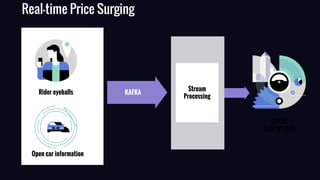
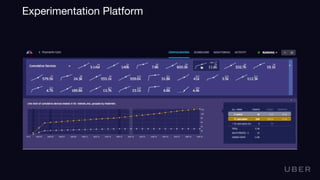
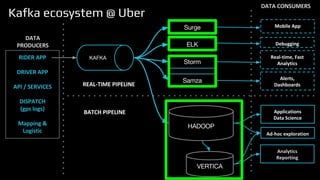
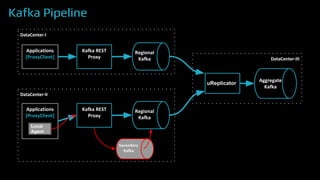
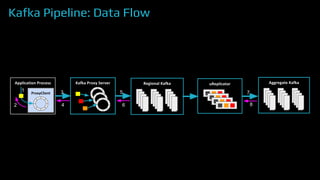
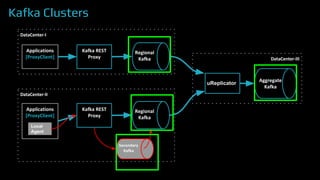
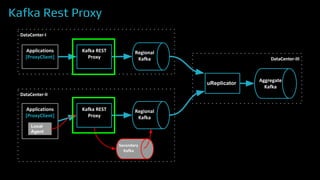
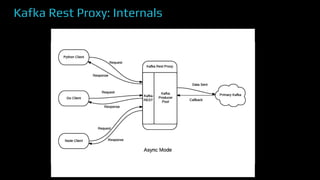
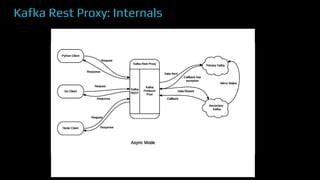
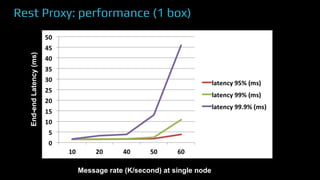
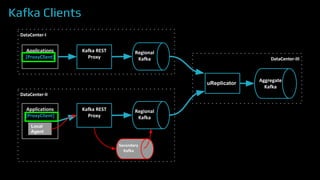
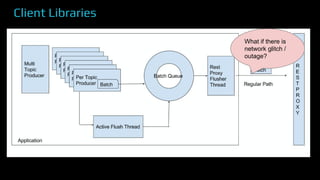
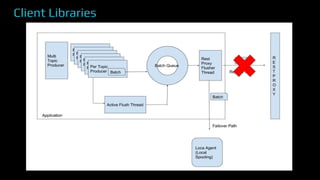
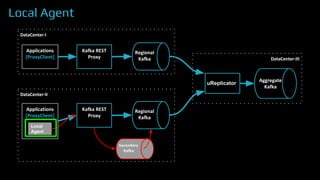
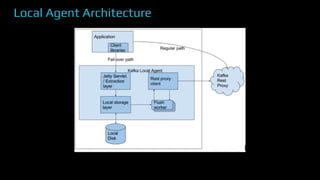
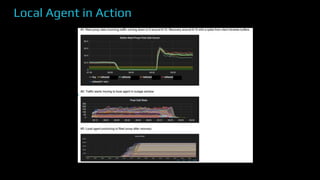
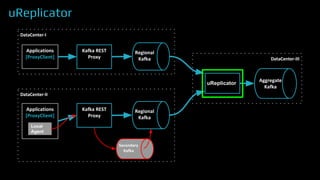
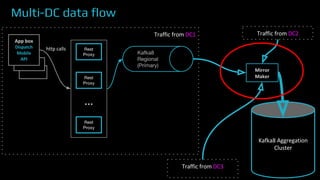
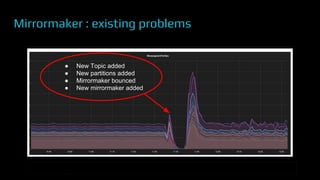
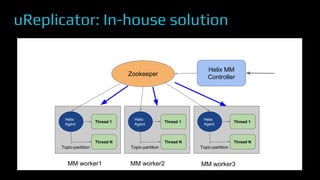
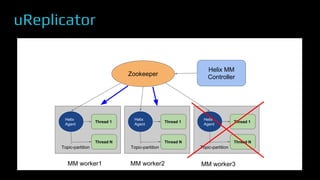
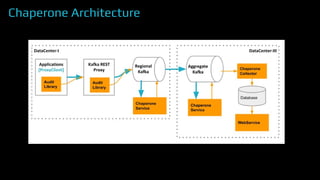
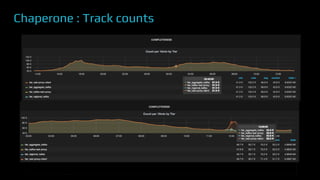
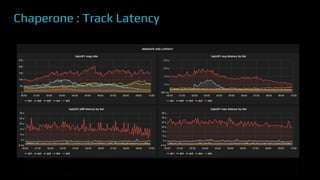
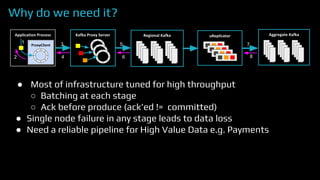
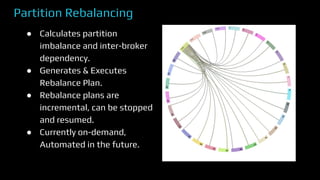
