Downloaded 100 times




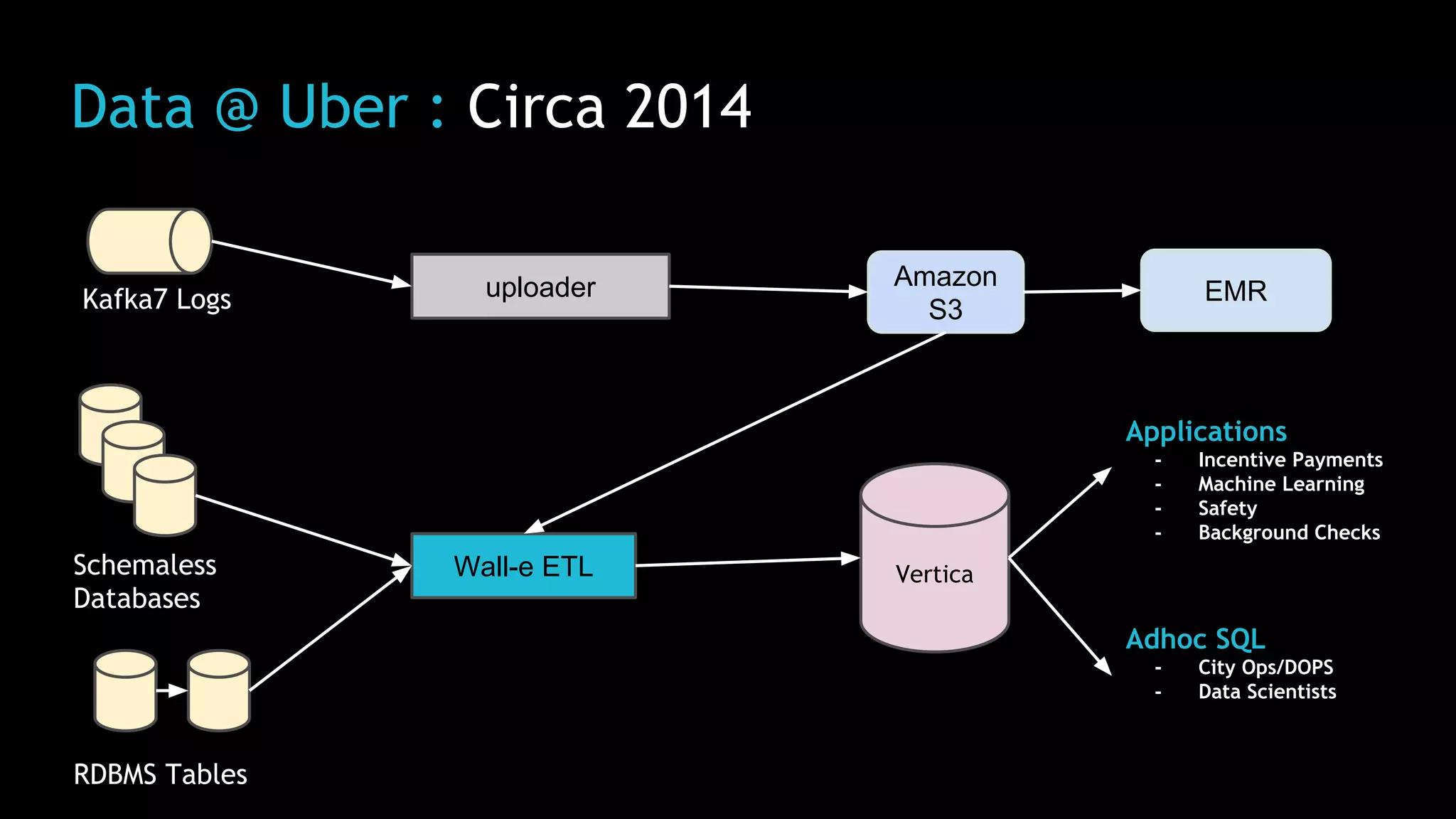


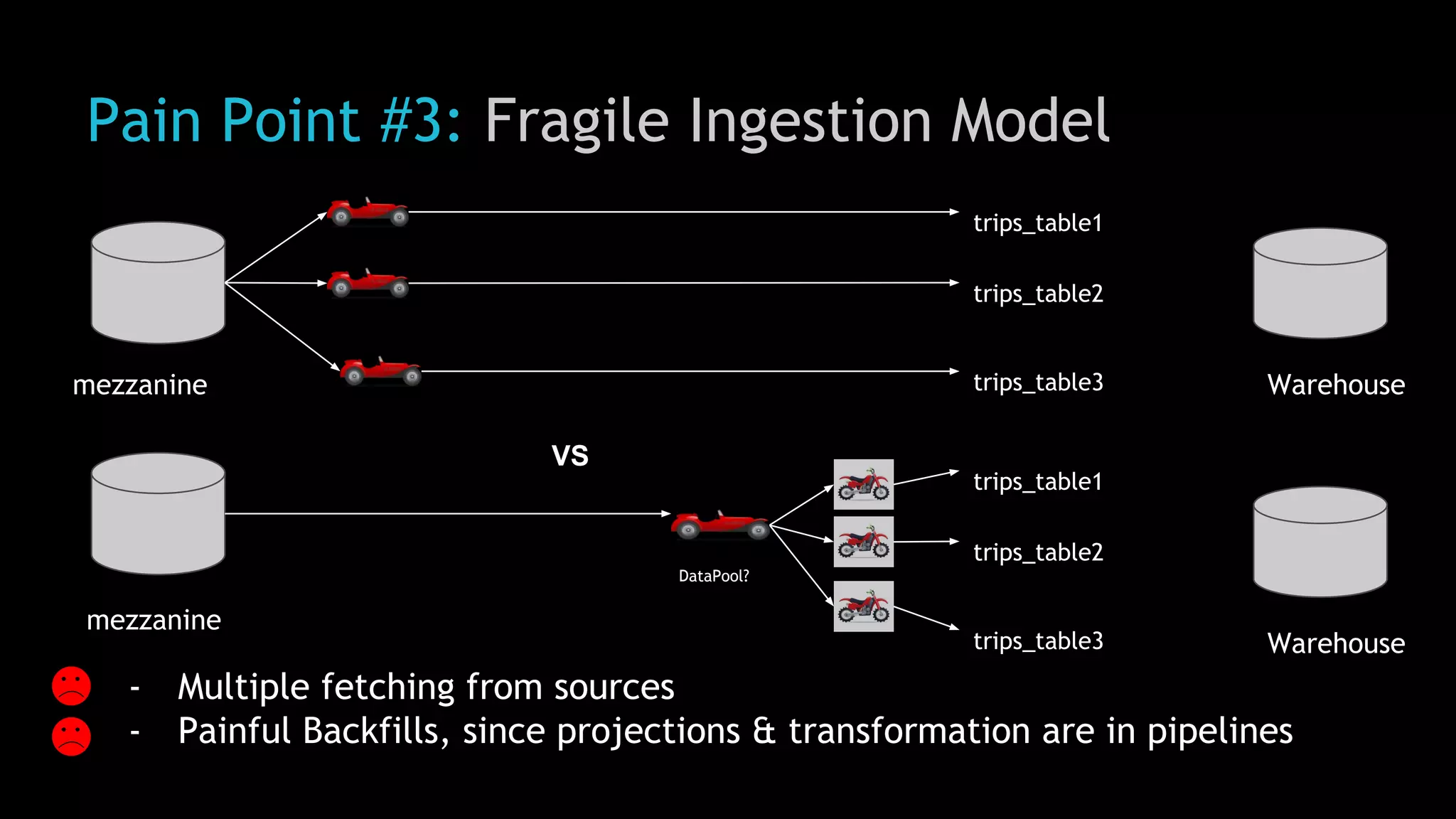



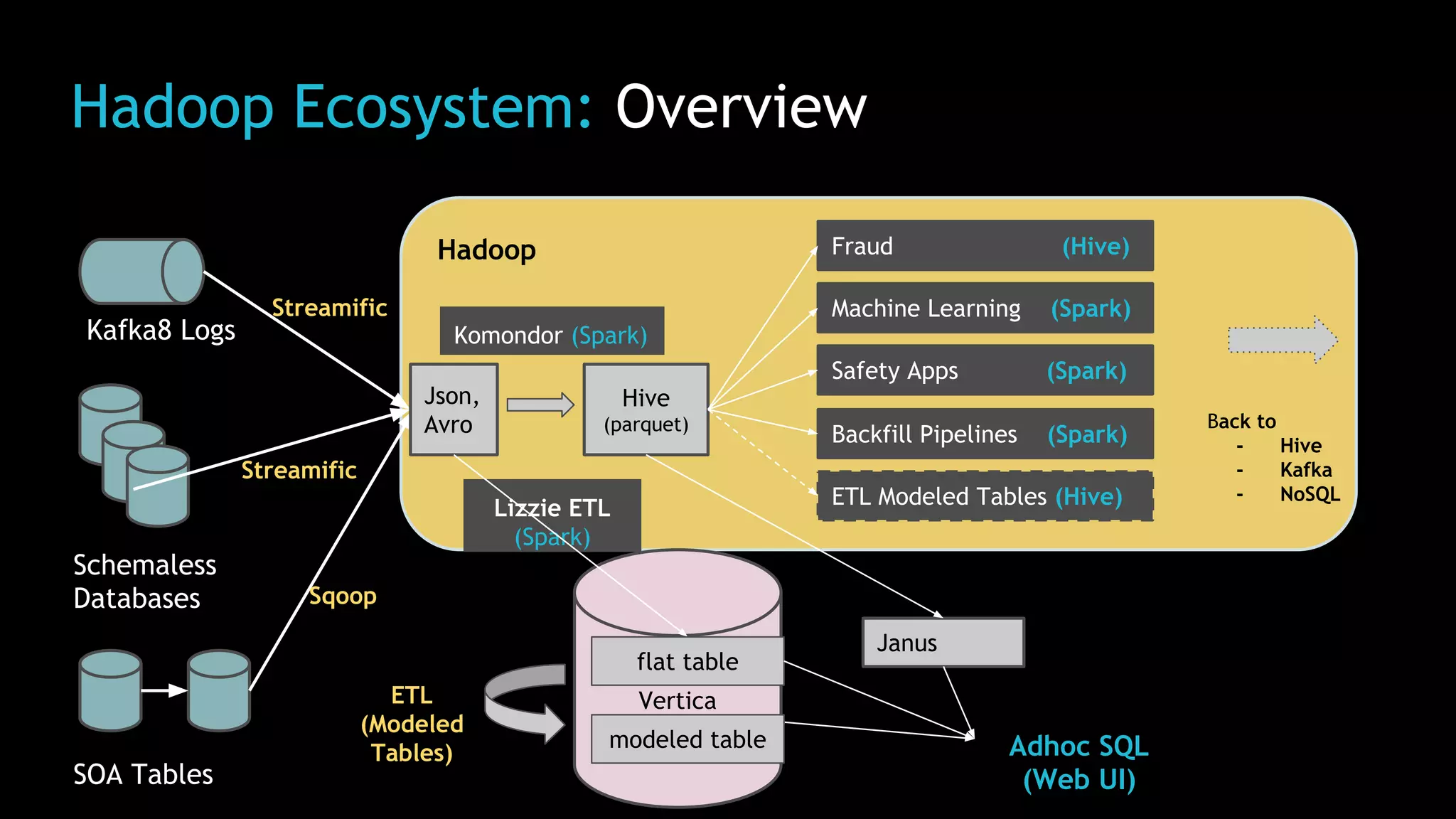
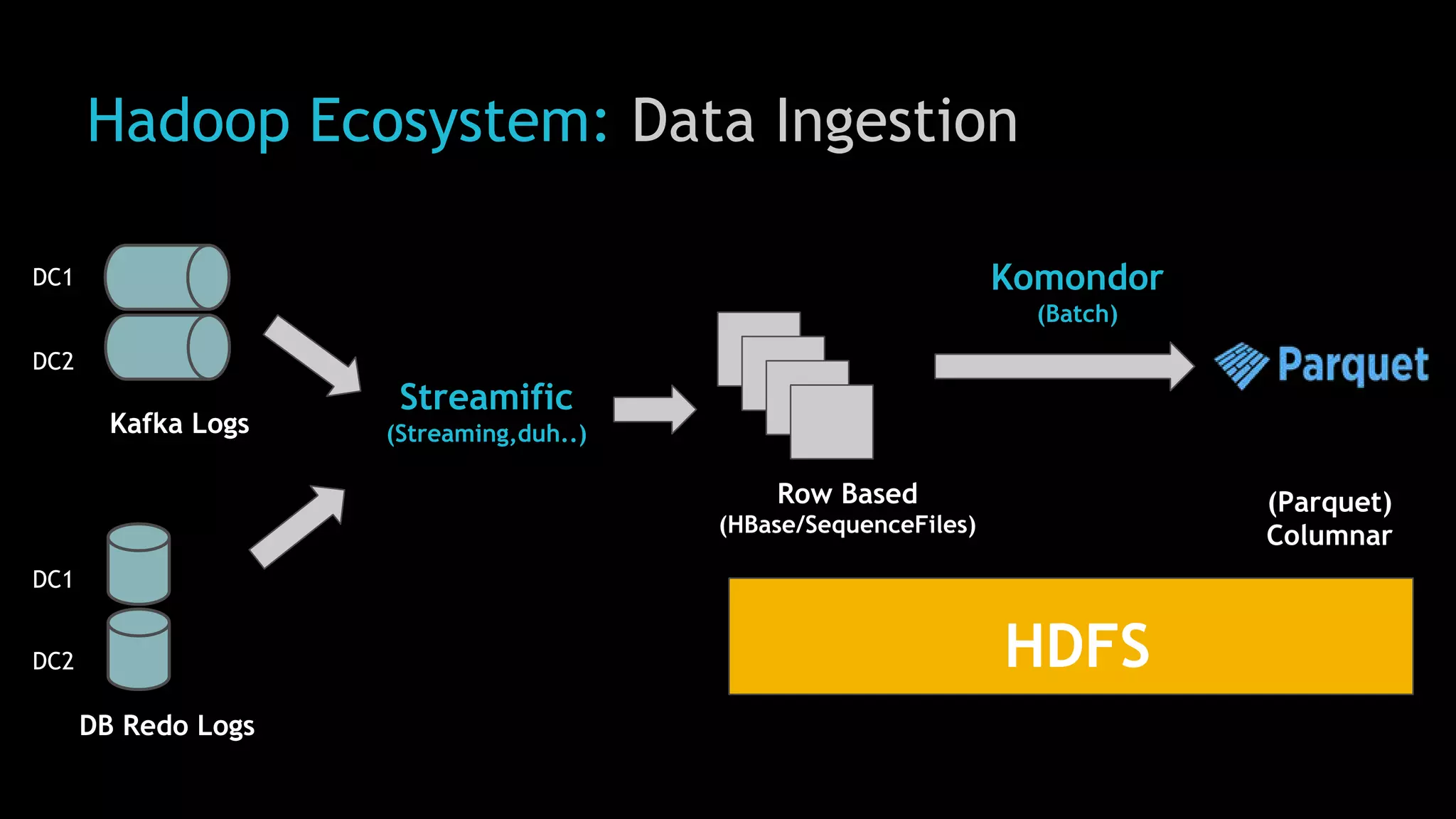
