Download as PDF, PPTX


![Introduction
Transfer Learning
• The powerful pre-trained model
1) excellent transferability
2) generalization capacity
• Zhou et al.
1) the benefit of SSL are smaller when trained from a pre-trained model
2) combining SSL and transfer learning can solve the domain gap
[Zhou et al, When Semi-Supervised Learning Meets Transfer Learning: Training Strategies, Models and Datasets, arXiv 2018]](https://image.slidesharecdn.com/adaptiveconsistencyregularizationforsemi-supervisedtransferlearningreviewcdm-210307084235/85/Review-Adaptive-Consistency-Regularization-for-Semi-Supervised-Transfer-Learning-3-320.jpg)




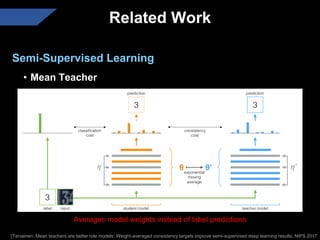

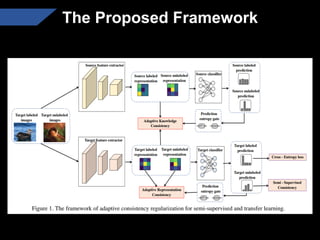
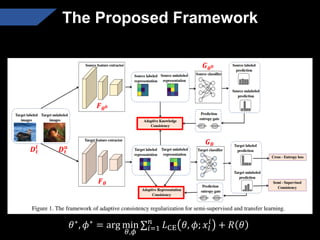
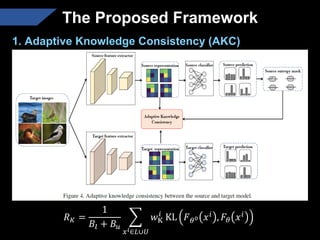

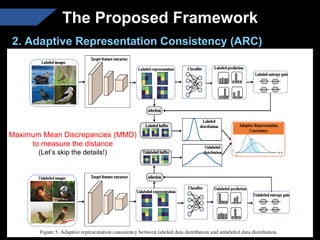
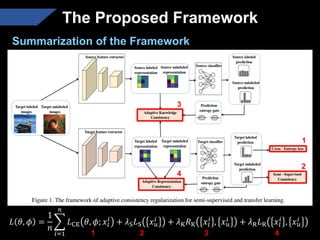



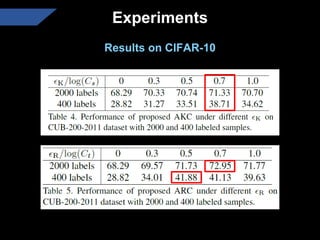
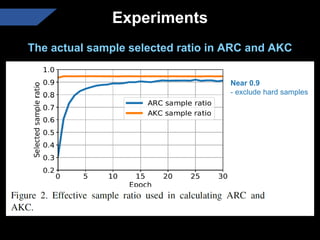




The document presents a semi-supervised transfer learning framework that enhances consistency regularization by incorporating adaptive knowledge consistency (AKC) and adaptive representation consistency (ARC). These methods utilize labeled and unlabeled data effectively, demonstrating competitive results against state-of-the-art semi-supervised learning techniques across various benchmarks. The proposed framework aims to improve transfer learning by addressing the domain gap and optimizing representation learning.



![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)



![Review: Incremental Few-shot Instance Segmentation [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/incrementalfew-shotinstancesegmentation-reviewcdm-210619132753-thumbnail.jpg?width=640&height=640&fit=bounds)

![Review : Multi-Domain Image Completion for Random Missing Input Data [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/multi-domainimagecompletionforrandommissinginputdata-reviewcdm-200821161134-thumbnail.jpg?width=640&height=640&fit=bounds)


![[poster] A Compare-Aggregate Model with Latent Clustering for Answer Selection](https://cdn.slidesharecdn.com/ss_thumbnails/cikm-19-postersyoon-191106033221-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Introduction] Neural Network-Based Abstract Generation for Opinions and Argu...](https://cdn.slidesharecdn.com/ss_thumbnails/introductionpaper-160623020641-thumbnail.jpg?width=640&height=640&fit=bounds)


![[EMBC 2021] Hierarchical Consistency Regularized Mean Teacher for Semi-superv...](https://cdn.slidesharecdn.com/ss_thumbnails/embc211049-copy-220821155725-f6b849d6-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)


![YolactEdge Review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/yolactedgereviewcdm-210109174625-thumbnail.jpg?width=640&height=640&fit=bounds)

![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)


![Pyradiomics Customization [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/pyradiomicscustomization20200708cdm-200715042837-thumbnail.jpg?width=640&height=640&fit=bounds)
![Seeing What a GAN Cannot Generate [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/seeingwhatagancannotgeneratecdm-200712084415-thumbnail.jpg?width=640&height=640&fit=bounds)
![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)
![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)
![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)
![Augmix review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/augmixreviewcdm-200315063029-thumbnail.jpg?width=640&height=640&fit=bounds)

![ICCV 2019 REVIEW [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/iccv2019cdm-191119024322-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Review] High-performance medicine: the convergence of human and artificial i...](https://cdn.slidesharecdn.com/ss_thumbnails/reviewhigh-performancemedicine-190728142338-thumbnail.jpg?width=640&height=640&fit=bounds)



















