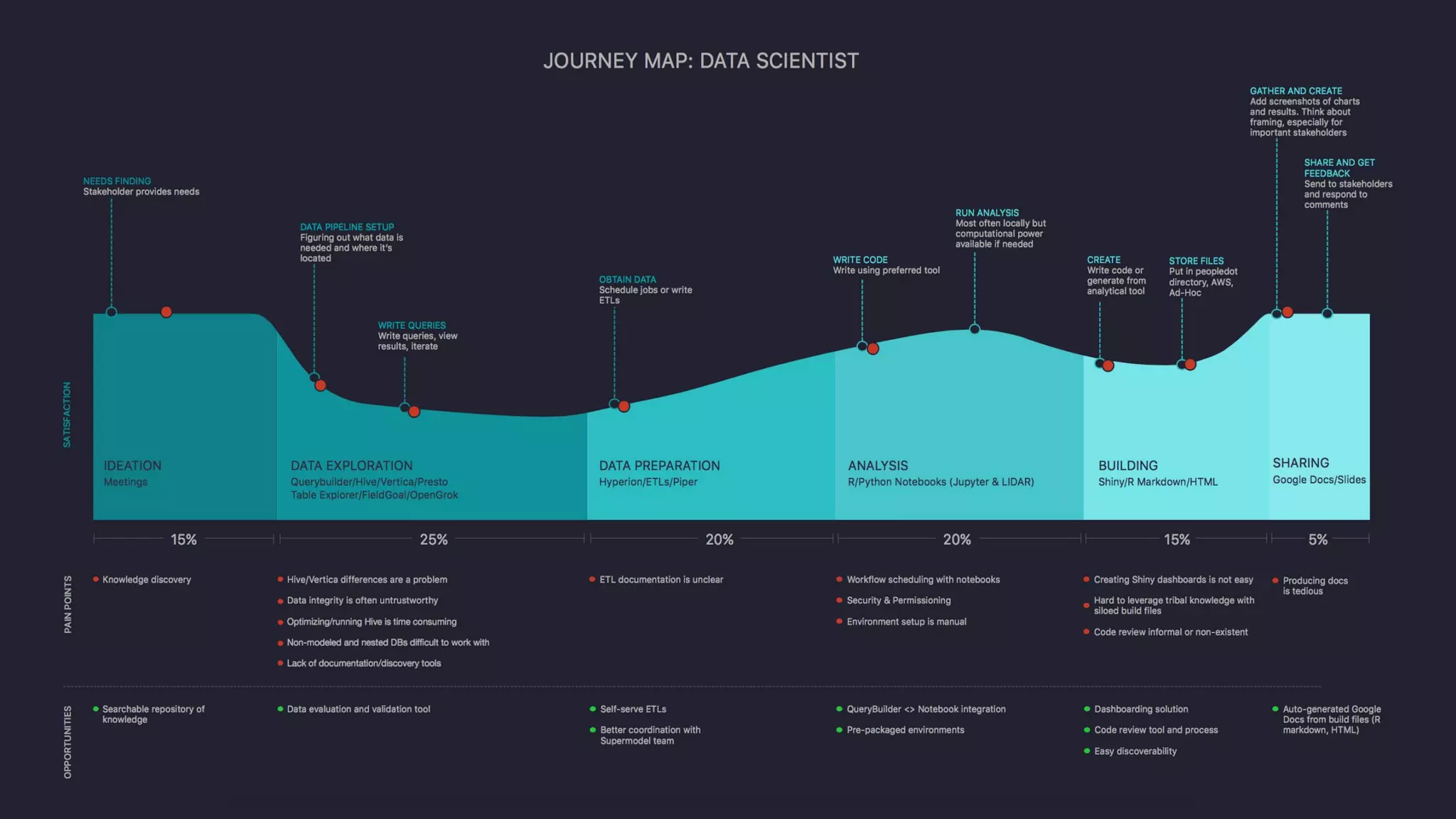
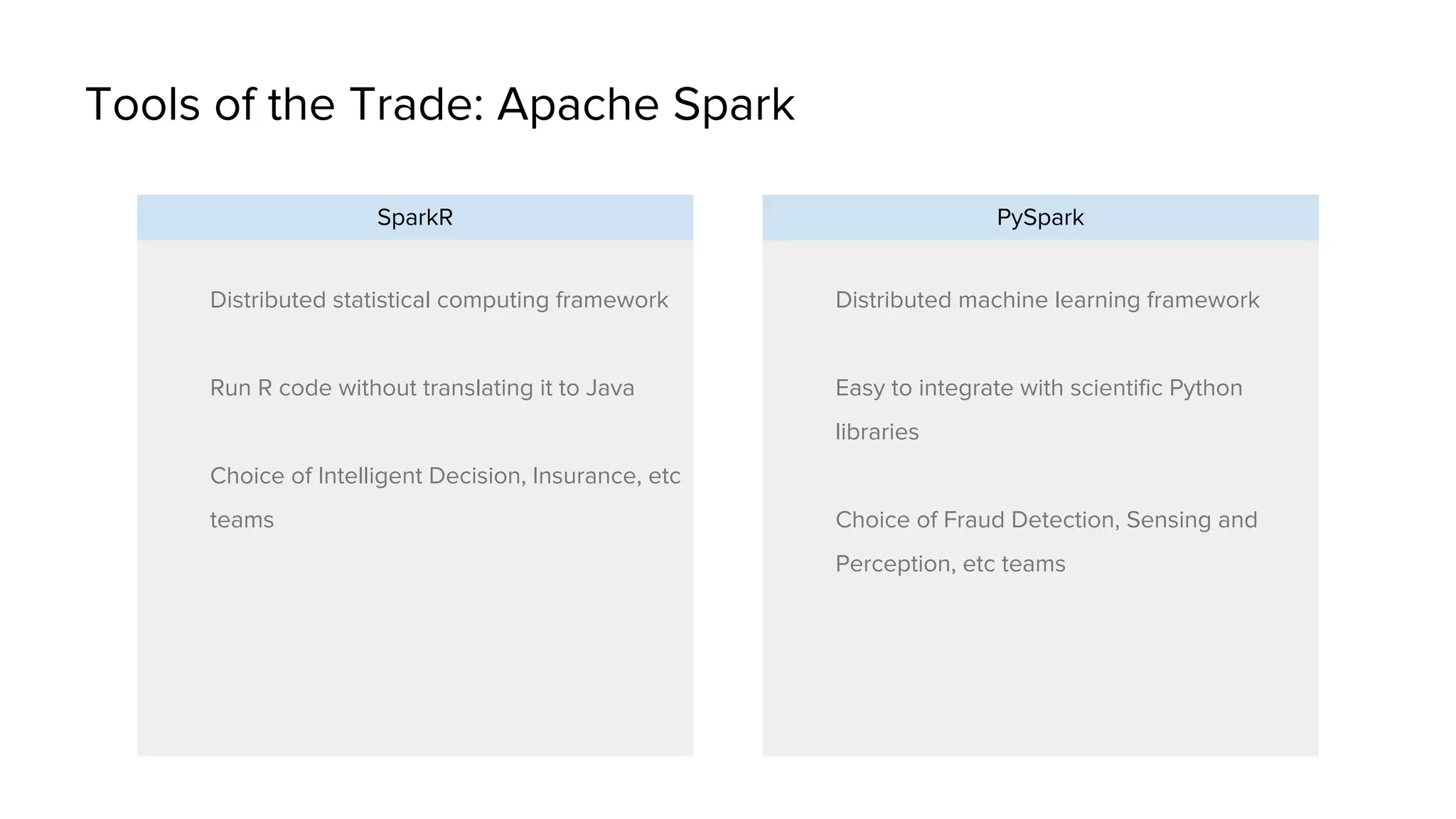
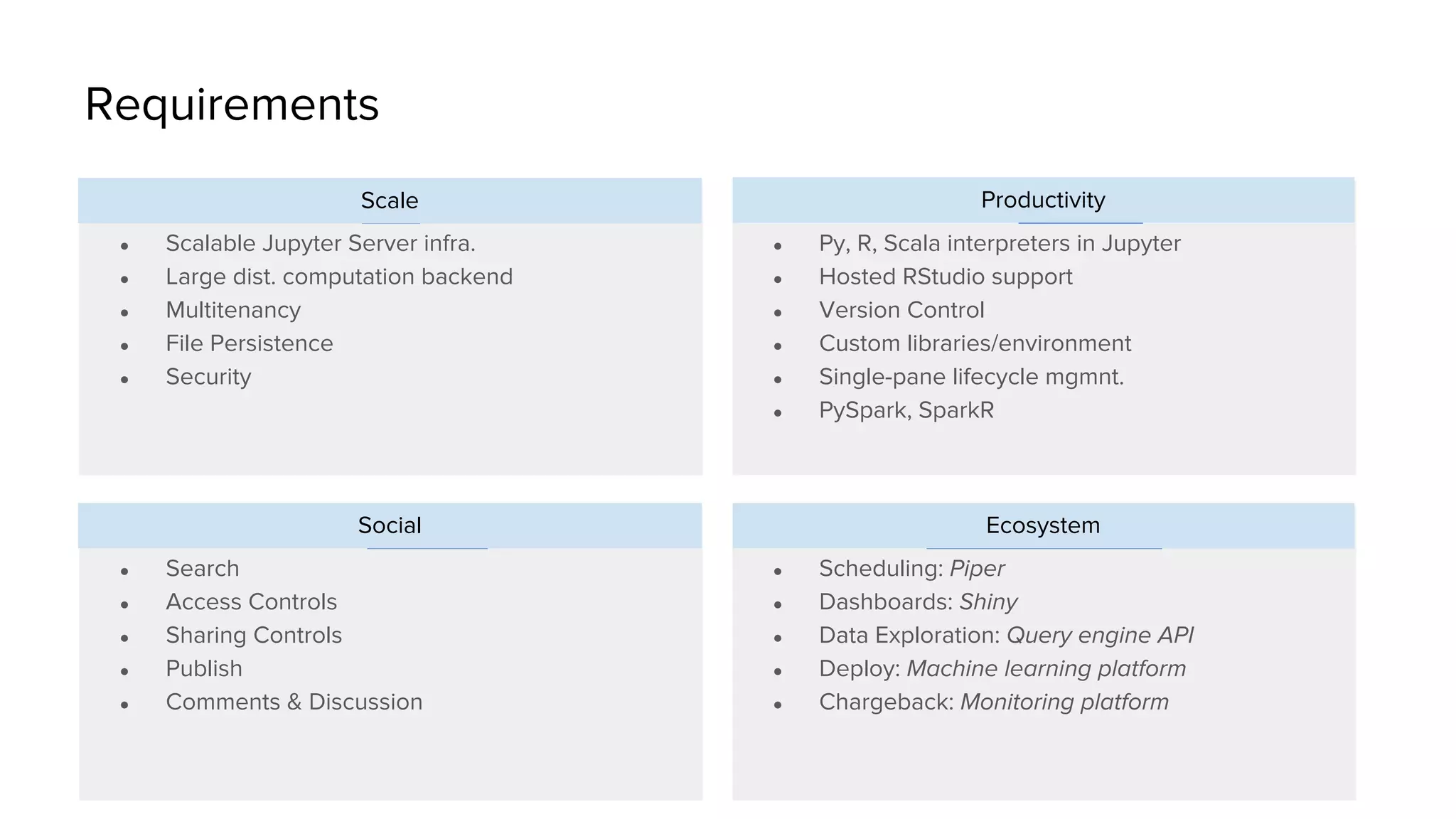