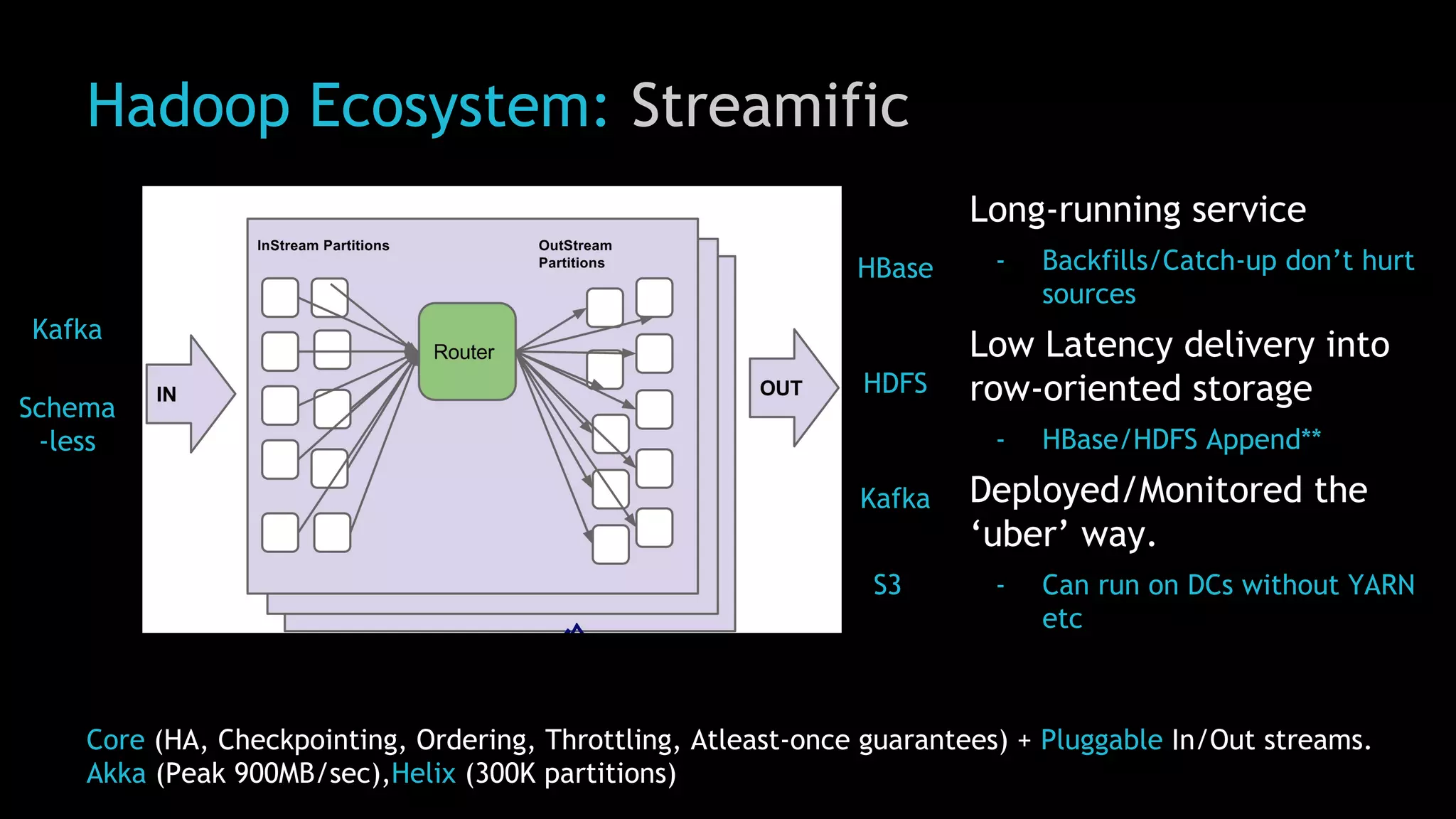












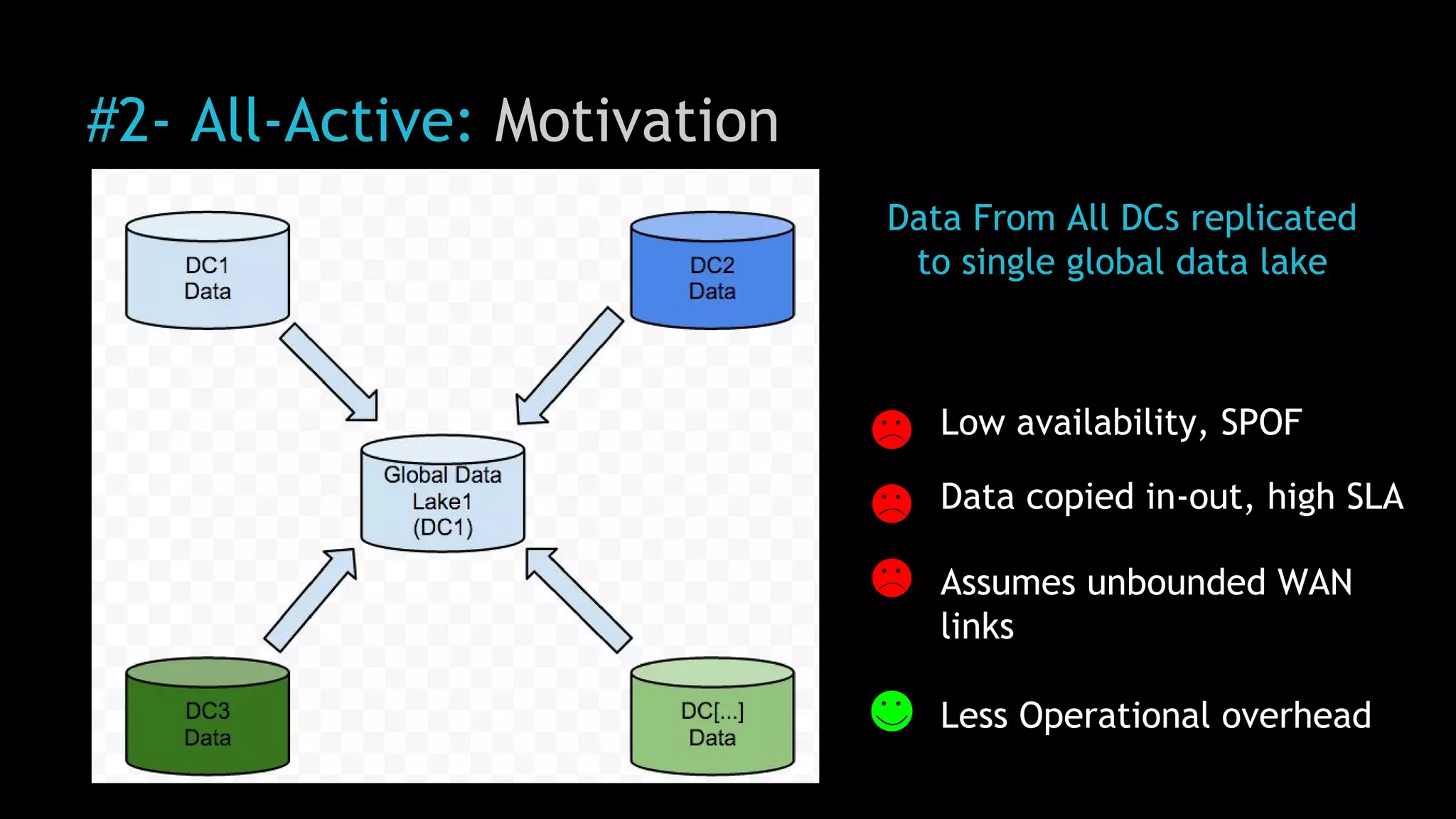
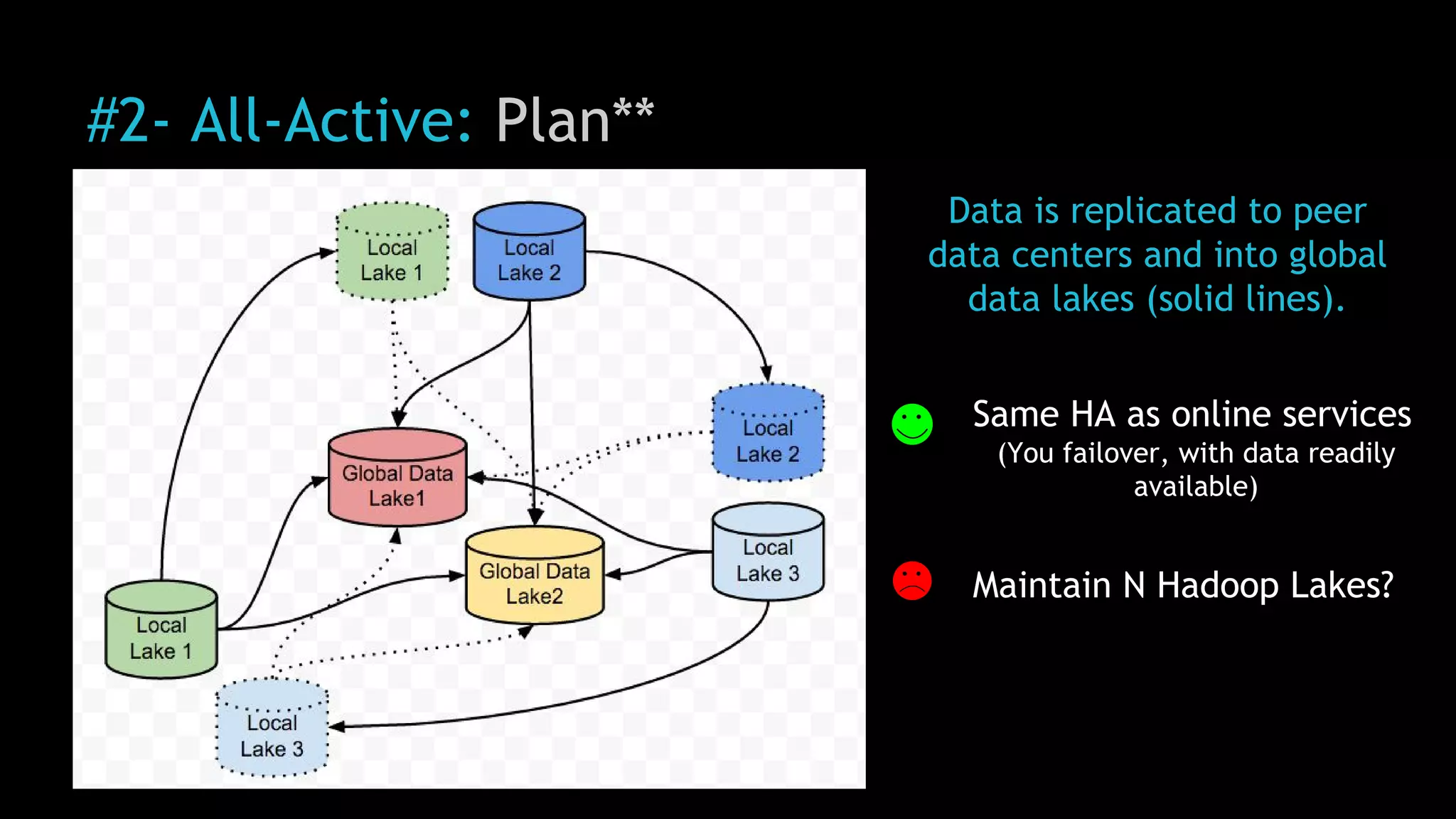



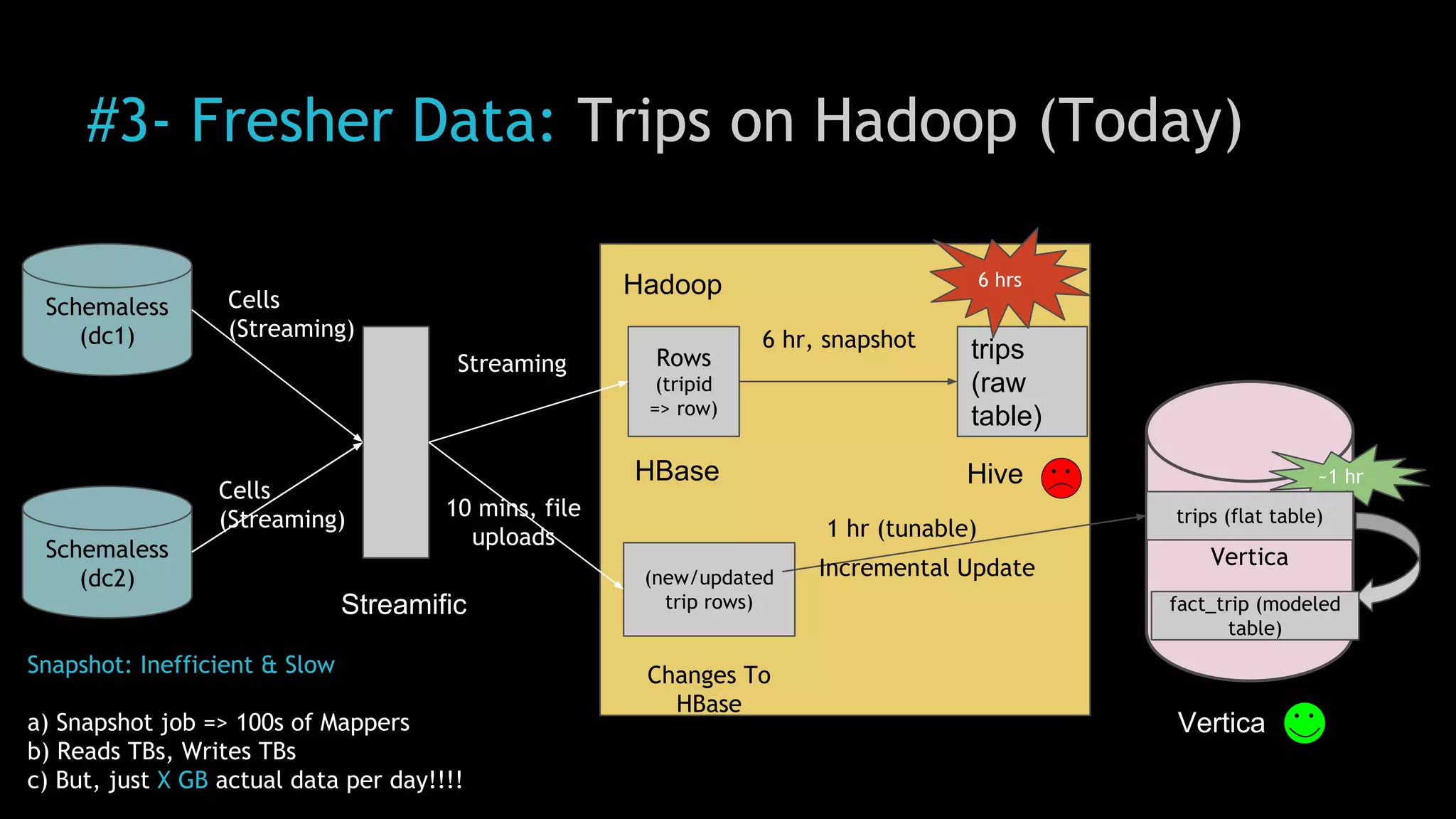