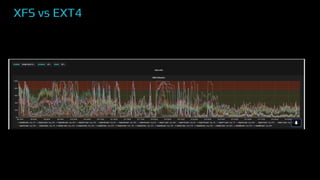
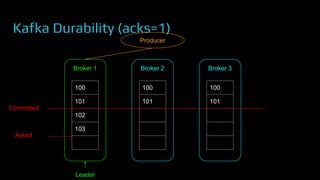
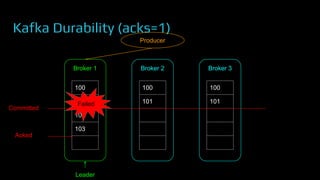
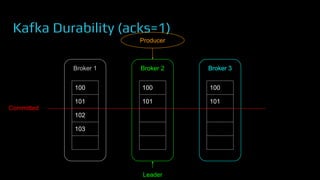
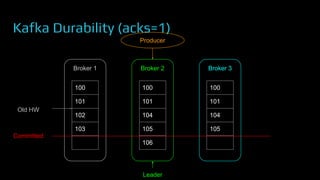
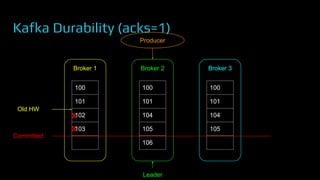
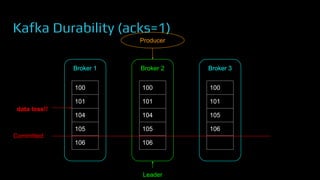
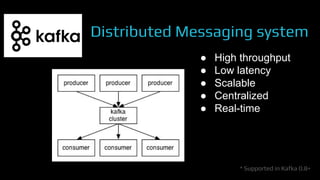
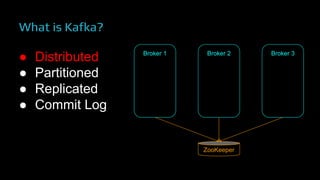
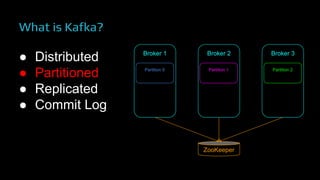
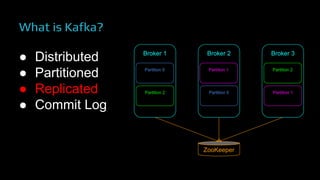
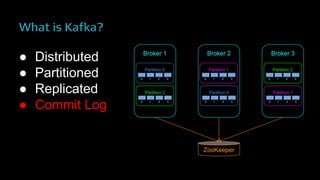
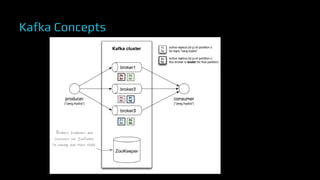
The document provides an overview of real-time data analytics at Uber, focusing on the Kafka infrastructure and its applications for high throughput and low latency processing. It highlights the significant scaling requirements and the development of various tools, including a REST proxy, ureplicator, and local agent to enhance reliability and performance. The presentation emphasizes Kafka's vital role in handling hundreds of billions of messages daily while ensuring reliability and supporting numerous clients across multiple data centers.