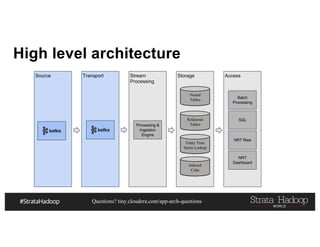
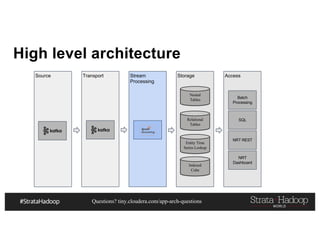
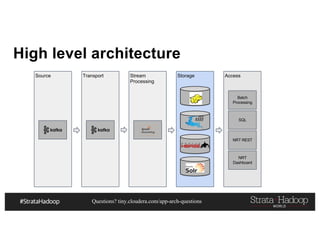
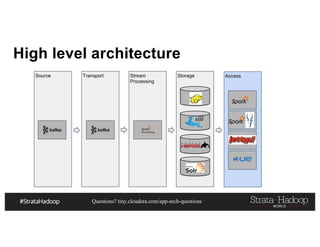
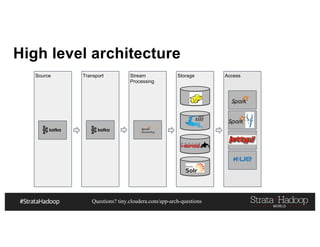
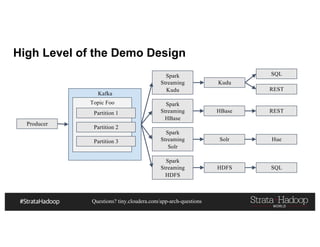
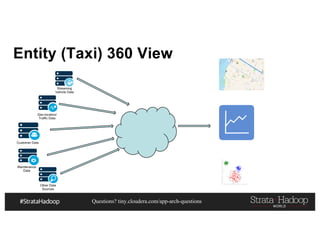
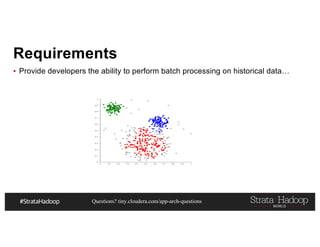
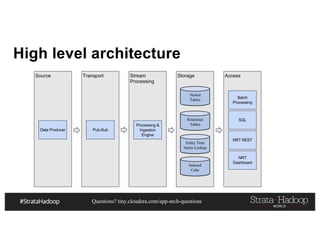
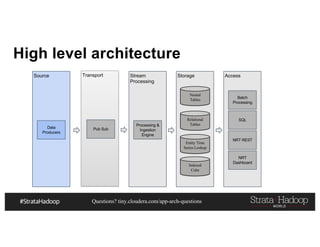
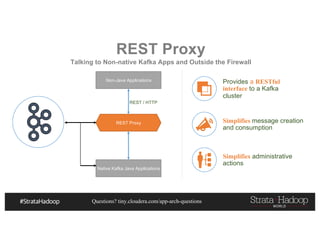
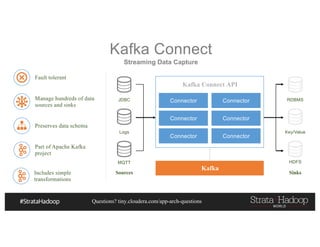
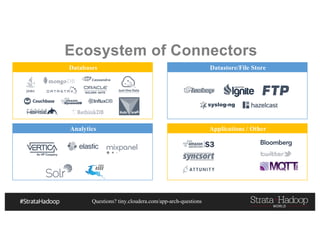
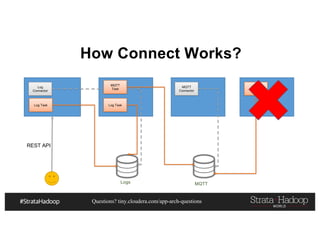
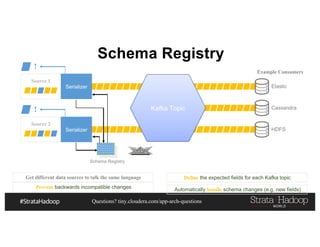
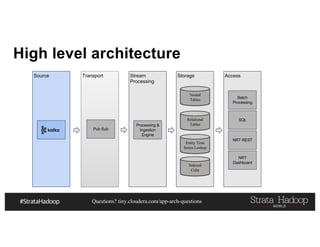
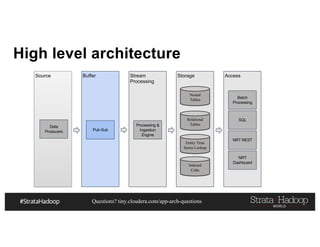
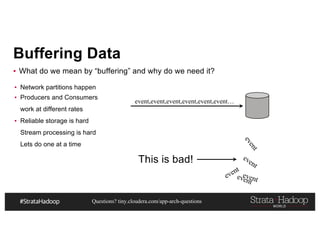
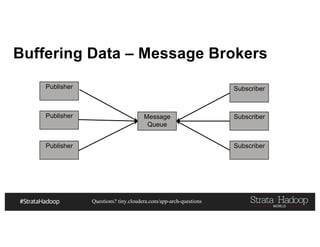
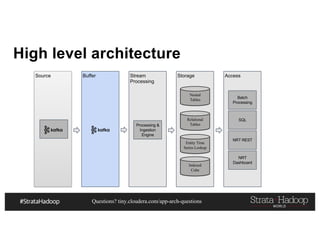
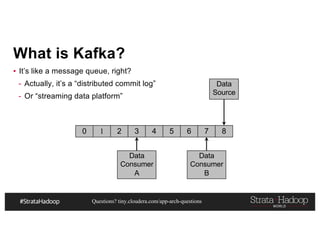
