Download to read offline



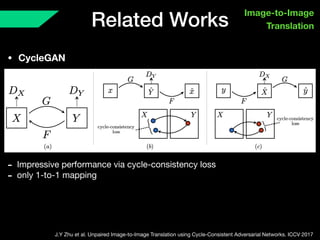

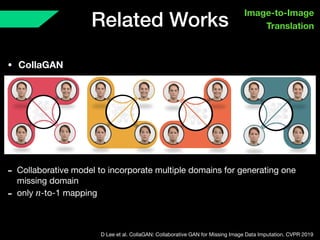

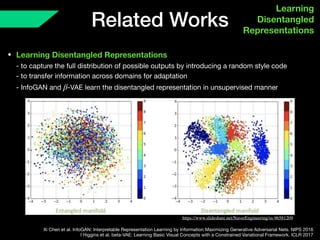
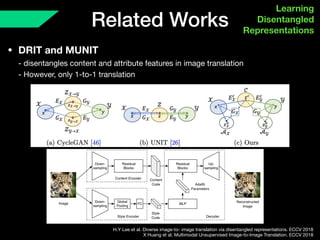
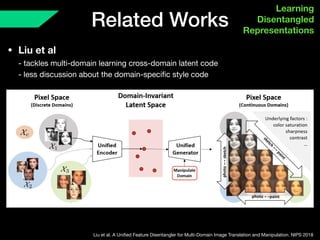
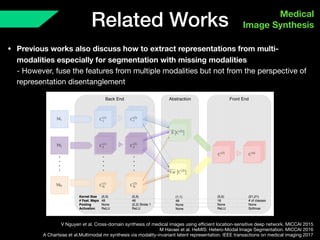


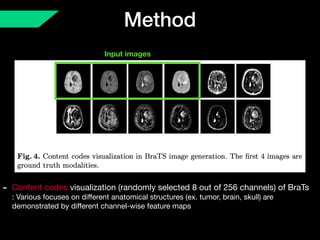




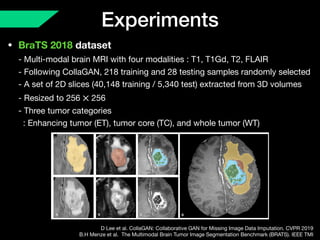





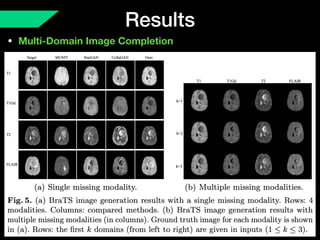



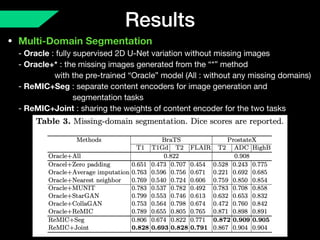




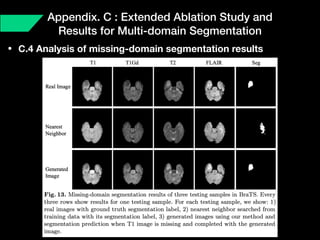


The document presents a framework named REMIC for multi-domain image completion, addressing challenges when certain image domains are missing. It integrates shared content encoding and domain-specific style encoding to complete missing information effectively across different datasets, demonstrating significant performance improvements. The framework is applicable to both medical and natural images and is evaluated on various datasets with detailed results compared to existing models.



![Review: Incremental Few-shot Instance Segmentation [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/incrementalfew-shotinstancesegmentation-reviewcdm-210619132753-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)


![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)

![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)








![[MICCAI 2021] MT-UDA: Towards unsupervised cross-modality medical image segme...](https://cdn.slidesharecdn.com/ss_thumbnails/mt-udamiccai2021-220901163232-97bf56d1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[MICCAI 2021 - Poster] MT-UDA: Towards unsupervised cross-modality medical im...](https://cdn.slidesharecdn.com/ss_thumbnails/poster678-220821153313-833a0777-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IAIM 2023 - Poster] Label-efficient Generalizable Deep Learning for Medical...](https://cdn.slidesharecdn.com/ss_thumbnails/posteriaim-230807050327-c7b3356b-thumbnail.jpg?width=640&height=640&fit=bounds)












![YolactEdge Review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/yolactedgereviewcdm-210109174625-thumbnail.jpg?width=640&height=640&fit=bounds)

![Pyradiomics Customization [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/pyradiomicscustomization20200708cdm-200715042837-thumbnail.jpg?width=640&height=640&fit=bounds)
![Seeing What a GAN Cannot Generate [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/seeingwhatagancannotgeneratecdm-200712084415-thumbnail.jpg?width=640&height=640&fit=bounds)
![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)
![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)
![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)
![Augmix review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/augmixreviewcdm-200315063029-thumbnail.jpg?width=640&height=640&fit=bounds)

![ICCV 2019 REVIEW [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/iccv2019cdm-191119024322-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Review] High-performance medicine: the convergence of human and artificial i...](https://cdn.slidesharecdn.com/ss_thumbnails/reviewhigh-performancemedicine-190728142338-thumbnail.jpg?width=640&height=640&fit=bounds)



