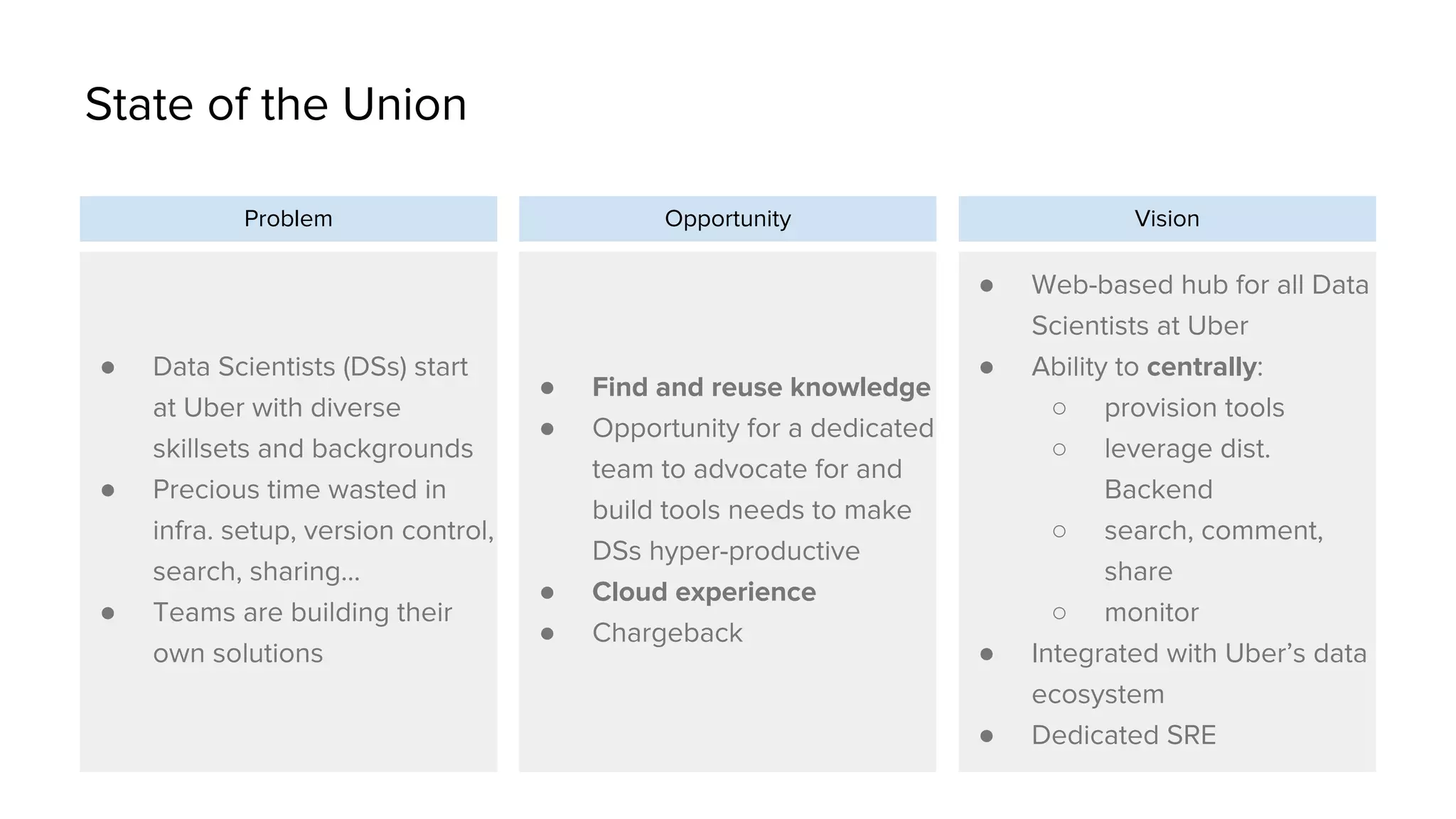
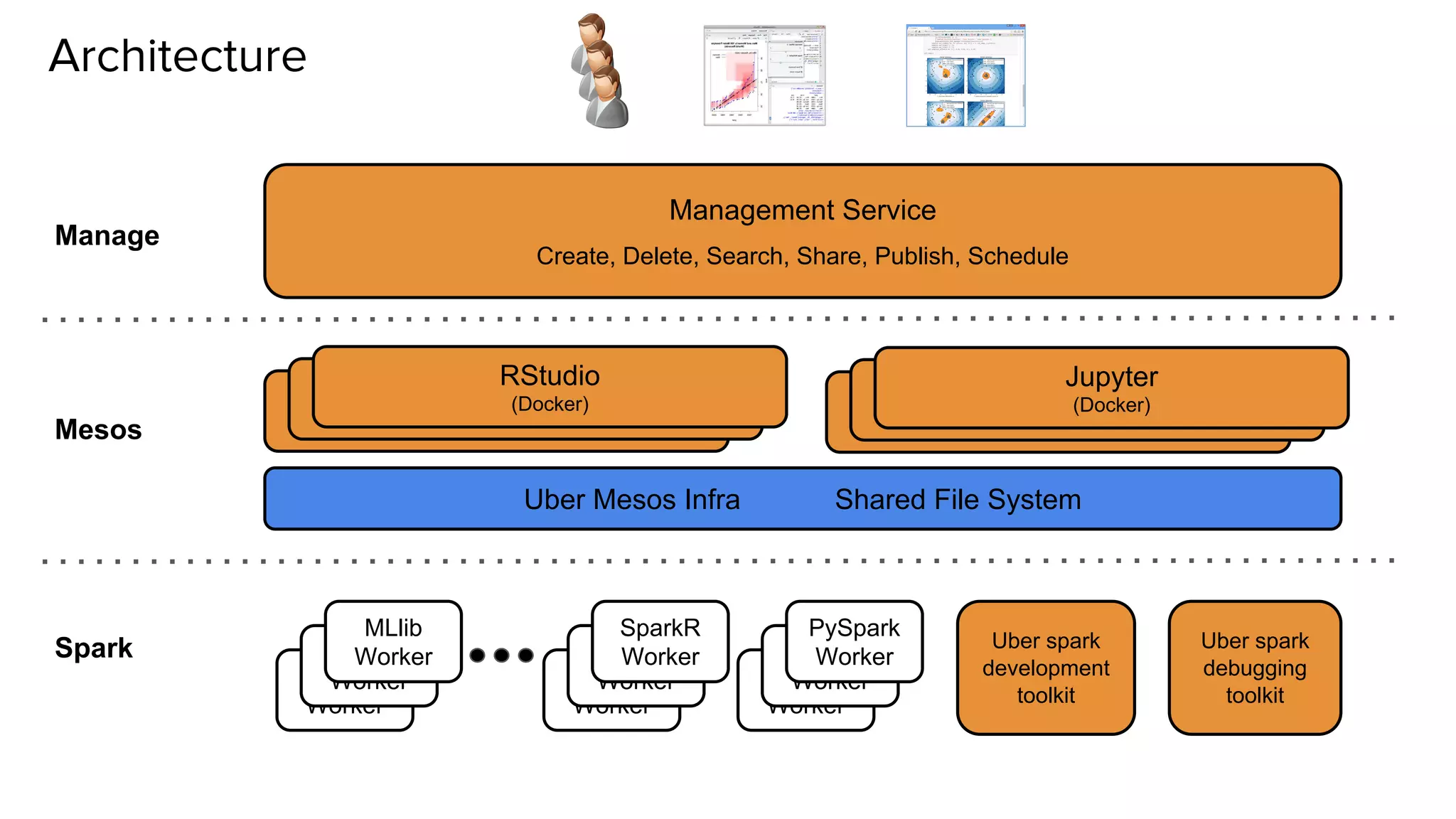
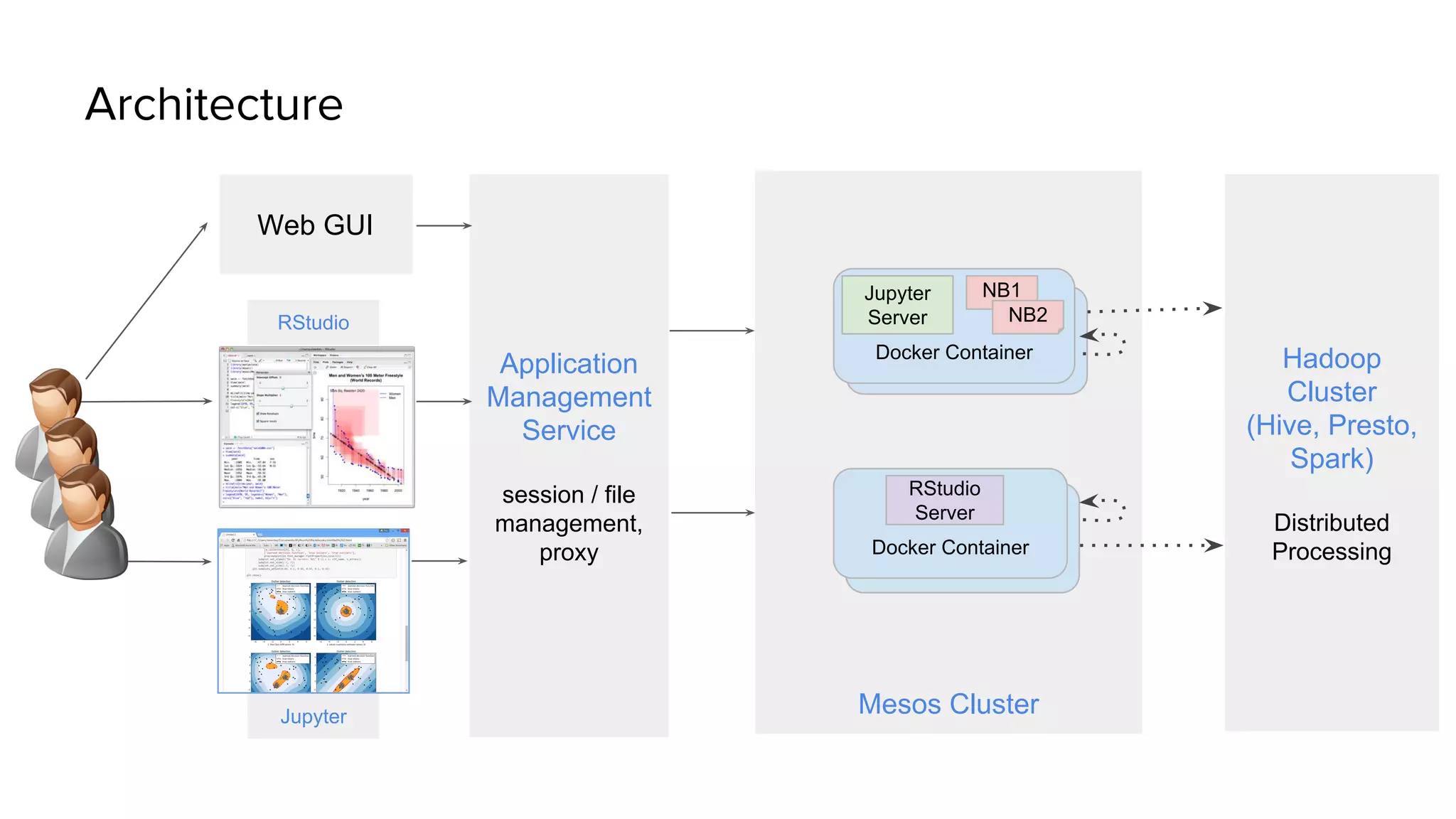
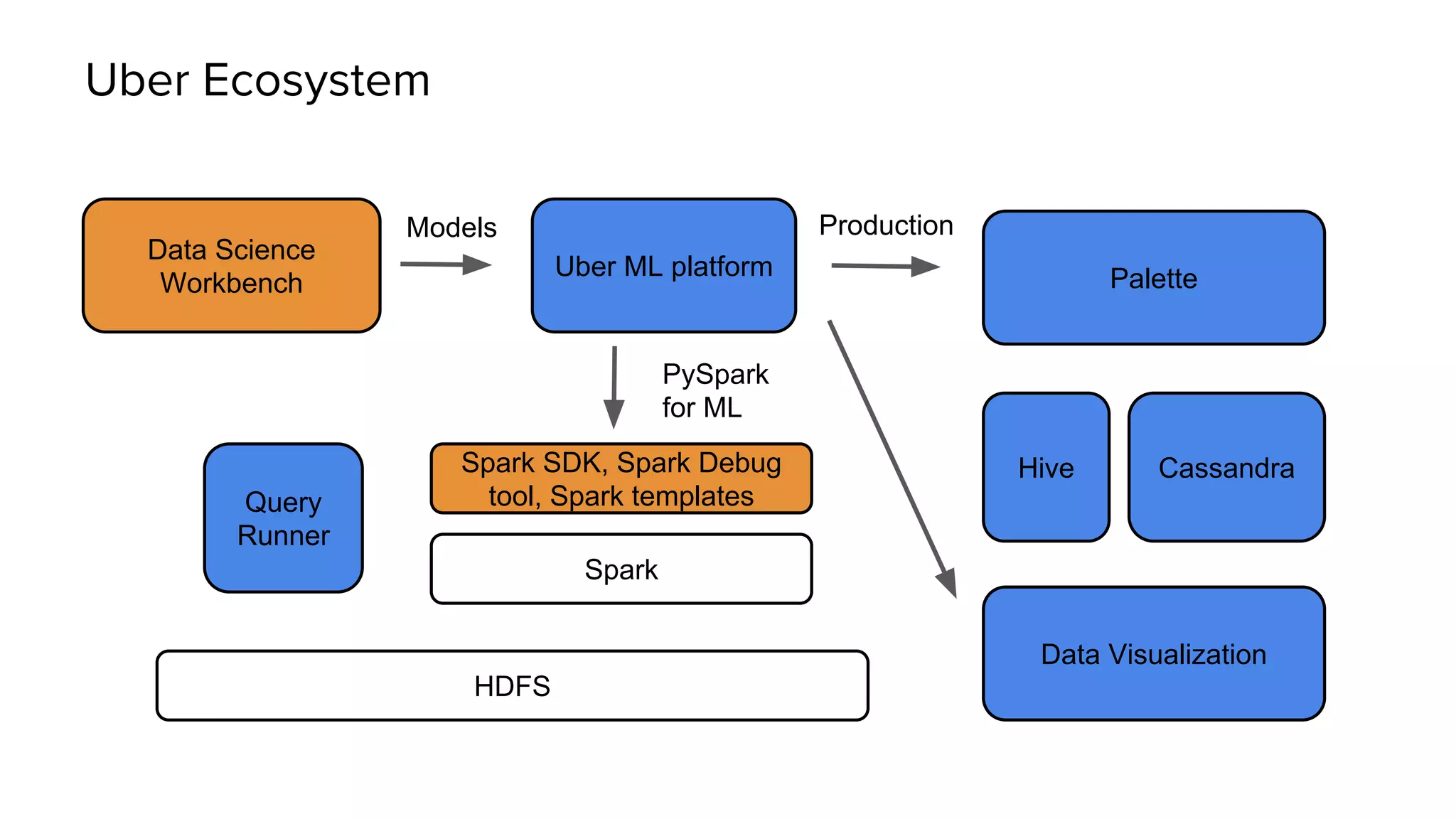
