Download as PDF, PPTX







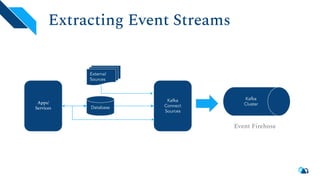
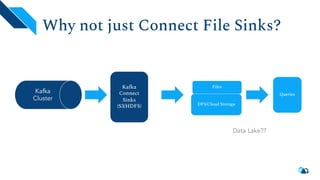





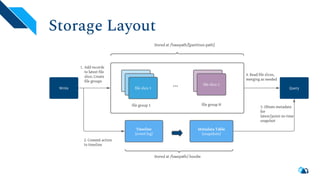


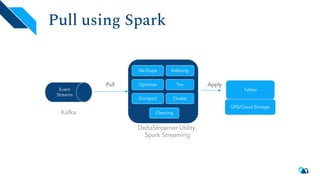
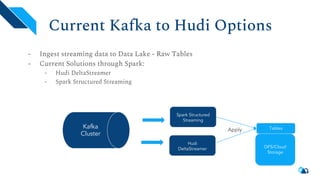



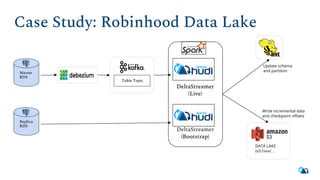


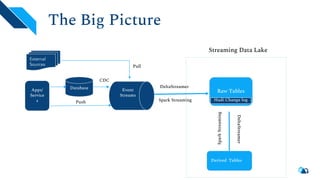


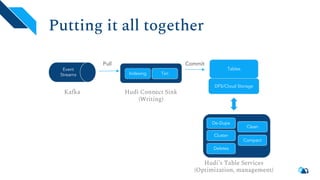

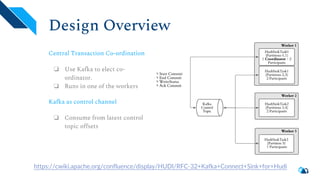
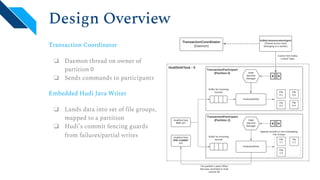
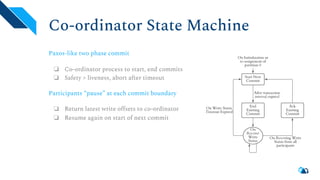

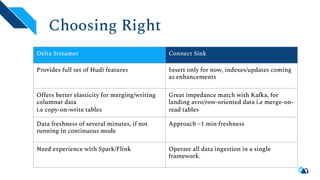





The document discusses the architecture and implementation of streaming data lakes using Kafka Connect and Apache Hudi. It covers the importance of data lakes in modern analytics, the functionality and advantages of Hudi for managing data streams and transactional writes, and a case study of Robinhood's data lake solution. Key features, usage examples, and community engagement avenues are also presented to facilitate adoption and integration of Hudi in streaming infrastructures.




























![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)











![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)


![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)











































