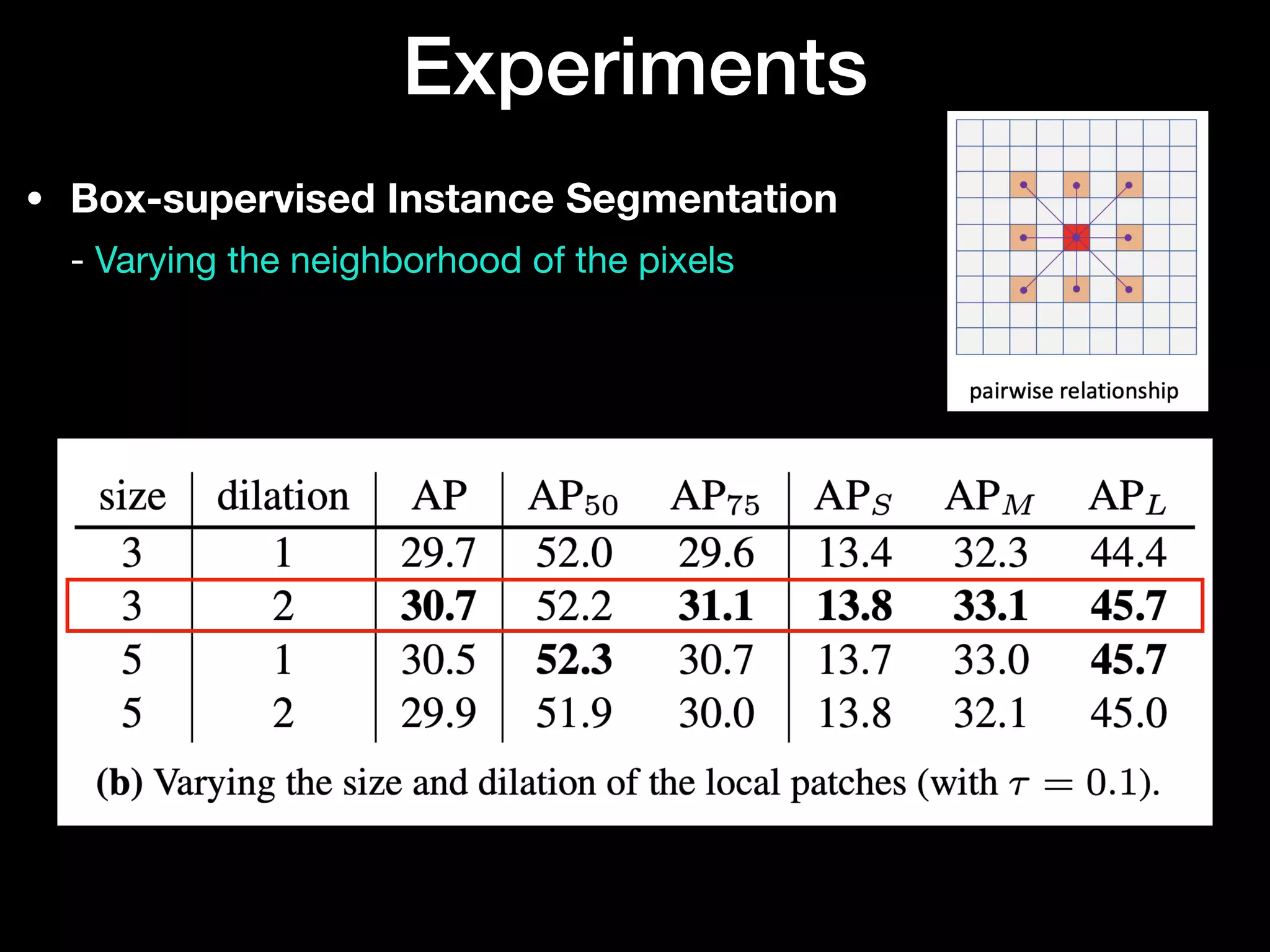
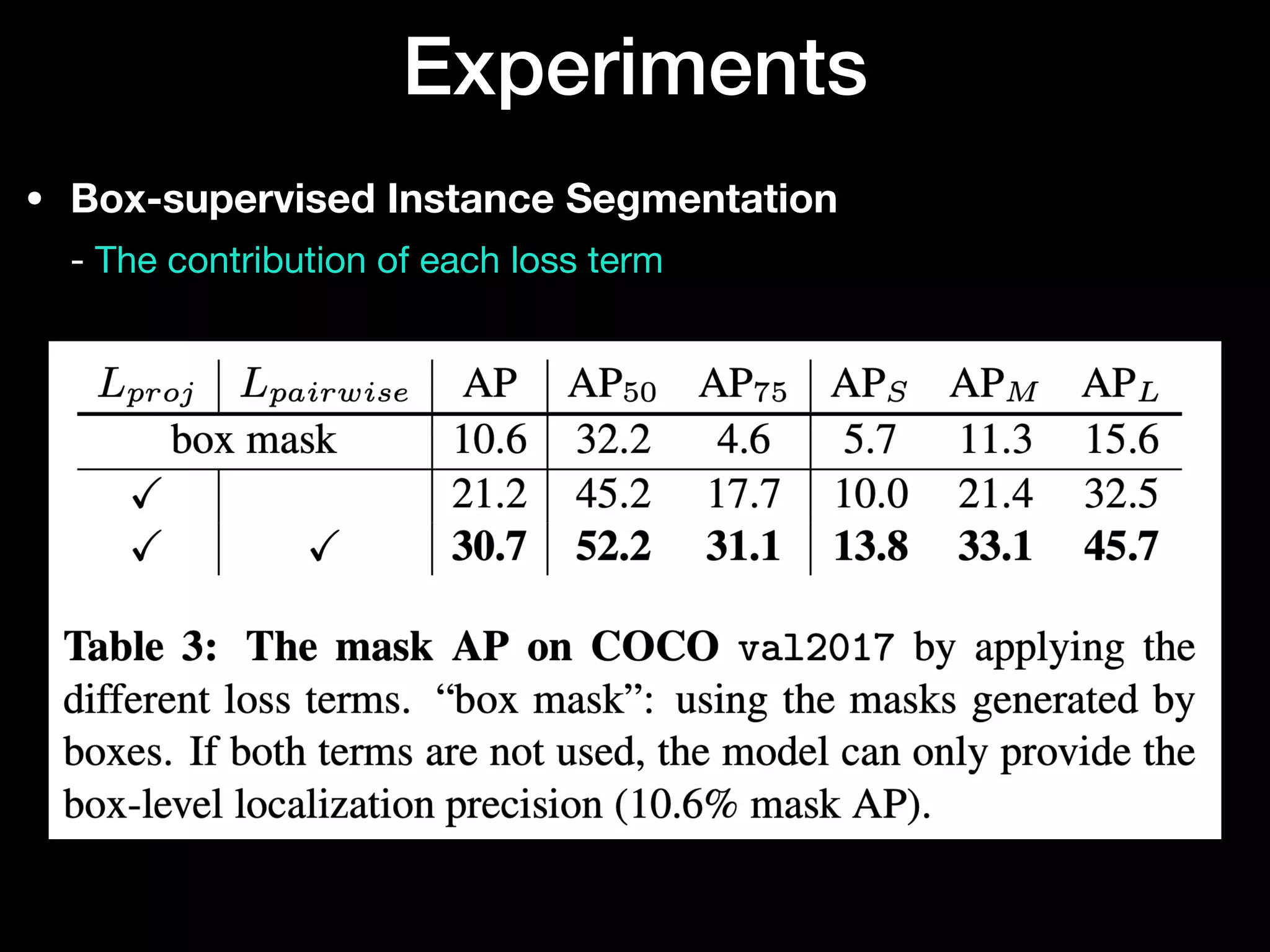

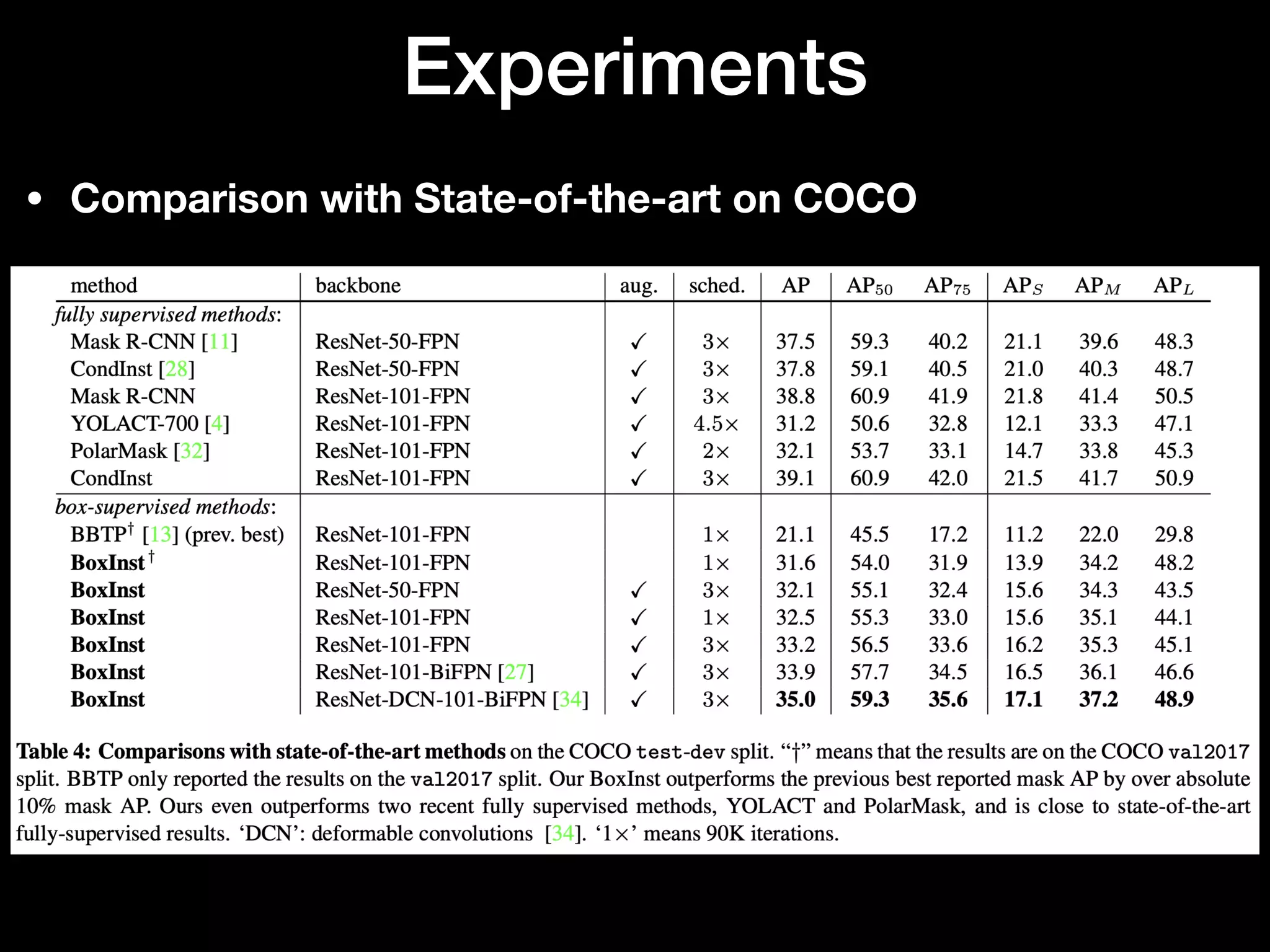
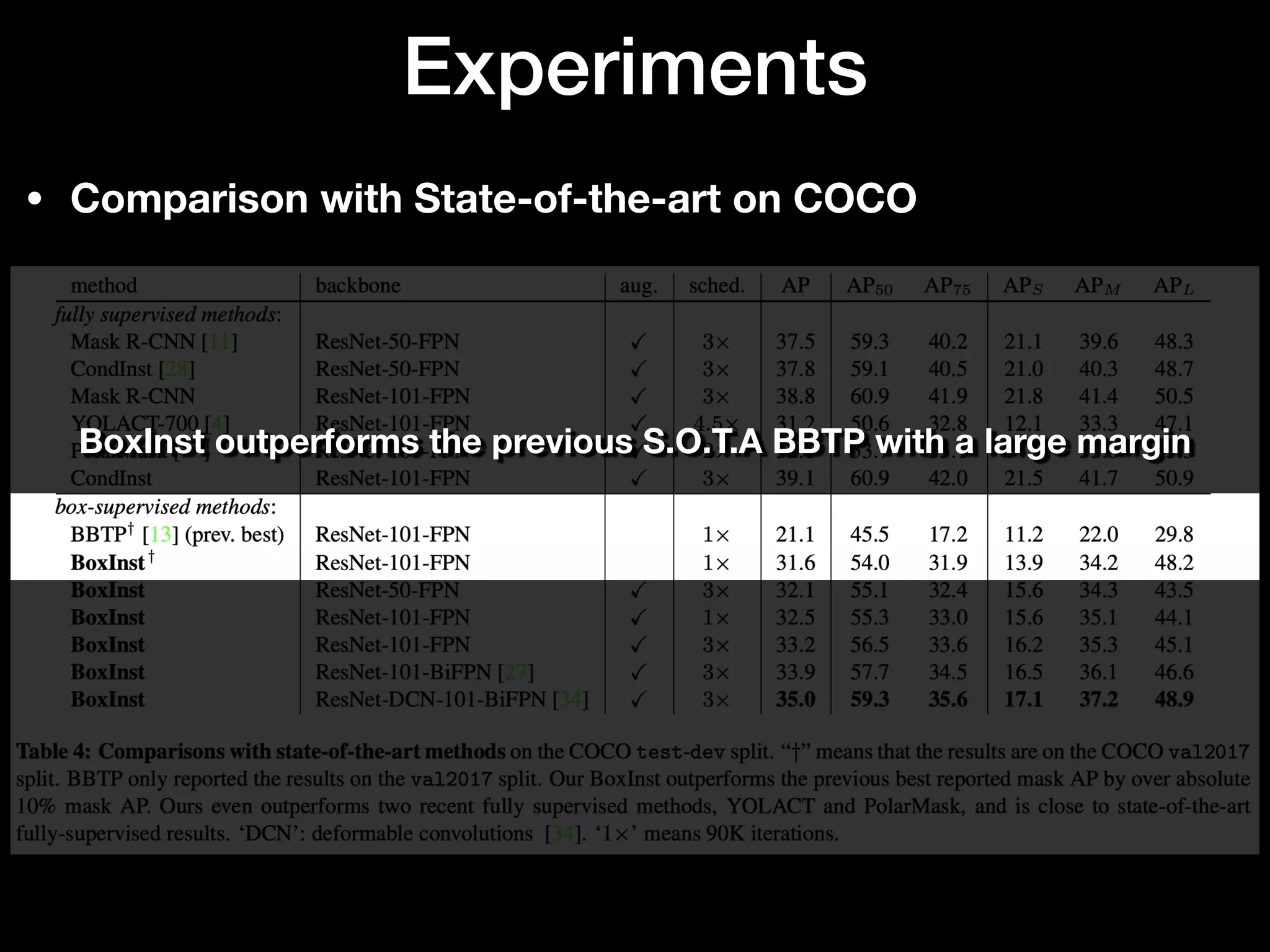
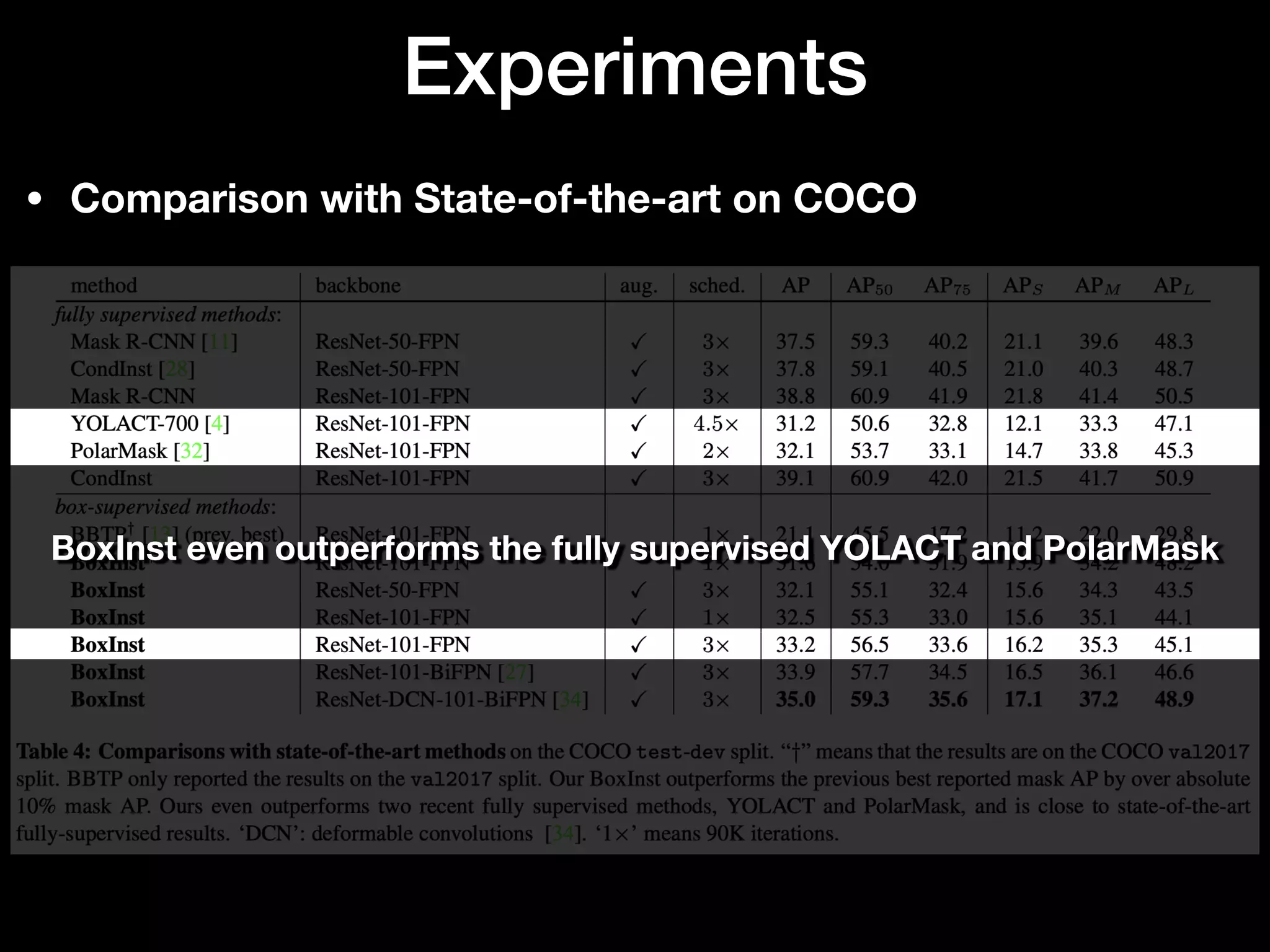
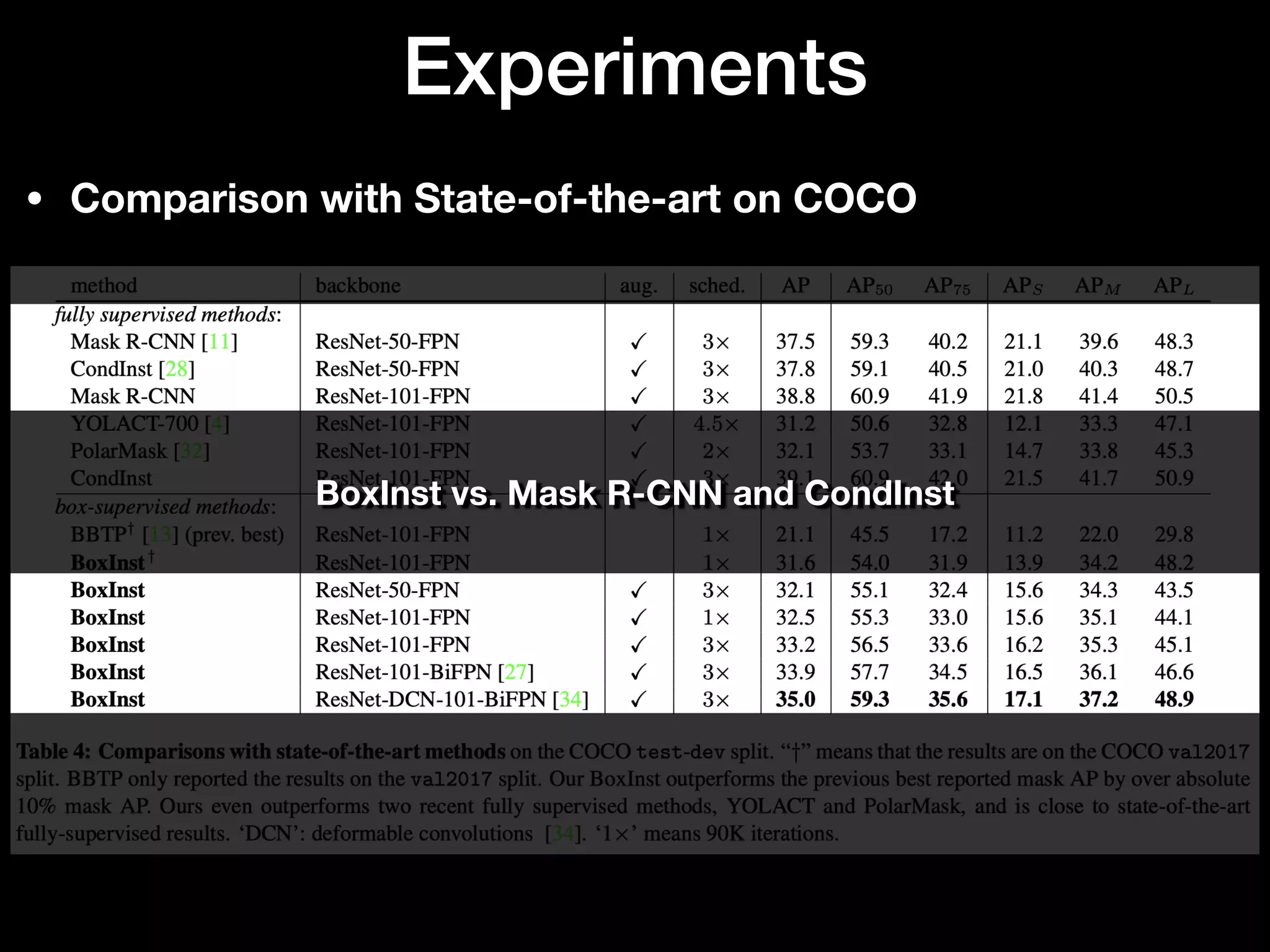
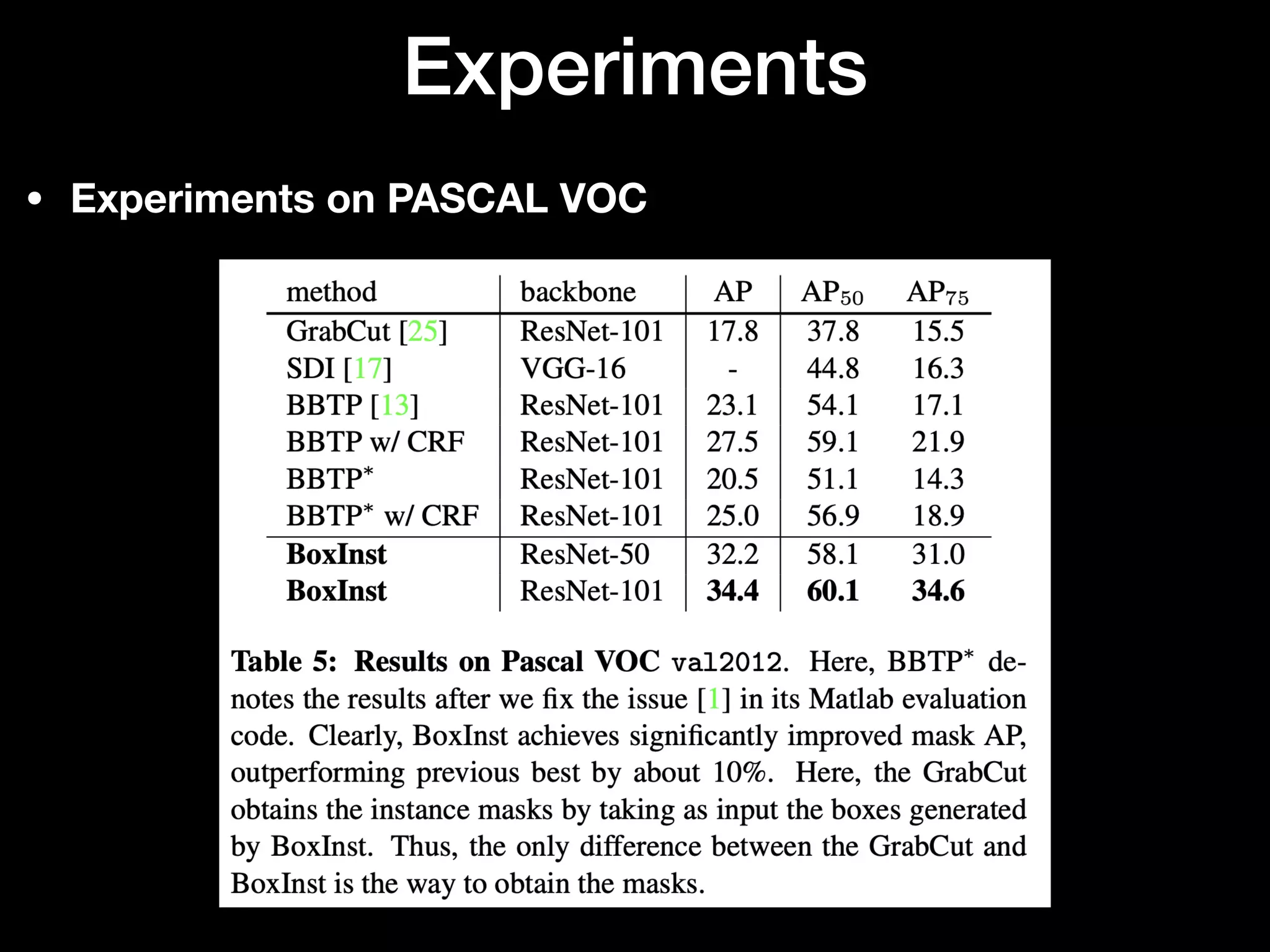
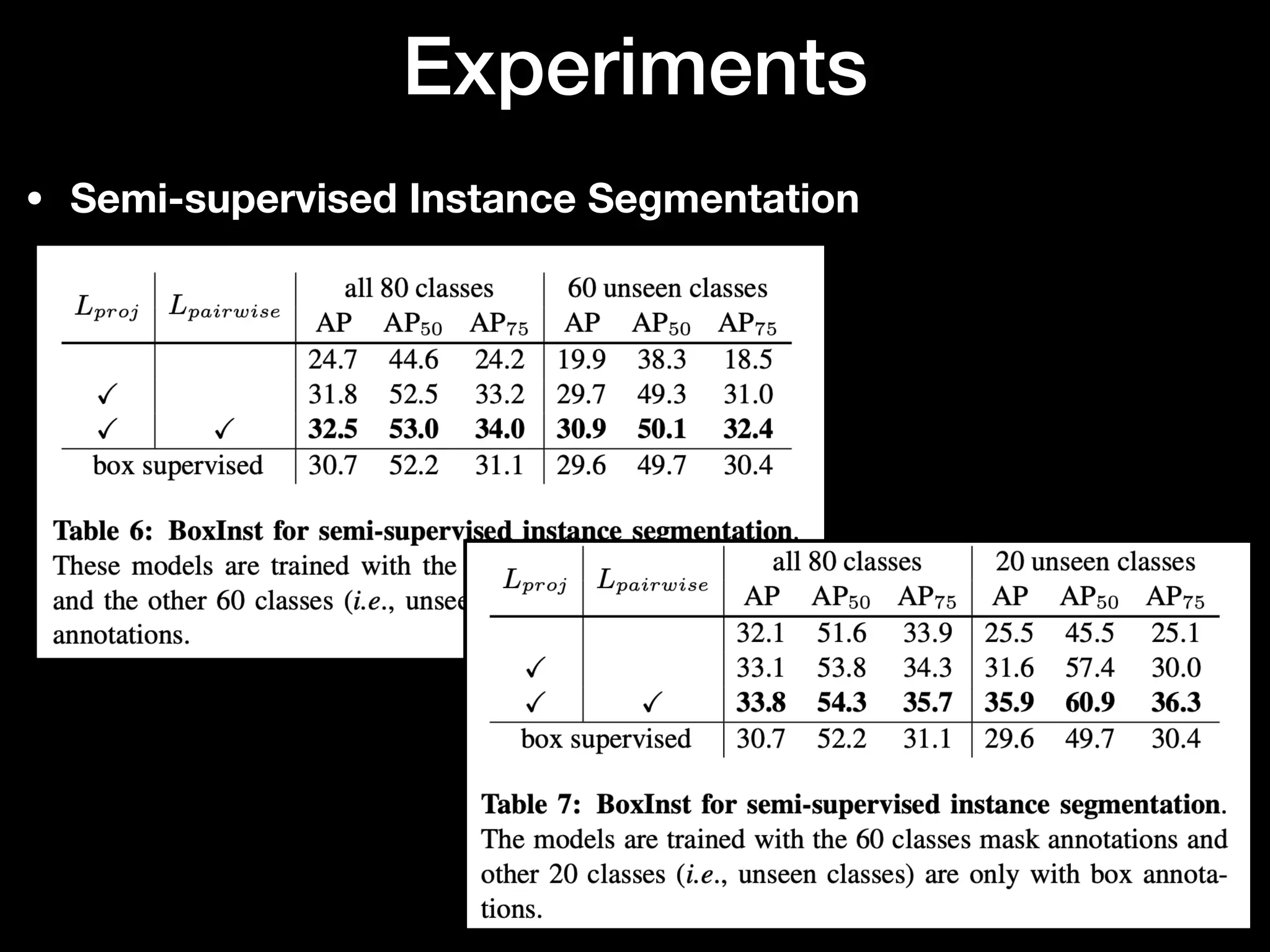