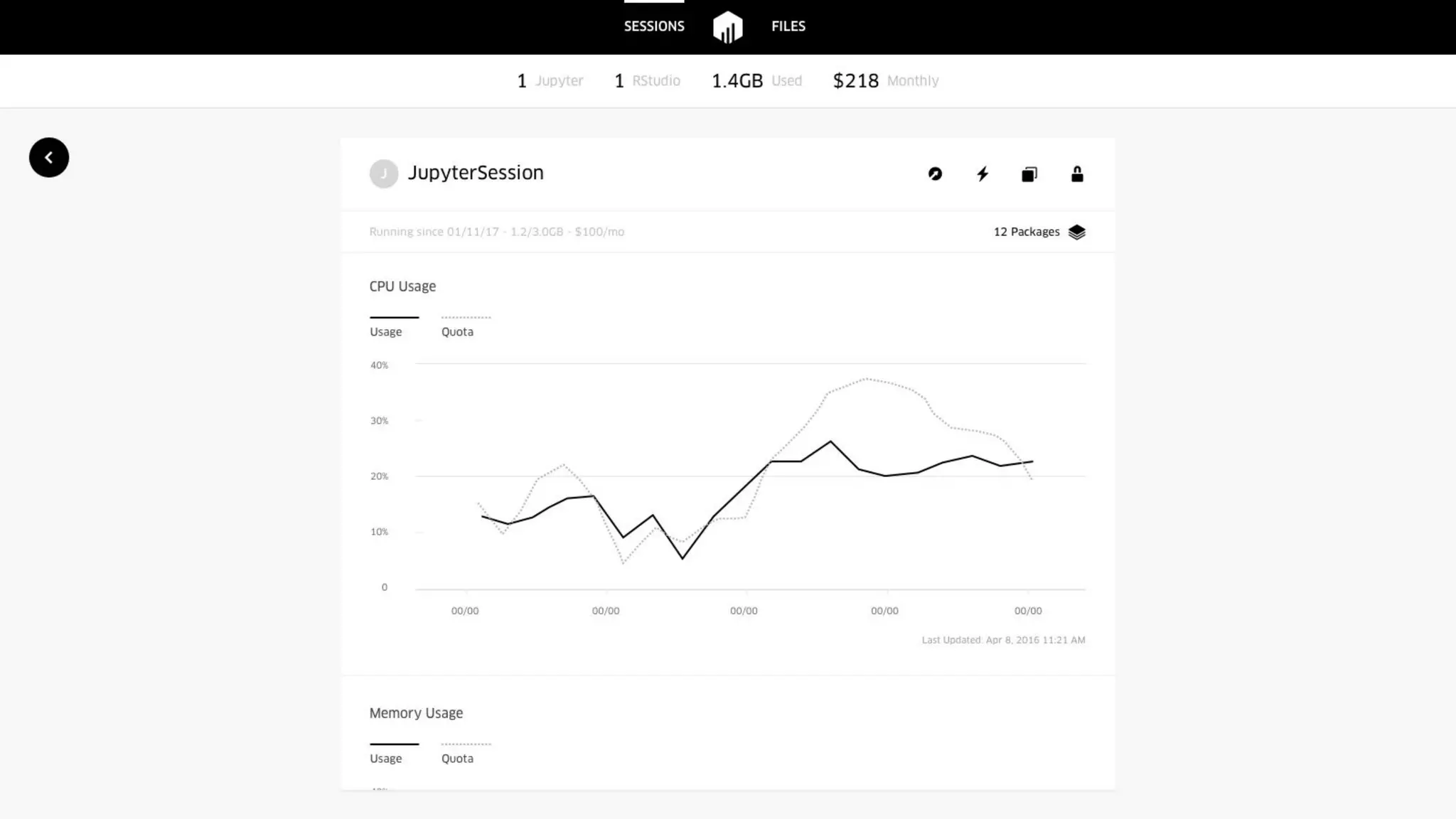
Uber has created a Data Science Workbench to improve the productivity of its data scientists by providing scalable tools, customization, and support. The Workbench provides Jupyter notebooks for interactive coding and visualization, RStudio for rapid prototyping, and Apache Spark for distributed processing. It aims to centralize infrastructure provisioning, leverage Uber's distributed backend, enable knowledge sharing and search, and integrate with Uber's data ecosystem tools. The Workbench manages Docker containers of tools like Jupyter and RStudio running on a Mesos cluster, with files stored in a shared file system. It addresses the problems of wasted time from separate infrastructures and lack of tool standardization across Uber's data science teams.