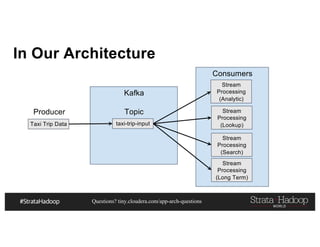
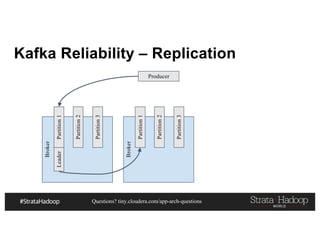
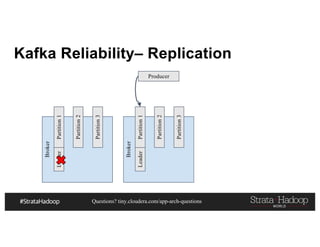
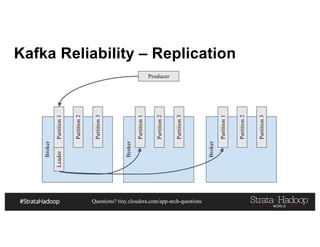
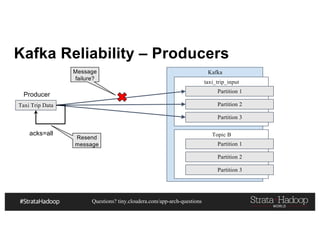
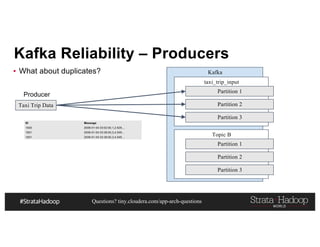
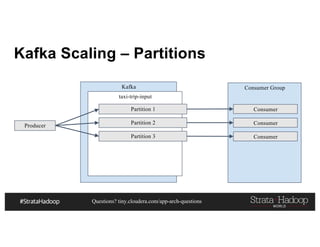
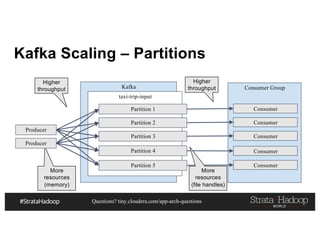
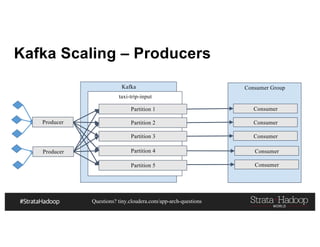
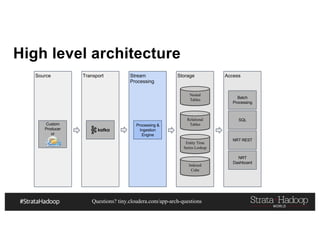
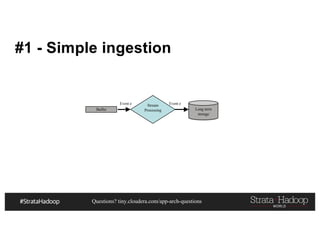
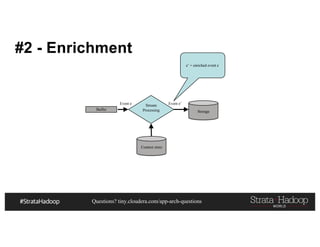
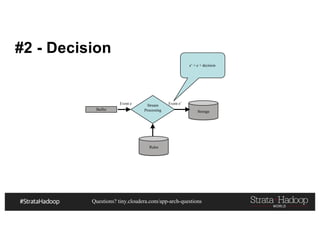
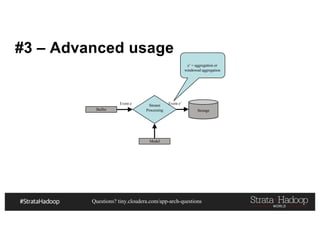
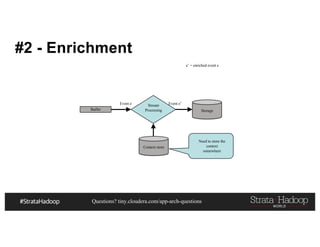
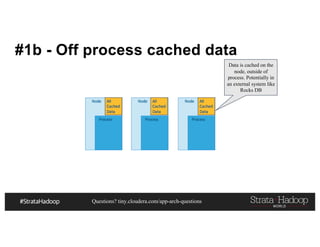
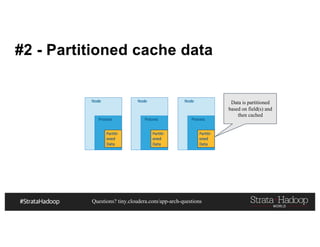
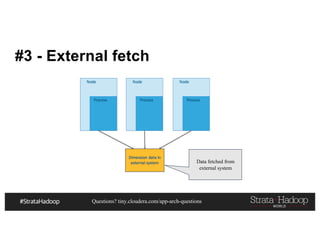
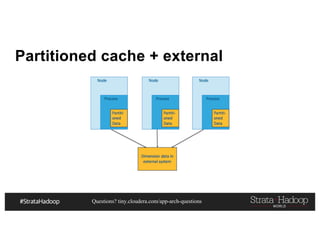
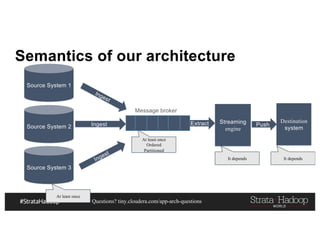