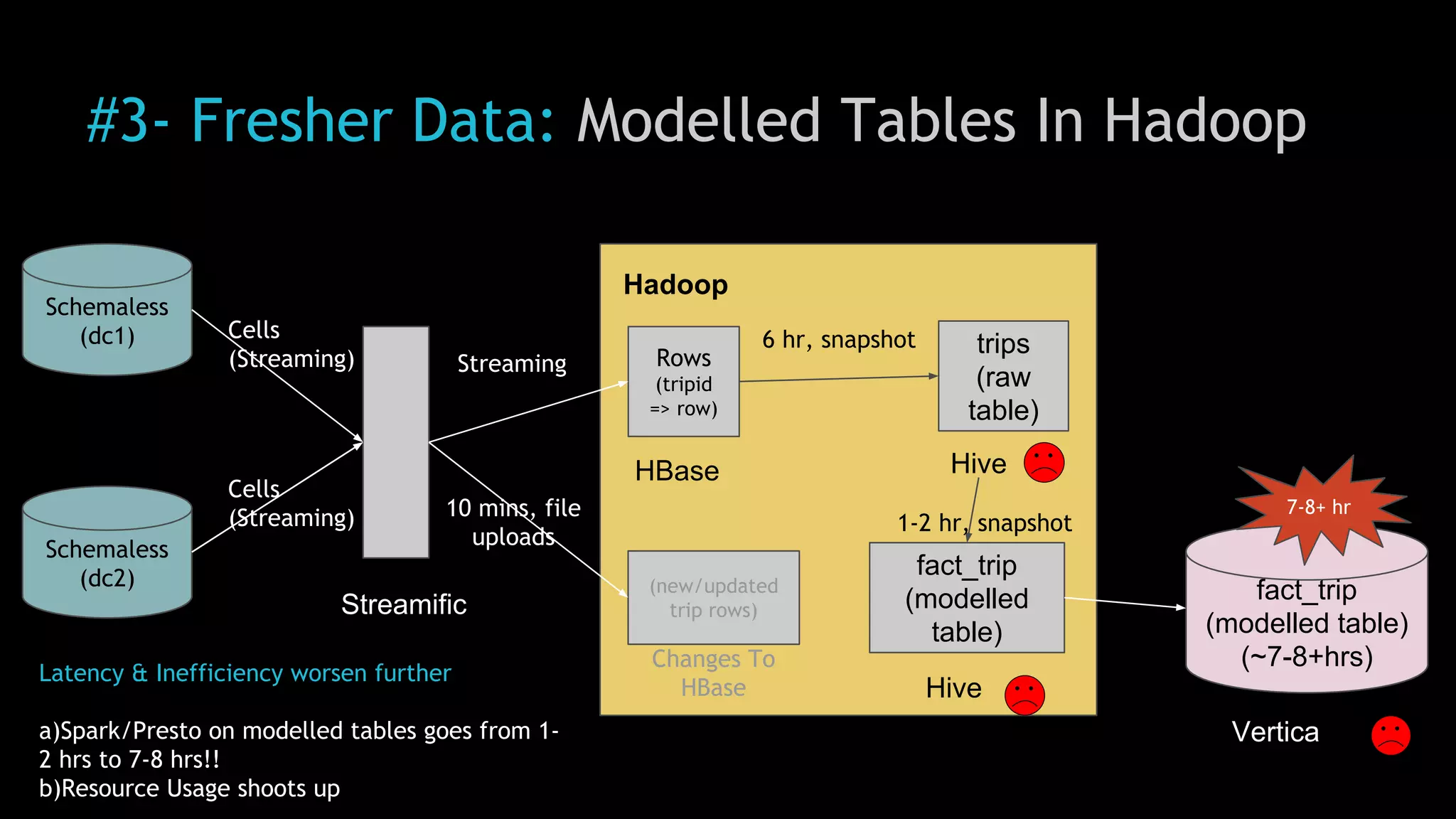
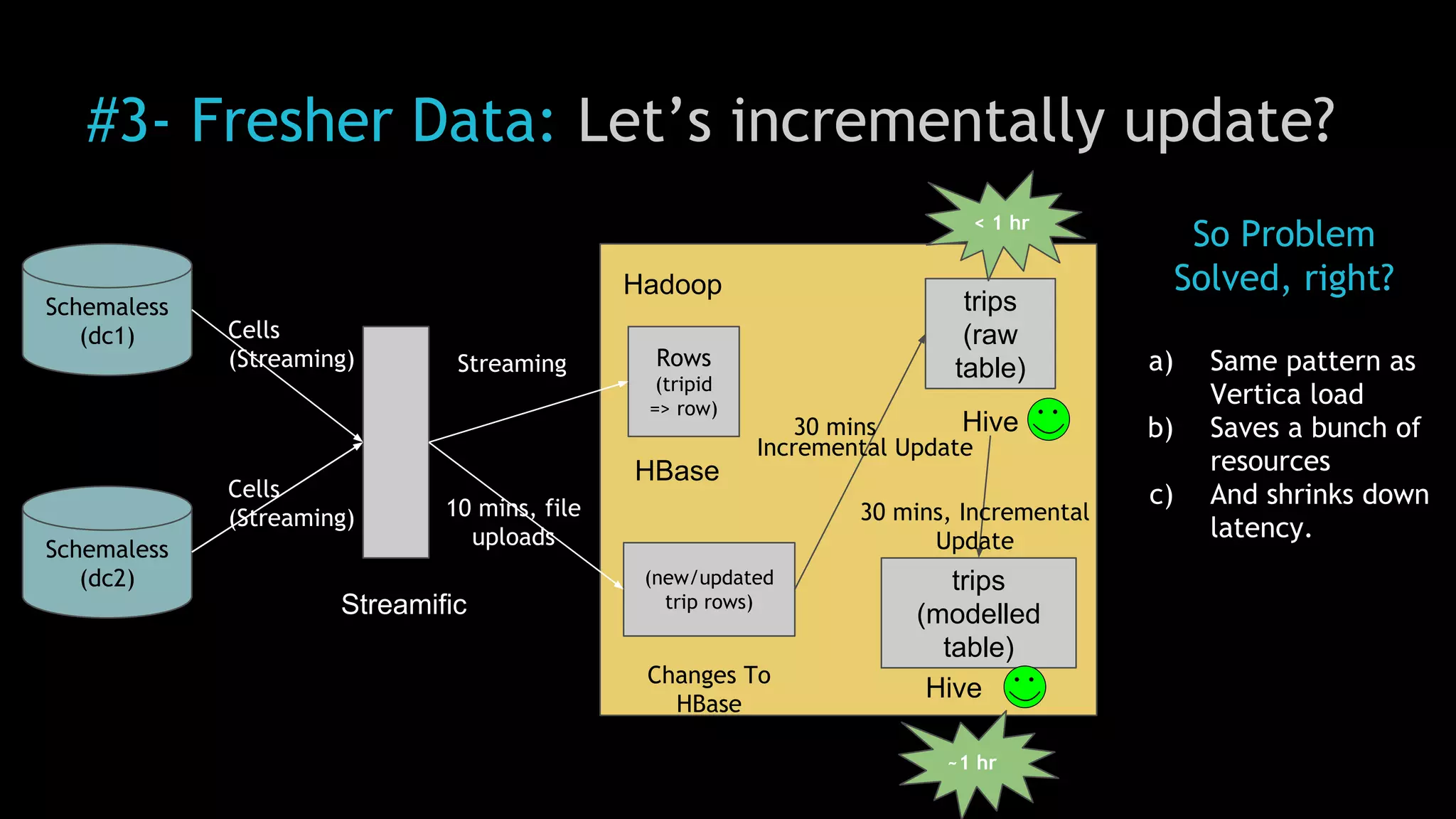
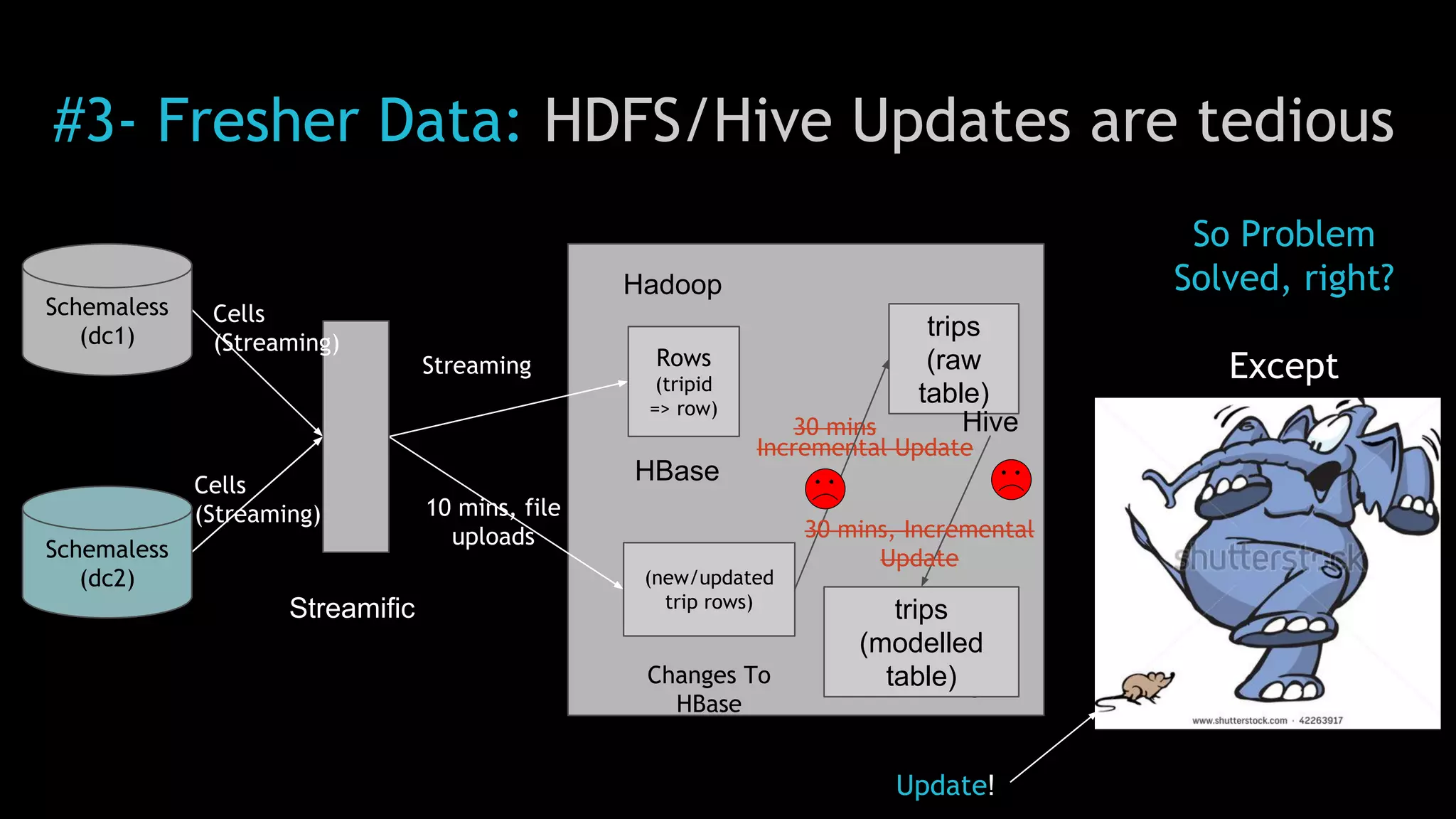
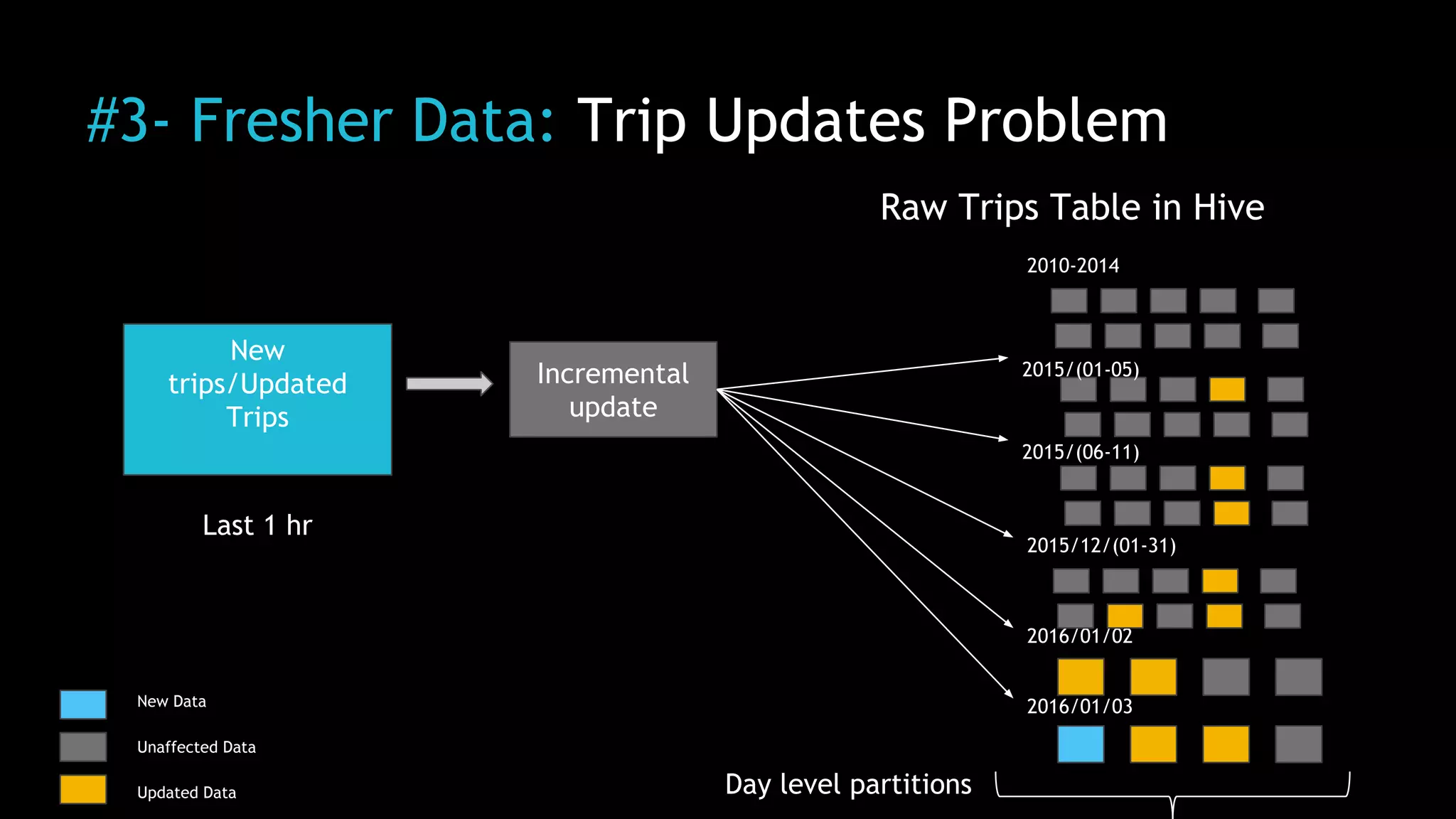