The document discusses 'BoxInst', a high-performance instance segmentation model that uses only bounding box annotations for training, achieving a significant increase in average precision from 21.1% to 31.6% on the COCO benchmark. It introduces two proposed loss terms, projection loss and pairwise affinity loss, which work together to facilitate mask learning without the need for pixel-level mask annotations. The results indicate that BoxInst outperforms previous state-of-the-art models, including both weakly and fully supervised methods.



































![[NS][Lab_Seminar_241125]Affinity Attention Graph Neural Network for Weakly Su...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241125a2gnn-241125095443-ccec5e07-thumbnail.jpg?width=640&height=640&fit=bounds)














![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)
![Review: Incremental Few-shot Instance Segmentation [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/incrementalfew-shotinstancesegmentation-reviewcdm-210619132753-thumbnail.jpg?width=640&height=640&fit=bounds)
![YolactEdge Review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/yolactedgereviewcdm-210109174625-thumbnail.jpg?width=640&height=640&fit=bounds)

![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)
![Pyradiomics Customization [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/pyradiomicscustomization20200708cdm-200715042837-thumbnail.jpg?width=640&height=640&fit=bounds)
![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)
![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)
![Review : Multi-Domain Image Completion for Random Missing Input Data [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/multi-domainimagecompletionforrandommissinginputdata-reviewcdm-200821161134-thumbnail.jpg?width=640&height=640&fit=bounds)
![Augmix review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/augmixreviewcdm-200315063029-thumbnail.jpg?width=640&height=640&fit=bounds)




![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)


![Seeing What a GAN Cannot Generate [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/seeingwhatagancannotgeneratecdm-200712084415-thumbnail.jpg?width=640&height=640&fit=bounds)



