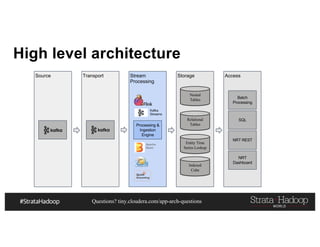
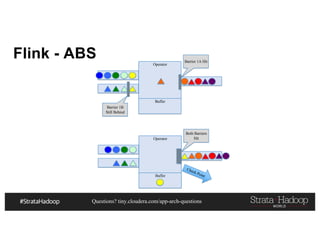
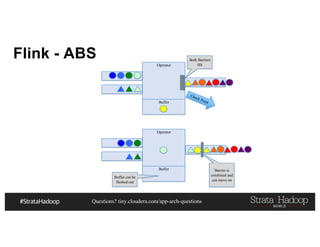
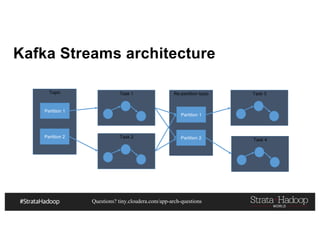
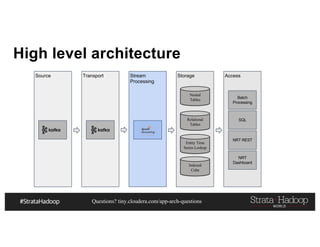
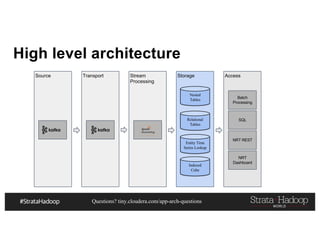
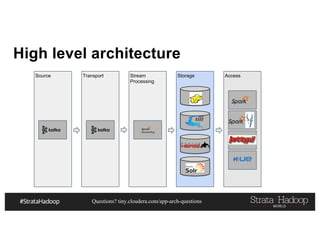
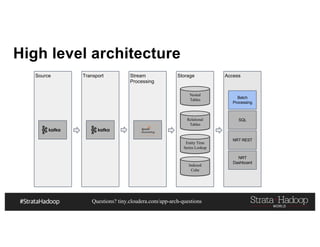
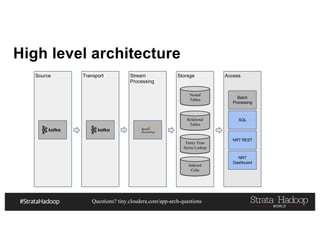
This document discusses a presentation on architecting Hadoop application architectures for a next generation data platform. It provides an overview of the presentation topics which include a case study on using Hadoop for an Internet of Things and entity 360 application. It introduces the key components of the proposed high level architecture including ingesting streaming and batch data using Kafka and Flume, stream processing with Kafka streams and storage in Hadoop.































