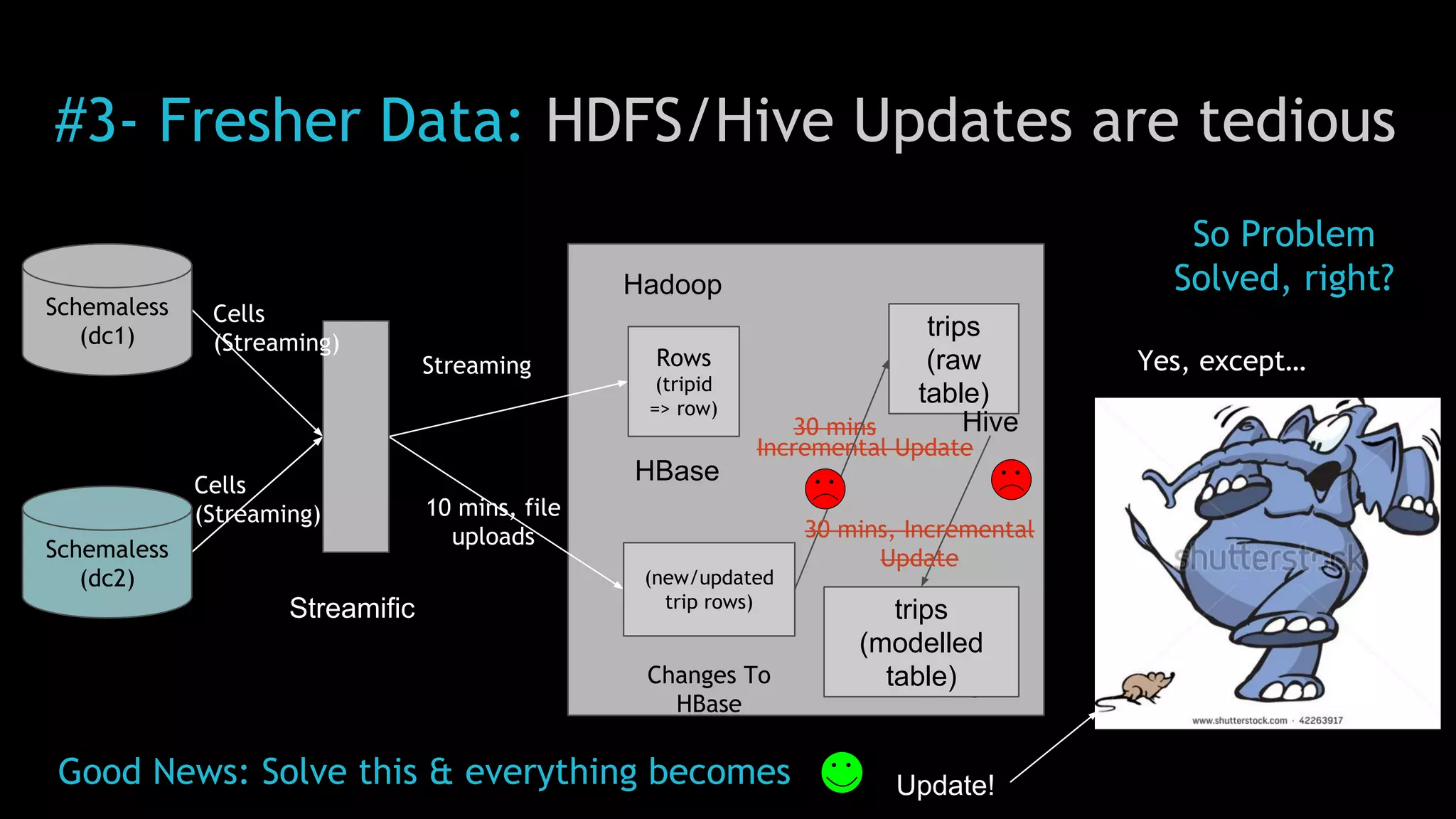




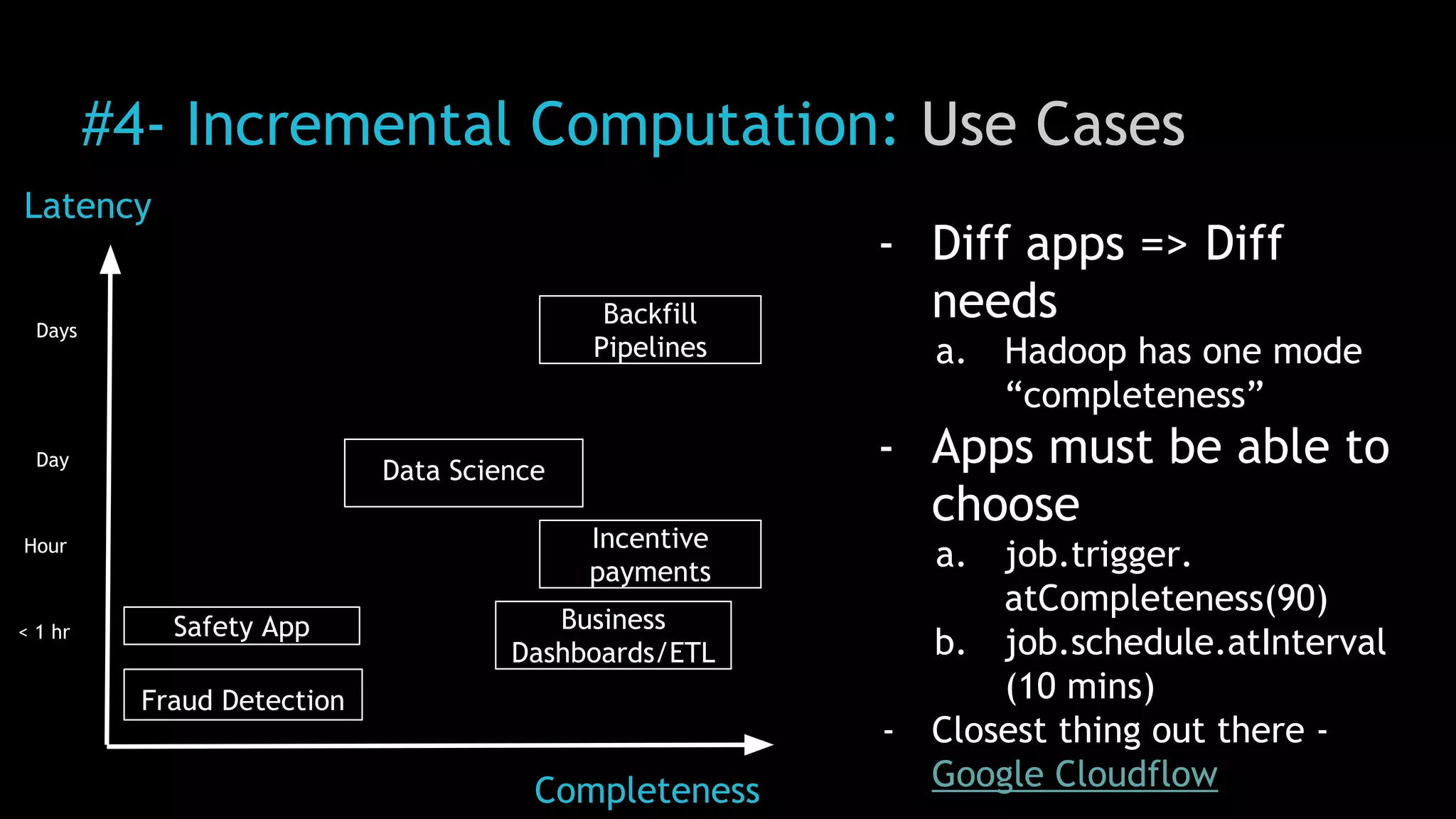






The document discusses Uber's use of Hadoop to store and analyze large amounts of data. Some key points: 1) Uber was facing challenges with data reliability, system scalability, fragile data ingestion, and lack of multi-DC support with its previous data systems. 2) Uber implemented a Hadoop data lake to address these issues. The Hadoop ecosystem at Uber includes tools for data ingestion (Streamific, Komondor), storage (HDFS, Hive), processing (Spark, Presto) and serving data to applications and data marts. 3) Uber continues to work on challenges like enabling low-latency interactive SQL, implementing an all-active architecture for high availability, and reducing




































































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)


