![Questions? tiny.cloudera.com/app-arch-questions
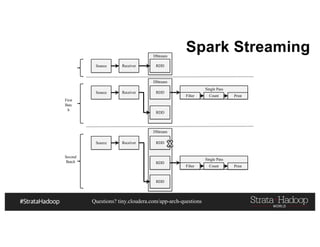
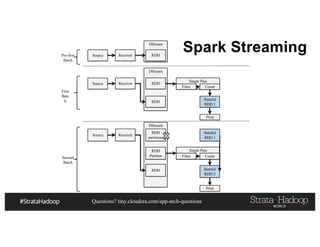
Nested Writing Example in Spark
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devil's Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5007", "type": "Powdered Sugar" },
{ "id": "5006", "type": "Chocolate with Sprinkles" }
]](https://image.slidesharecdn.com/pdf-170314172155/85/Architecting-a-Next-Generation-Data-Platform-119-320.jpg)




![Questions? tiny.cloudera.com/app-arch-questions
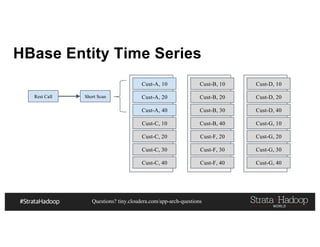
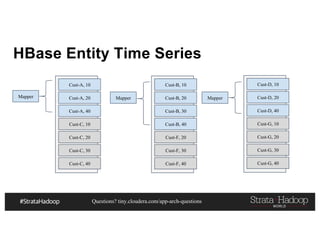
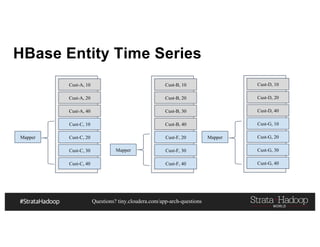
HBase: Row Key Example
def generateRowKey(customerTrans: CustomerTran, numOfSalts:Int): Array[Byte] = {
val salt = StringUtils.leftPad(
Math.abs(customerTrans.customerId.hashCode % numOfSalts).toString, 4, "0")
Bytes.toBytes(salt + ":" +
customerTrans.customerId + ":" +
StringUtils.leftPad(customerTrans.eventTimeStamp.toString, 11, "0") + ":trans:" +
customerTrans.transId)
}](https://image.slidesharecdn.com/pdf-170314172155/85/Architecting-a-Next-Generation-Data-Platform-127-320.jpg)



















![Questions? tiny.cloudera.com/app-arch-questions
Don’t believe me?
import org.mortbay.jetty.Server
import org.mortbay.jetty.servlet.{Context, ServletHolder}
…
val server = new Server(port)
val sh = new ServletHolder(classOf[ServletContainer])
sh.setInitParameter("com.sun.jersey.config.property.resourceConfigClass",
"com.sun.jersey.api.core.PackagesResourceConfig")
sh.setInitParameter("com.sun.jersey.config.property.packages",
"com.hadooparchitecturebook.taxi360.server.hbase")
sh.setInitParameter("com.sun.jersey.api.json.POJOMappingFeature", "true”)
val context = new Context(server, "/", Context.SESSIONS)
context.addServlet(sh, "/*”)
server.start()
server.join()](https://image.slidesharecdn.com/pdf-170314172155/85/Architecting-a-Next-Generation-Data-Platform-151-320.jpg)
![Questions? tiny.cloudera.com/app-arch-questions
Then, write a ServiceLayer
@GET
@Path("vender/{venderId}/timeline")
@Produces(Array(MediaType.APPLICATION_JSON))
def getTripTimeLine (@PathParam("venderId") venderId:String,
@QueryParam("startTime") startTime:String = Long.MinValue.toString,
@QueryParam("endTime") endTime:String = Long.MaxValue.toString):
Array[NyTaxiYellowTrip] = {](https://image.slidesharecdn.com/pdf-170314172155/85/Architecting-a-Next-Generation-Data-Platform-152-320.jpg)